

薛定谔的佛与深度学习中的因果
《寻梦环游记》看哭了许多人,小男孩米格踏过花瓣桥,也就踏入了既生又死的状态,出现在他眼前的,是恢弘的亡灵世界。如果人世间没有人再记得,骷髅人也将在亡灵世界烟消云散,这是人存在的本来景象吗?玛雅人祭奠的圣井,真的是通往亡灵世界的入口吗?玛雅人是不是已然到达了传说中的梵境?
紧跟着玛雅人到达梵境的,是现在的一批90后。《第一批90后已经出家了》称,办公室的90后已经找到人生的新方向,宣布成佛,“有也行,没有也行,不争不抢,不求输赢”,这是真真正正的梵境,是物我两忘、无生无死、无真无假的量子存在。这已经无限接近薛定谔心目中的生命体验(life):“......‘我’这个人,如果有,那依照自然规律控制了‘原子运动’”;“我”的定义并非是经历体验的收集,而“在收集它们的画布之上”;如果催眠师能成功遮闭所有早期记忆,就没有个人存在性的损失——“也将不曾有是”。这也是印度教意义上的佛。
统计学家眼中的佛
这些表述出现在薛定谔1944年出版的书《What is Life?》,薛定谔说,生命是由负熵喂养大的,后来更正为,自由能才是生命的源泉。薛定谔眼里的生命就是一团活生生的自由能,也是普里高津世界里,不断获取自由能的开放的耗散结构。他既是《人民日报》鼓励年轻人做的、不屈不挠的“斗战胜佛”, 也是悲悯众生、大慈大悲的观世音菩萨。而统计学家眼里的佛,却应该是这条神秘的钟形曲线。
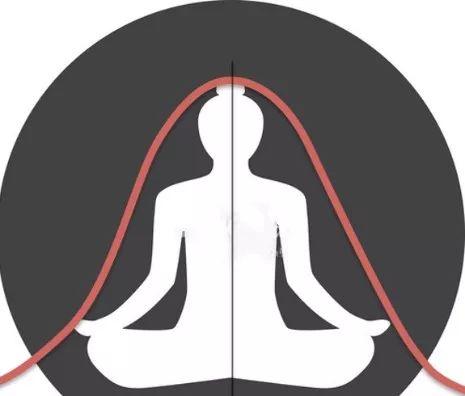
没错,这个神秘的钟形,就是伟大的高斯分布,她是佛的身姿,无时不有,又无处不在。中心极限定理(Central Limit Theorem)告诉我们,即使你不能描述单一的随机事件的发生,大量这些单一随机事件的群体行为却服从高斯分布。高尔顿设计了一个钉板实验,切实验证了这条曲线,并从统计的观点解释了生物遗传现象;1994年美国畅销书《钟形曲线》(The Bell Curve)则根据大量测试数据,得出东亚人智商最高的客观的结论;不一而足。这或许就是“一花一世界,一叶一如来”的统计学解释。
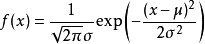
高斯曲线有着优美的身形,无处不在的神秘感,还有着倔强的性格:打碎了,揉烂了,被傅里叶变换了,仍然还坚持自我。两个高斯分布的独立变量 X,Y 的和 X+Y 或者差 X-Y,服从另一个高斯分布:
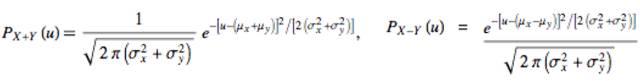
反之也成立,1936年 Cramer 证明了两个独立变量 X,Y 和(X+Y)如果服从高斯分布,则X,Y也分别服从高斯分布。
在傅里叶分析中,人们观察到,合适方差情况下,高斯分布是傅里叶变换算子的特征向量,也就是说高斯分布代表着她自己的频率分量。举个例子,如下的方程式就完美地将高斯分布与她的傅里叶变换关联。佛都是顿悟了自身的觉悟者。
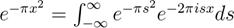
最大熵原理说:一个封闭的有固定内部能量的系统,平衡态时候熵最大;而最小能量原理则告诉我们:一个封闭的有固定熵的系统,平衡态时候能量最小。这其实是一件事情的两种不同的说法。这引出了高斯曲线更奇妙之处,她可以在给定能量的前提下,最大化系统的熵。对一瓶给定温度的气体(能量固定),研究发现某个粒子按照某个速度运动的可能性服从高斯分布。
“事物由不同层次的随机变量展现出来的信息来表达,不同层次上的随机变量携带不同的信息,共同组合影响上一层的随机变量的信息表达,而随机变量对外表达的信息则取决于该随机变量的条件概率分布”。底层的多个独立的随机变量,如果都服从高斯分布,根据上文描述的特性,可以推断,一层层堆叠构成上层的随机变量之后,仍然服从高斯分布。而这个多个独立的服从高斯分布的随机变量的堆叠过程,就是典型的高斯过程。高斯过程是高斯概率分布在随机函数空间的表现形式。
深度学习中的因果
菩萨畏因,众生畏果。NIPS 2017上,Ali Rahimi开撕,现在的深度学习是重果不重因的炼金术,Yann LeCun则反驳说:如果你吃了一个鸡蛋觉得味道不错,何必知道是哪个母鸡下的呢?!(原话不是这样的,这是笔者蹩脚的翻译)。Ali对于没有理论依据的深度学习结论的忧虑,展现出其菩萨的一面:菩萨深知因果循环,所以主张从源头上约束,也就是起心动念时都要看好,莫种恶因;LeCun与众生不识因果,若种下恶因,果报来时悔之晚矣。
Bayesian学派的解决方案看起来是更接近因果的,他们从先知后觉的Bayes推理(Bayesian Inference)入手:
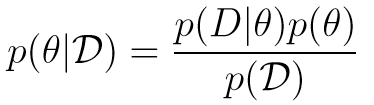
其中,p(⍬) 是在我们没有看到数据之前,一个参数的先验概率;而 p(D|⍬) 称为似然(likelihood),它是数据 D 在给定 ⍬ 情况下的概率分布。如果将Bayesian推理应用到深度神经网络中,人们就可以获取在给定训练数据集的情况下,神经网络权重 W 的后验概率分布 p(W|D) :
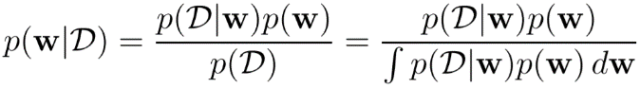
进一步,人们还可以得到神经网络输出的后验概率、不同大小的神经网路,以及这些不同的神经网络对应的输出。
如果我们再假定:p(w) 先验分布为高斯分布,训练后的目标数据也遵循高斯分布,可以推导出 p(w|D)的形式,然后最大化 p(w|D),发现其损失函数是通过权值衰减(weight decay)最小化的, 这是现代神经网络算法中优化最大似然的常见方式。于Bayesian推理而言,最大似然就是找到一组权重 w*,使得数据集 D 的出现的可能性最大:Max (p(D|w*)) 。而学习这个权重w,就是不断看到训练数据后,持续改变我们原来对权重参数的认知。
在《薛定谔的滚与深度学习中的物理》一文中,笔者整理过,最大似然方法里“似”的“然”,就是一种最低自由能的状态,或者说对外展现出最大信息熵的状态。而神经网络一层层提取信息的过程,就是尺度重整化(Scale Renormalization):“合理的尺度重整化保持了系统哈密尔顿自由能的不变性……每一次尺度变换后,自由能保持不变……能量的概率分布不变……重整化群给出了损失函数,也就是不同层的F自由能的差异,训练就是来最小化这个差异。”Bayesian推理与深度学习两者,在这点上殊途同归,都遵循这个物理本质。
Al想要的因果,显然不仅仅是其中的物理原理,这些人类已有的观测结论。笔者对于让机器真正理解因果的好奇,也是远远胜过发明永动机或者统一相对论与量子力学。随机变量相互独立且遵循高斯分布是很强的假设,What if p(w) 不是高斯分布呢? What if 这些随机变量不是独立的呢?目前,神经网络还不会主动问“What if”这样的问题,会问的,只有人和佛。
从炼金术走向科学:强人工智能,需要深谙因果
同一个论坛上,图灵奖得主、贝叶斯之父 Judea Pearl 的报告《机器学习的理论障碍》(Theoretical impediments to machine learning),澄清了这个问题,同时也抛出了老人家对于让机器理解因果的深刻见解:看到(Seeing)是相关(Association P(y|x) ),而做到(Doing)是介入(Intervention P(y|do(x),z) ),想象(Imagining)是反设事实(Counterfactuals P(yx|x',y') )。针对因果关系的不对称性,Judea提出可以丰富概率论的数学语言,将Bayesian Network 发展为 Causal Network,从而也可以将基于归纳的炼金术,发展成基于演绎的因果推理。
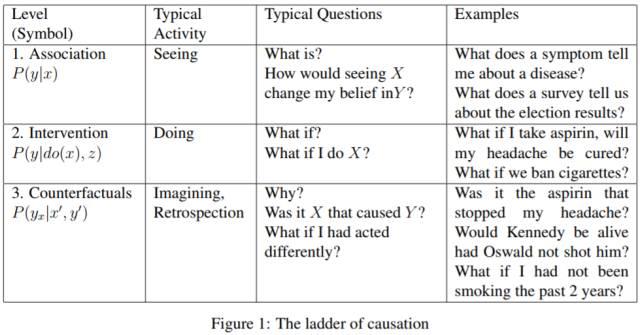
正如Judea在大会上总结的:缺乏现实模型的数据科学可能是统计学,但几乎不是科学;人类级别的强人工智能不可能从 model-blind 的学习机器中出现。也就是说,想要强人工智能,深谙因果是绕不过去的门槛。这里提一下,所有现在的 Chat-Bot 聊天机器人或智能客服,都还没有跨过这个门槛。Judea讲座是NIPS上的一股清流,无奈曲高和寡。何时才能“曲高”不“和寡”?
夸张一点说:世界上的万事万物都只有两种状态:高斯分布或去往高斯分布的路上,除非……,除非有一种神秘的力量、自由的能量,阻止这个趋势。这种神秘的力量,是地球的太阳,是普利高津眼里的耗散结构,是释迦牟尼身边的菩提树,是世人应该有的修行。Judea在儿子Daniel被恐怖分子斩首后,为缓解各民族之间的仇恨多番奔走,成了他晚年的修行。每个人都在做自己的人生修行,修行就是去高斯的过程,其中应有儒家的入世,道家的淡然,佛家的悲悯。To be,or not to be? Remember me!? Fine, Anyway.
参考资料:
http://www.science4all.org/article/shannons-information-theory/
http://dlab.clemson.edu/11._Erwin_Schrodinger_-_What_is_Life__1944_.pdf
https://en.wikipedia.org/wiki/Principle_of_minimum_energy
https://www.cs.cmu.edu/afs/cs/academic/class/15782-f06/slides/bayesian.pdf
http://www.askamathematician.com/2010/02/q-whats-so-special-about-the-gaussian-distribution-a-k-a-a-normal-distribution-or-bell-curve/
https://www.zhihu.com/question/263886044/answer/274543455
http://web.cs.ucla.edu/~kaoru/theoretical-impediments.pdf
作者:王庆法,数据领域专家,首席数据官联盟专家组成员

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国