

*铭文、碑刻是过去文明的思想、文化和语言的体现。金石学家破译千年前的密码,需要完成文本修复、时间归因和地域归因三大任务。
主流的研究方式是「字符串匹配」,即凭借记忆或查询语料库匹配字型相似的铭文,这导致了结果的混淆和误判。
为此,DeepMind 和威尼斯福斯卡里大学联合开发了 Ithaca,利用 AI 帮助人类学者破译希腊铭文。*
作者 | 加零
编辑 | 雪菜、三羊
金石学,是研究金石铭文、碑刻和古代铭文的学科,连接着过去文明的思想、文化和语言。目前,学界面临着一个重要问题:如何深入研究和理解这些遗产?
通常意义上,解读铭文碑刻需要金石学家完成以下 3 个基本任务:
文本修复 (text restoration):补充文本中缺失的部分;
时间归因 (chronological attribution):确定铭文写作的时间;
地域归因 (geographical attribution):确定铭文写作的初始地点。
完成这些任务,金石学家需要结合上下文和现有语料库,开展大量比对研究。虽然数字语料库的出现能一定程度减少研究人员的负担,但其采取的字符串匹配方式,往往导致结果的混淆和误判。同时由于年代久远,铭文多有受损和遗失,使得任务愈发复杂。

铭文修复图示
而 AI 善于发现并运用复杂的统计模式,对人难以处理的大批量数据进行分析。因此,DeepMind 和威尼斯福斯卡里大学 (Ca’ Foscari University of Venice) 的研究者联合开发了 Ithaca,旨在协助金石学家进行文本修复、时间归因和地域归因的工作。
实验证实,Ithaca 文本修复工作的准确率达到 62%,时间归因误差在 30 年内,地域归因准确率达到 71%,且具有很好的协同性。相关论文已发表于「Nature」。

相关成果发表在「Nature」
获取论文:
https://www.nature.com/articles/s41586-022-04448-z
Ithaca 的相关代码已开源在 GitHub 平台,金石学家也可利用公共界面开展研究。
源代码:https://github.com/deepmind/Ithaca
公共界面:https://ithaca.deepmind.com/
实验过程
数据集:机器可操作铭文集 I.PHI
研究者们基于帕卡德人文研究所的可搜索希腊铭文公共数据集 PHI 开展研究。
注:PHI 全称 The Packard Humanities Institute’s Searchable Greek Inscriptions public dataset
为了便于机器操作,研究者们对 PHI 中的文本进行过滤,为选择的文本分配数字 ID、相应的标注地点和时间信息,最终得到 I.PHI 数据集。
I.PHI 数据集是目前最大的机器可操作铭文数据集,包含 78,608 个铭文。

I.PHI 数据集示例
算法训练:针对 3 大任务开展训练
文本修复:采用交叉熵损失函数,掩盖输入文本的部分内容,训练 Ithaca 模型预测被掩盖的字符;
时间归因:以 10 年为间隔,Ithaca 将公元前后 800 年离散为具有相等概率的时间段,称为目标概率分布。采用 Kullback-Leibler 散度,最小化预测概率分布和目标概率分布之间的差异;
地域归因:使用交叉熵损失函数,将地域区域元数据作为目标标签,应用平滑系数 10% 的标签平滑技术避免过拟合。
基于此,Ithaca 在谷歌云平台上的 128 个 TPU v4 pod 上开展了一周的训练,batch size 为 8,192 篇文本,使用 LAMB 优化器以 3 × 10-4 的学习率优化 Ithaca 参数。
模型结构:Ithaca 模型包括 4 部分
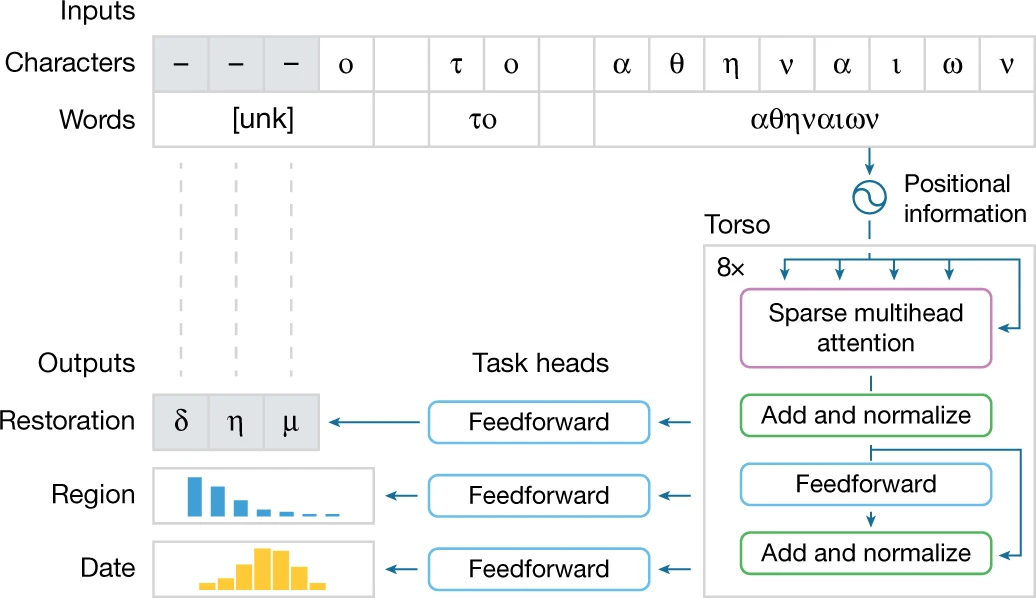
Ithaca 模型任务处理流程
Ithaca 模型的结构可总结为以下 4 部分:
1. 输入 (Inputs):将输入文本作为字符和单词共同处理,保证 Ithaca 既可以理解单个字符,又可以将其整合为单词进行上下文理解,未知、损坏的单词用特殊符号「unk」替代;
2. 躯干 (Torso):Ithaca 的躯干采用叠加 Transformer 神经网络架构,它使用一种注意力机制 (attention mechanism) 来衡量输入的字符、单词对模型决策过程的影响。
在躯干部分,Ithaca 将输入文本与位置信息结合,标准化处理为一个长度等于输入字符数的序列,这个序列中每个项目是一个 2,048 维的嵌入向量。该序列被传输给 3 个不同的任务 head;
3. 任务头(Task heads):Ithaca 有 3 个不同的任务 head,每个 head 由一个浅前馈神经网络组成,专门处理文本修复、时间归因和地域归因任务。
4. 输出(Outputs):3 个任务 head 分别输出对应结果。
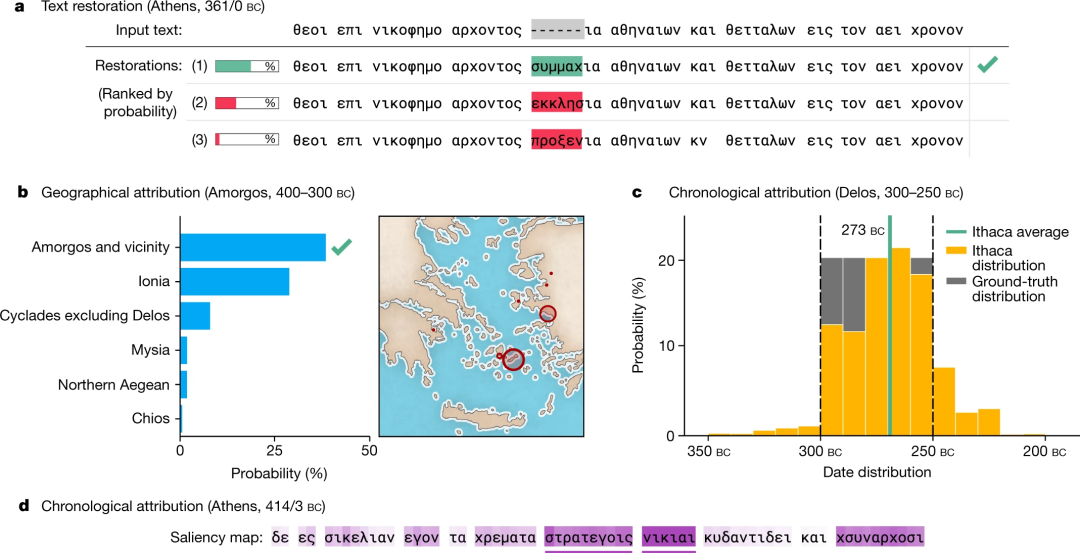
Ithaca 输出结果
文本修复:Ithaca 预测了 3 个缺失的字符,同时提供了一套按概率排序的前 20 名解码预测 (上图 a);
地域归因:Ithaca 把输入的文字分为 84 个地区,并用地图和柱状图直观地实现可能的地区预测排名表 (上图 b);
时间归因:为扩大时间归因任务的可解释性,Ithaca 追溯到公元前 800 年到公元 800 年,预测了日期的分类分布,而不是输出一个单一的日期值 (上图 c)。
模型训练结果
综合比对:Ithaca 具有优越的性能
* 4 个对比机制
Ancient historian:人类学者使用训练集来寻找文本的相似之处,与 Ithaca 的结果对比;
Ancient historian and Ithaca:Ithaca 为金石学家提供 20 个可能的修复,评估 Ithaca 与人类学者的协同性;
Pythia:一个用于文本修复任务的序列到序列递归神经网络 (a sequence-to-sequence recurrent neural network),评价 Ithaca 的文本修复性能;
Onomastics:研究人员使用希腊人名在时间和空间上的已知分布,完成一组文本的时间和地域归因,评价 Ithaca 的时间和地域归因性能。
* 3 大评价指标
字符错误率 (CER, character error rate):评价文本修复任务,计算最高预测修复序列和目标序列之间的归一化差异;
top-k accuracy:评价文本修复或地域归因任务,计算预测结果中概率最大的前 k 个结果包含正确标签的占比,常用 top 1 准确率;
distance metric (Methods):评价时间归因任务,计算预测分布的平均值与真值区间 (ground-truth interval) 之间的年数距离。
* 实验结果
文本修复

文本修复任务
a:原始铭文;
b:Rhodes-Osborne 修复后的铭文;
c:Pythia 修复版,与 Rhodes-Osborne 版有 74 处不匹配;
d:Ithaca 修复版,与 Rhodes-Osborne 版有 45 处不匹配;
图中修复正确的部分由绿色表示,错误用红色突出表示。
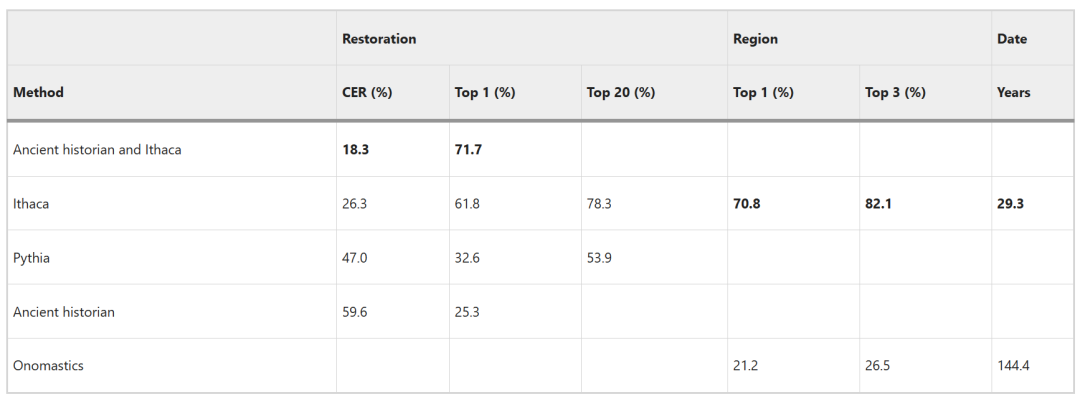
原始铭文 (IG II² 116) 缺失 378 个字符,以 Rhodes-Osborne 在 2003 年完成的修复 (图 b) 为基准,Ithaca 的 CER 为 26.3%,top 1 准确率达到 61.8%。
与金石学家相比,Ithaca 的 CER 低 2.2 倍。Ithaca 的前 20 名预测准确率为78.3%,比 Pythia 高 1.5 倍。
2. 地域归因
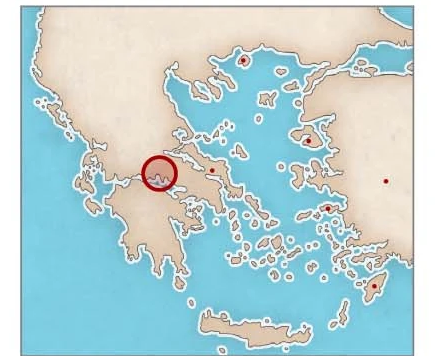
地域归因任务
地域归因任务中,Ithaca 达到了 70.8% 的 top 1 准确率和 82.1% 的 top 3 准确率。上图表示 Ithaca 将 manumission 铭文正确的归因到了 Delphi 地区。
3. 时间归因
时间归因任务
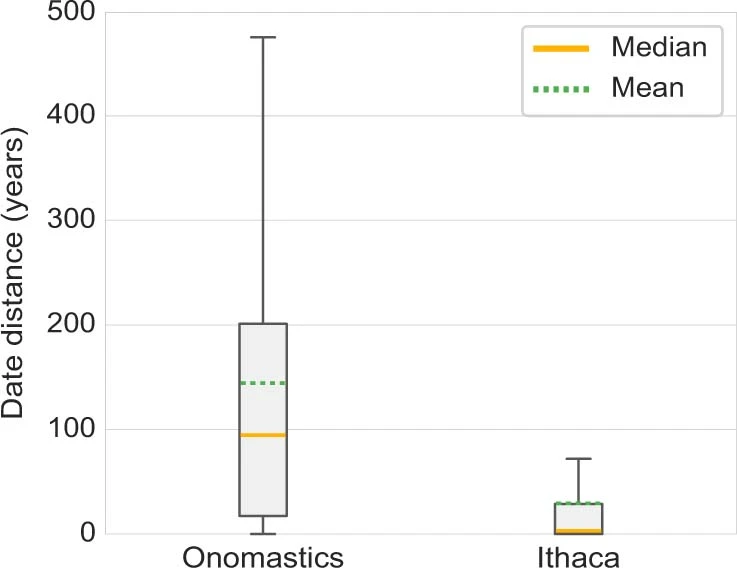
对于时间归因任务,人类专家预测的平均值为 144.4,中位数为 94.5 年,而 Ithaca 的预测与真值区间 (ground-truth interval) 平均差距为 29.3 年,中位数的差距仅为 3 年。
综合 Ithaca 在三项任务中的表现,结果整理如下:
相较于人类专家和 Pythia,Ithaca 在 3 大任务上都展现了优越的性能。
当人类专家与 Ithaca 协同时,达到了 18.3% 的 CER 和 71.7% 的 top 1 准确率,相比金石学家单独开展工作呈现出 3.2 倍和 2.8 倍的改善,相比 Ithaca 独自完成任务也有显著改善,展现了 Ithaca 优越的协同性。
Ithaca 的实验结果对比
时间归因:Ithaca 解决争议问题
部分铭文的时间归因一直存在争议,传统时间归因采用的 sigma 测年标准 (sigma dating criterion) 无法保证准确,金石学家无法确定这些铭文是在公元前 446/5 年之前还是之后。
如下图的铭文,依照传统方法追溯到公元前 446/5 年,但最近被重新追溯到公元前 424/3 年。

一条争议铭文(局部)
这组有争议的铭文存在于 I.PHI 数据集中,Ithaca 的时间归因结果推翻了基于 sigma 测年标准的传统历史解读,与新发现的基础事实平均相差 5 年。
由此证明,Ithaca 可以帮助历史学家缩小日期范围,提高历史事件时间归因的精确度。
AI 与人类:1 + 1 > 2 ?
Ithaca 的结果输出部分非常有趣,它并不会输出单一的答案,而是给出多种可能的结果以供研究人员选择。
这值得其他 AI 开发者和使用者借鉴,与其依赖 AI 的输出,不如利用 AI「探路」,排除一些错误答案,拓展自主思考的深度和广度。
将 AI 的计算能力与人类的创造性和深度思考相结合,Ithaca 帮助我们开拓了一种与 AI 携手合作的范式。
未来,我们期待 AI 与人类学者协同并进,实现「1+1 > 2」的目标。
参考文献:
https://www.nature.com/articles/s41586-022-04448-z
https://www.nature.com/articles/d41586-023-03212-1
—— 完 ——

 2023-11-15
2023-11-15


 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国