

GPT4技术原理五:大模型的幻觉,解铃还须系铃人
阿尔伯特·爱因斯坦曾经说过:
像我们这样相信物理学的人都知道,过去、现在和未来之间的区别只是一种顽固执着的幻觉。换句话说,时间是一种幻觉。
笔者觉得,此种意义上说,光也是一种幻觉,你能看到可见光,却对红外光和紫外光“熟视无睹”。而这一切不过是同一种形式的波或者粒子。
人类的幻觉
人类的幻觉无处不在,无时不有。只是绝大多数情境下,你觉察不到而已,像红紫外光。
幻觉(Hallucination)是一种在没有外部刺激的情况下的感知,具有真实感知的特性。幻觉是生动的、实质的,并且被认为位于外部客观空间。
幻觉可以发生在任何感官模式中—视觉、听觉、嗅觉、味觉、体感、本体感觉、平衡觉、伤害感受、温度感受和时间知觉等等。
“感觉是外部和内部共同驱动的世界。” 一如柏拉图的洞穴寓言中的先民,将其看到的墙上的影子,认知为事物的外部真实存在。
150年前,冯 · 亥姆霍兹(1867)提出了感知的"无意识推理"概念。2005年Karl Friston将这种亥姆霍兹感知概念数学形式化。
知觉的原理
Friston假设大脑构建了一个世界模型,其中先验的“信念”(即概率分布)用以指导概率推理:从大脑接收到的嘈杂和模糊的感官输入中,推断出其蕴含的外部原因。
将“先验”与新的感官输入(“似然”)相结合,产生感知(“后验”),是大脑对内外部两个信息源的整合,并按其相对精度(逆不确定性)进行了加权。这是知觉的基本原理。
换句话说,一个人的先验信念相对于感官输入的精度越高,感知(后验)就越受先验支配。这意味着先验信念或感觉数据在神经元上的精确表达方式的生物异常会导致异常的知觉推理。这是人类幻觉的本质。
Friston 的感知概念数学形式如下,反映了大脑的感知其实是在做变分推断。
F(s,u) = - log(p(s|m)) + Dkl [ q(Φ|u) || p(Φ|s,m) ]
变分推断
上式中,m 代表外部客观世界,u 是大脑内部建构的世界模型,s 是感官输入,Φ是m的参数,也是大脑需要推测的导致s 的原因(隐含变量),F 是这一感知过程的自由能。
p(Φ|s,m) 是大脑根据客观世界m, 和感官输入s 希望推测出的Φ的概率分布;q(Φ|u) 是大脑根据内部先验世界模型u, 采样假定的一个Φ的概率分布。大脑会不断修正q 逼近 p(Φ|s,m) .
p(s|m) 是客观世界导致感官输入s 的概率,也是客观的,因而该项是常数;Dkl [ q(Φ|u) || p(Φ|s,m) ] 是 q 和 p 的散度,也称为 q,p的KL距离,衡量 q, p 之间的逼近程度。
大脑会不断从 u 中采样出 q, 逼近p,从而使得 p, q 距离最小化,即自由能 F(s,u) 最小化。反过来看,如果我们找到 F(s,u)最小化,此时的 Φ* 就是对Φ 的最佳近似。
在”漂亮国的核潜艇与深度学习的内卷“文中,笔者总结过:变分推断核心思想是将求解概率分布问题,转换成距离最小化的优化问题。
Friston 的这个感知概念数学形式,也被称为贝叶斯大脑。
贝叶斯大脑
“ChatGPT是第一个真正意义的人工通用智能” 文中,笔者首先总结了大脑的工作方式:
大脑不断从外部世界接收感官信息,用来更新其内部世界模型,并对未来事件做出预测。内部世界模型是关于外部世界的先验信念或假设;
大脑的主要目标是预测和控制外界的信息,以最大限度地降低不确定性和内部熵。信息熵代表大脑关于世界的内部模型的随机性或不确定性;
大脑努力将其内部模型与基于感官输入的预测误差最小化,减少信息熵可以对世界做出更准确的预测,这等于使系统的自由能最小化。
大模型认知框架
本系列“GPT4技术原理”的文章:学习语言需要相变,相变与涌现,重整化群与生成式AI,重整化群流作为最优输运,已经梳理出来大模型认知框架:
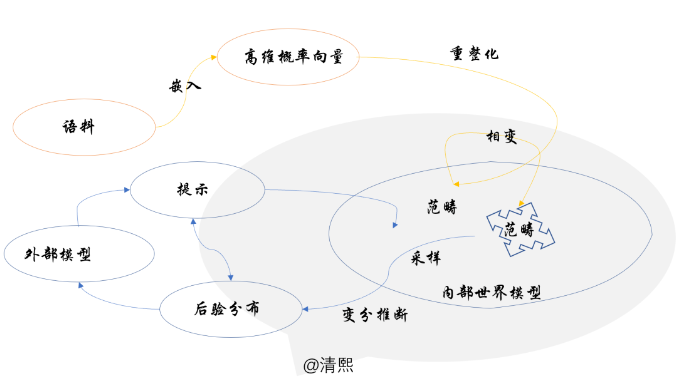
海量的文本或者多模态语料组成了大模型需要认知的外部世界的基本信息;嵌入构建高维概率化的语言空间,用来建模语言文字图像以及音视频,并对连续变量做离散化;
预训练以重整化群流的方式进行,在不同尺度上提炼语料数据中的信息概率分布;重整化群流的每一步流动(自回归预测逼近训练语料概率分布),都沿着最优输运的成本最低方向进行;
重整化群在不动点附近因新语料带来微扰而发生对称性破缺,滑入不同的相空间;不同的相空间,对应某种意义上的范畴,可形象化为信息的结晶;这是大模型从语料中学到的内部世界模型;
在外部感官输入下(被提示置于某种上下文),大模型内部将限定在相应的高维语言概率空间的子空间内推理;推理是在子空间中采样,类比时跨范畴采样;
采样不断进行,基于内部概率化了的世界模型(预训练获得的先验),针对感官输入(提示),做变分推断,最小化自由能,获取最佳采样分布q*,作为对导致感官输入的外部后验的预测。
大模型的认知框架,看起来十分接近Friston 描绘的贝叶斯大脑(维基百科上的示意图):
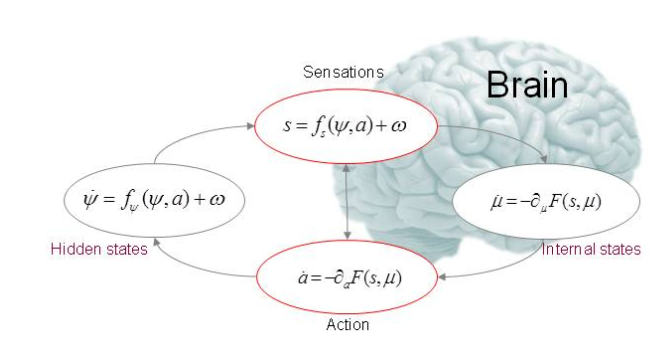
大模型幻觉
先验信念或感觉数据在神经元上的精确表达方式的生物异常会导致异常的知觉推理。这导致了人类的幻觉。大模型不仅也有类似的幻觉,而且成了实用的最大障碍。
当模型生成的文本不遵循原文(Faithfulness)或者不符合事实(Factualness),人们就可以认为模型出现了幻觉的问题。参考 Survey of Hallucination in Natural Language Generation ( arxiv.org/abs/2202.03629 )。
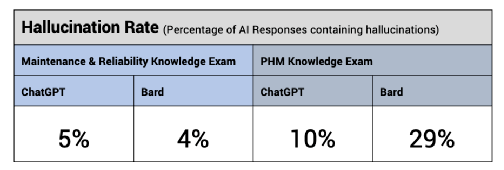
有研究(结论见下图)凸显了这个问题的严重性,以及解决大模型中幻觉的紧迫性和重要性,以确保负责任的大模型技术应用。
幻觉的来源
大模型的幻觉又来自哪里呢?从上文大模型的认知框架不难分析,框架中每一个关键环节都可能导致大模型产生幻觉。
语料中的偏差与错误,让大模型学的就是扭曲的外部信息;嵌入构建高维概率语言空间,精度不足会导致概率向量混淆;
重整化提炼语料信息概率分布,无法确保自由能不变,因而是有损提取;自回归预测仅仅是逼近训练语料概率分布,籍此构建的内部概率先验不完全精确;
重整化群因微扰而发生对称性破缺,内部模型发生相变,目前没有预知与控制的方法,带来内部世界模型结构的不确定性;
宽泛模糊的提示语,加之上下文的关联影响下,大模型内部采样选取的用于推理的子空间会存在某些偏差;
推理采样在有偏差的子空间进行,可能偏离最佳采样分布q*很远;变分推断获取的严重有偏采样分布,成了对外部后验的预测。
如何管控幻觉
解铃还须系铃人,有针对性的为幻觉来源对症下药,将是今后管控幻觉的关键措施。这里没用“消除”一词,从上文认知框架笔者推断,可将幻觉降低到“不可见”范围,但很难消除为零。
针对语料中的偏差与错误,语料的全面数据治理十分必要,既要丰富详实,又要不偏不倚;加大算力提高模型精度,增强嵌入及后续训练的信息区分度;
改进Transformer-Attention归一化算法,优化降低自由能损失,最大程度降低信息折损;自回归预测将受益于归一化优化,从而提升内部概率先验精确性;
构建重整化流的数学公式,推导出其流动的方向,并计算可能的不动点,从而借助新语料,对不动点做微扰,促进其进入更有序的相空间,实现可控的可预测的涌现;
RLHF训练结合提示工程探索不同上下文有效提示语,改进decoder模型,促进大模型内部采样使用Wasserstein距离作为概率分布近似的度量;
探测研究内部世界模型结构,进而可以控制模型温度,指导动态Bayes推理更贴切的采样概率分布,进一步亦可通过检索增强生成(RAG)效果,提高自一致自评估能力。
还可以做整体解决方案的安全架构与治理设计,请参考此篇:复杂企业的生成式人工智能解决方案架构,做最终的人工审核与确认。
写在最后
因博弈论获得诺奖的数学家约翰纳什,曾因为幻听、幻觉被确诊为严重的精神分裂症,多次诊治多次复发,最后得以彻底治愈。
精神分裂症是一种可能以贝叶斯脑推理异常为特征的疾病。贝叶斯脑认知框架,范式优雅,建模方法强大,可用以分析诊断感知推理的多种潜在异常,成为当前重要的精神分裂诊疗理论参考。
笔者梳理的大模型认知框架,与Friston 的感知概念数学形式即贝叶斯脑神似,为分析与管控大模型幻觉,找到了系统的探索途径。大模型幻觉未来必定可控。
大名鼎鼎的哲学家和数学家笛卡尔有个经典的问题:如果我们的感觉不能总是被信任,那如何区别幻觉与现实?
大模型如何作答呢?如何发挥人们的想象力,驾驭大模型这种特殊的"想象力",安全放心的应用于关键性质的任务呢?
作者:王庆法 麻省理工学院物理系学者,数据领域专家,首席数据官联盟专家组成员



 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国