

作者:李宝珠
编辑:三羊
中国科学院深圳先进技术研究院罗小舟团队提出了,基于酶动力学参数预测框架 (UniKP),实现多种不同的酶动力学参数的预测。
众所周知,生物体内的新陈代谢是通过各种各样的化学反应来实现的。这些反应如果在体外进行,通常需要在高温、高压、强酸、强碱等剧烈条件下才能发生。
但在生物体内,新陈代谢反应却可以在极为温和的条件下高效进行,这主要归功于重要的有机催化剂——酶。
作为贯穿高中生物学科的高分知识点,酶的特性或许已经烙印在大家记忆深处——催化效率高、专一性强、作用条件温和等。更重要的是,酶与很多人体疾病密切相关,还可以用于诊断与治疗。一直以来,人们在深入研究酶分子结构与功能的同时,也在持续探究酶促反应的影响因素。
研究酶促反应速率以及各种因素对酶促反应速率影响机制的科学,被称为「酶促反应动力学」,在研究中,酶在特定反应中的催化效率通常通过酶动力学参数 (enzyme kinetic parameters) 来衡量。
酶促反应动力学参数包括了酶周转数 kcat、米氏常数 Km 和催化效率 kcat / Km 等,目前主要依赖湿实验来进行参数测量,但这一过程耗时且成本高,使得实验测得的酶动力学参数数据库规模相对较小,而数据的稀缺则会限制下游系统生物学和代谢工程领域的发展。
针对于此,中国科学院深圳先进技术研究院合成所罗小舟团队提出了,基于预训练大语言模型和机器学习模型的酶动力学参数预测框架 (enzyme kinetic parameters prediction framework,UniKP)。
该框架仅通过给定酶的氨基酸序列和底物的结构信息,就可以实现多种不同的酶动力学参数的预测。此外,研究团队进一步将环境因素纳入考量,提出了基于 UniKP 的双层框架 EF-UniKP,实现了更准确地酶动力学参数的预测。

该研究成果已发表于 Nature Communications
论文链接:
https://www.nature.com/articles/s41467-023-44113-1
GitHub链接:
https://github.com/Luo-SynBioLab/UniKP
关注公众号,回复「UniKP」下载完整论文
代表性数据集验证模型价值
研究团队选择了 4 个具有代表性的数据集来验证 UniKP 的性能及价值。
首先是 DLKcat 数据集,研究人员筛选后得到了 16,838 个样本,包括来自 851 个生物体的 7,822 个独特蛋白质序列和 2,672 个独特底物。数据集按照 9:1 的比例划分为训练集和测试集。
其次是 pH 和温度数据集,其中 pH 数据集包含 636 个样本,由 261 个独特的酶序列和 331 个独特的底物组成;温度数据集包含 572 个样本,由 243 个独特的酶序列和 302 个独特的底物组成。数据集按照 8:2 的比例划分为训练集和测试集。
第三是米氏常数 (Km) 数据集,由 11,722 个样本组成,包括酶序列、底物分子指纹图谱和相应的 Km 值。数据集按照 8:2 的比例划分为训练集和测试集。
第四是 kcat/Km 数据集,包含 910 个由酶序列、底物结构及其相应的 kcat/Km 值组成的样本。
两大关键组件:表示模块+机器学习模块
研究团队提出的 UniKP,能提高根据给定的酶序列和底物结构预测 kcat、Km 和 kcat / Km 的准确性。UniKP 框架由两个关键组件组成——表示模块 (representation module) 和机器学习模块。
表示模块的作用是将复杂的酶和底物信息转换为机器学习模型能够理解和处理的向量表示,以便后续的机器学习模块进行预测和分析。

其中,酶序列表示模块 (Enzyme sequence representation module), 使用预训练语言模型 ProtT5-XL-UniRef50 对酶的信息进行编码,每个氨基酸通过该模型被转换为一个 1,024 维的向量,并通过均值池化 (averaged by mean pooling) 进行处理,最终生成一个 1,024 维的向量来表示整个酶的序列信息(如上图所示)。
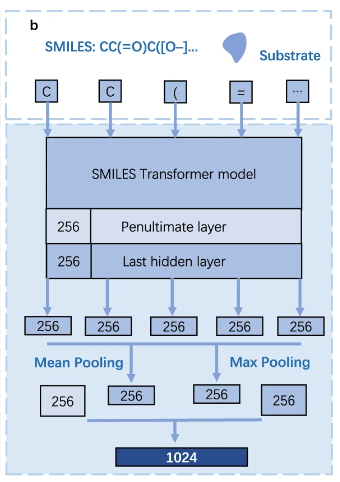
底物结构表示模块 (Substrate structure representation module),使用预训练语言模型 SMILES Transformer model 对底物的信息进行编码。底物结构被转换为 SMILES 格式,进而通过预训练的 SMILES 转换器生成一个 1,024 维的向量,并对最后一层和倒数第二层的第一个输出进行均值和最大池化,最终生成一个 1,024 维的向量来表示底物的结构信息(如上图所示)。
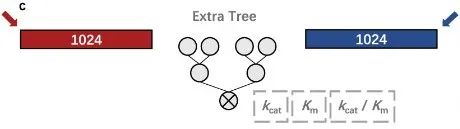
针对机器学习模块,研究团队对比了 16 种不同的机器学习模型,以及 2 种代表性的深度学习模型——卷积神经网络和循环神经网络。
结果显示,集成性模型表现出更好的性能,尤其是随机森林 (random forests) 和极端随机树 (extra trees) 显著优于其他模型,其中极端随机树表现最佳 (R²=0.65)。如上图所示,机器学习模型以连接表示向量为输入,生成预测的 kcat、Km 或 kcat / Km 值。
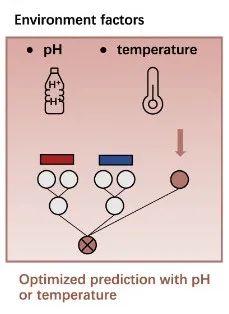
此外,研究人员将环境因素纳入考量,生成了优化的预测框架,并在涵盖 pH 和温度信息的两个数据集上进行了验证(如上图所示)。
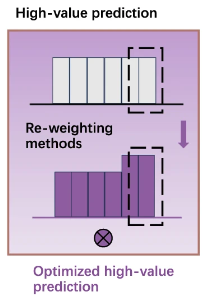
最后,UniKP 通过不同的重新加权方法来调整样本权重分布,从而为高价值预测任务生成优化预测结果(如上图所示)。
双层框架——EF-UniKP
作为双层框架,EF-UniKP 包含一个基础层 (base layer) 和一个元层 (meta layer),如下图所示:
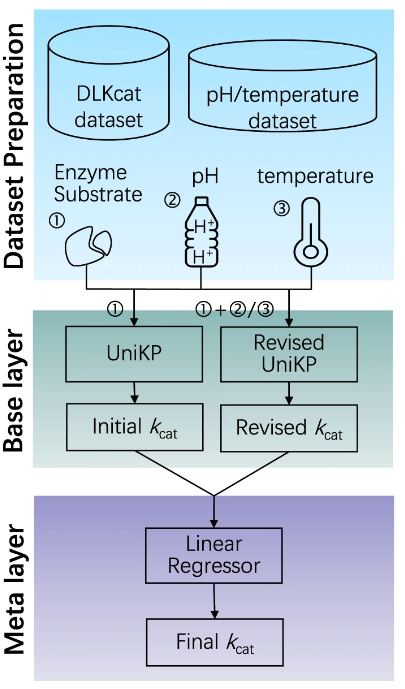
EF-UniKP 架构
基础层包含两个独立模型——UniKP 和 Revised UniKP。UniKP 以蛋白质和底物的连接表示向量作为输入,而 Revised UniKP 使用蛋白质和底物的连接表示向量、结合 pH 或温度值作为输入。
元层包括一个线性回归模型,使用来自 UniKP 和 Revised UniKP 的预测 kcat 值来预测最终的 kcat 值。
R² 值高出20%,EF-UniKP 完胜
研究团队在 kcat 预测任务上使用 DLKcat 数据集对 UniKP 框架进行了验证,该数据集包含 16,838 个样本。在 5 轮随机划分的测试集验证中,UniKP 的 R² 值为 0.68,比 DLKcat 提高了20%。此外,在测试中,DLKcat 的最高值比 UniKP 的最低值低了 16%,进一步证明了 UniKP 的稳健性。
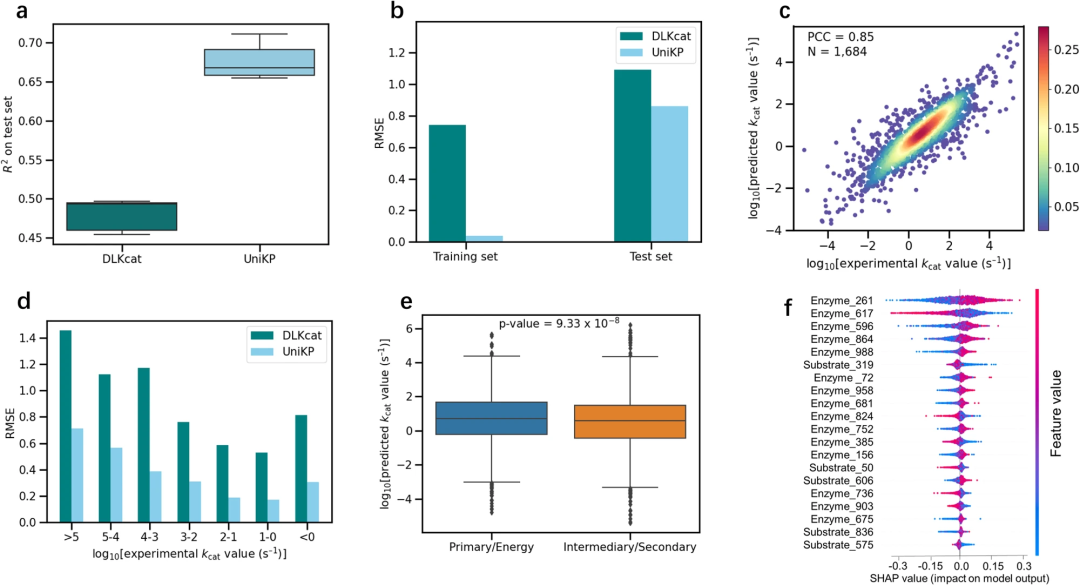
UniKP 在 kcat 预测中的表现
随后,研究团队创建了涵盖 pH 和温度信息的两个数据集来对 EF-UniKP 进行了评估,并分别按照 8:2 的比例划分为训练集和测试集。
在测试集上,EF-UniKP 相较于 UniKP 和 Revised UniKP 表现更佳。在 pH 数据集测试中,EF-UniKP 的 R² 分别高出 20% 和 8%,在温度数据集测试中,EF-UniKP 的 R² 分别高出 26% 和 2%。在酶和底物至少有一个不在训练集的测试中,EF-UniKP 在 pH 数据集上的 R² 值相较于 UniKP 和 Revised UniKP 分别高出 13% 和 10%,在温度数据集上分别高出 16% 和 4%。
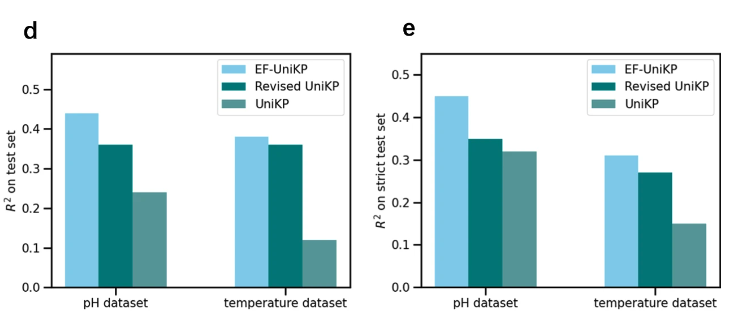
EF-UniKP相较于UniKP和Revised UniKP表现更佳
蝴蝶模式:拉通科研与产业
罗小舟课题组背后的中国科学院深圳先进技术研究院(简称“深圳先进院”)是由中国科学院、深圳市人民政府及香港中文大学于 2006 年 2 月共同建立的,由 8 个研究所组成:
* 中国科学院香港中文大学深圳先进集成技术研究所
* 生物医学与健康工程研究所
* 先进计算与数字工程研究所
* 生物医药与技术研究所
* 脑认知与脑疾病研究所
* 合成生物学研究所
* 先进材料科学与工程研究所
* 碳中和技术研究所(筹)
罗小舟博士是在 2019 年完成了在加州大学伯克利分校的博士后研究,回国并正式加入深圳先进院合成生物学研究所,任职研究员。同年,其作为合伙人之一筹备的 「森瑞斯生物」也在深圳正式成立,专注于合成生物技术的研发及其在各领域的创新应用。2022 年 3 月,公司完成了近亿元人民币的 A 轮融资。
罗小舟博士「科研」与「产业」兼顾的发展路径恰恰与深圳先进院的宗旨完美契合。据介绍,深圳先进院探索了「0—1—10—∞的蝴蝶模式」,这也在森瑞斯生物得到了很好的实践。
在发现液体橡胶 HVR 和大麻素 CBD 可共用同一自主知识产权的底盘细胞后,森瑞斯利用其前期已开发的数个针对酿酒酵母改造的工艺方法,再结合内部的合成生物元件库,在 6 个月时间内就将液体橡胶 HVR 产量提升到了可商业化的水平。
这其中,罗小舟博士与其导师、同时也是森瑞斯的发起人之一 Jay D. Keasling 院士合作,在 2019 年便成功打通大麻素的生物全合成通路,成为了其商业化的基础。
罗小舟表示,实现管线的快速产业化有着两大关键因素:一是学术界和产业深度融合,学术界有效搭建产业界所需化合物的 0-1 的合成通路;二是标准化的生产工艺和工具,覆盖从 0-1 的学术研究、1-10 的工程研发、到 10 - 无限工业化放大这三个阶段,打造合成生物的生产线,提升 1-10 的研发效率。
参考资料:
https://www.siat.ac.cn/cyjl2016/202203/t20220330_6416153.html
https://mp.weixin.qq.com/s/QsAqhqIBwYhDfdtY1zJACw


 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国