

你是否想象过机器人也可以成为游戏领域的超级高手?是时候让你的幻想成为现实,深度强化学习这位头号玩家来啦!这是一个令人兴奋又神秘的领域,简单来说,它就是让计算机像人类一样学习和玩游戏。深度强化学习的学习过程就像是一场盛大的冒险,只不过主角不再是你,而是一台智能机器。在这个冒险的旅程中,机器会探索各种各样的环境,在探索的过程中,机器需要学习如何在这个世界中生存,这个过程就像一段传奇的武侠故事,从小小菜鸟开始,一路闯荡,跌跌撞撞,最后成长为一代巨侠!那么深度强化学习的原理是怎样的呢?让我们来一起看看吧。
1、深度学习
深度强化学习融合了深度学习和强化学习,深度学习让机器可以处理复杂的问题。这就像是机器有了一个超级大脑,深度神经网络让它可以处理更多的信息,并做出更聪明的决策。这样一来,机器可以在各种各样的游戏中展现出惊人的技能,从围棋、超级马里奥到复杂的电子游戏,通通难不倒它。我们先来介绍一下深度学习。
深度学习是一种基于神经网络的机器学习方法,其目的是通过多层神经元的组合计算来挖掘样本数据的潜在规律,实现高效的数据处理、数据识别、数据分类等任务。当前常见的深度学习应用领域有图像识别、自然语言处理、深度强化学习等等。
深度神经网络是深度学习的核心组成部分,它由多个神经元组成的神经网络层叠加而成,神经网络依据自身的状态对外界输入信息做出响应,实现对数据的智能处理。神经元是深度神经网络中的基本单位,其设计模仿了自然界中的生物神经元的工作机制:通过接收外界的刺激信号而兴奋,内部对信号进行处理,之后将信号传导到下一个神经元。

图1 神经元模型图
多个拥有输入和输出的神经元组成一层神经网络,多层神经网络叠加则构成了深度神经网络,与浅层神经网络相比,深度神经网络能够学习到更复杂的特征表示,并在许多任务上取得了更优秀的性能。

图2 深度神经网络模型图
深度神经网络通常由多个层组成,在深度神经网络中,上一层网络的输出将作为下一层网络的输入,其中,接收外界输入的网络层被称作输入层,最终输出结果的网络层被称作输出层,剩余中间网络层均被称为隐含层。深度神经网络的层与层之间的连接形成了一张复杂的图结构,称为神经网络拓扑结构。神经网络的层数越深,包含的可训练参数就越多,训练时的计算量就越大。
2、强化学习
接下来,我们介绍一下强化学习。
机器学习方法通常分为三类:有监督学习、无监督学习和强化学习。强化学习作为机器学习中的一种重要类型,常用于处理连续决策问题,不同于前两种学习方式,强化学习更注重于从与环境的交互行为中学习并改进自身策略。强化学习涉及到智能体(agent)和环境(environment)两个概念,其中,智能体代表强化学习算法的交互实体,环境代表与智能体交互的外部环境模型。

图3 强化学习概念图
智能体的学习模式如图3所示,首先,智能体观测环境,获取当前的环境状态State,然后通过自身当前的策略制定行为Action并将其执行。智能体的动作会影响环境,环境会对该行为做出反馈,即给智能体一个即时奖励信号Reward,同时环境状态发生改变,到达下一新状态,智能体继续观测环境,获取新的环境状态,继而制定下一个行为。智能体反复迭代与环境之间的交互行为,根据层层反馈不断改进策略,以达到最大化累积奖励的探索目标。
举个例子,在智能机器的探索过程中,机器并不会被告知应该怎么做,而是通过试错来使它学习。当它尝试一种行动,比如在超级马里奥游戏中跳跃,它可能会得到积极的奖励,比如得分增加;或者得到消极的奖励,比如游戏角色受伤。通过不断尝试和反馈,机器逐渐学会了在不同情况下采取最优的行动,就像我们在现实生活中学习避免犯同样的错误一样。

图4 超级马里奥游戏画面
在强化学习中,为了避免过拟合和提高泛化能力,通常采用探索和利用的策略。探索策略是指在学习过程中,以一定的概率选择未经历过的动作,以便学习更加全面和深入的策略。利用策略是指在学习过程中,以一定的概率选择已经证明有效的动作,以获得更高的累积奖励。
3、深度强化学习
接下来,介绍我们的主角——深度强化学习。
深度强化学习是强化学习与深度学习的结合。借助于深度神经网络的计算优势和感知优势,深度强化学习算法对具有复杂的高维状态空间和高维动作空间的环境的探索能力有了长足进步,对状态价值和动作价值的求解能力也得到显著提升。深度强化学习神经网络可以接收高维输入,在与环境的交互中学习最优控制策略并输出动作,广泛应用于实时决策、智能机器人、游戏博弈等多个领域。
Deep-Q-Network(DQN)是深度强化学习领域里程碑式的算法,该算法由DeepMind在2013年提出,首次将深度学习方法与强化学习方法融合,开辟了深度强化学习研究的先河。
DQN算法旨在解决传统Q-learning算法在处理高维状态空间时出现的问题。
传统Q-learning算法维护一张S-A表来记录在每个状态下采取每个动作对应的价值Q,通过查询S-A表,智能体在每一个状态下都选取具有最大价值的动作,也就实现了智能体的最优控制。

图5 模拟S-A表示意图
S-A表存在一定的局限性,其使用前提是S-A的组合为有限值,当S-A组合无法穷举时,则无法通过查询S-A表的方式选取最优动作,同时,在S-A组合数量超出算力承受范围时,查询Q表的复杂度也是极高的。
深度神经网络具有强大的拟合能力,DQN继承了Q-learning的思想,但采用了深度神经网络来替代S-A表。

图6 Q-Net
通过训练神经网络,使其能根据状态输出对应状态下动作的价值。模型的损失函数:

其中 为Q值的目标值,损失函数表示了当前估计Q值与目标Q值之间的差距。通过使用梯度下降方法最小化损失函数,来进行对网络的训练。
为Q值的目标值,损失函数表示了当前估计Q值与目标Q值之间的差距。通过使用梯度下降方法最小化损失函数,来进行对网络的训练。
需要注意到,Q-Net在更新时参数发生变化,则 的值发生变化,但同时
的值发生变化,但同时 v的值也发生了变化,即模型追求的目标Q值处于一种变化的状态,具有不稳定性,以变动的目标值来训练网络则导致估计值也陷入不稳定的状态,因此DQN算法引入了另一个网络结构Target-Net。Target-Net的网络结构与Q-Net完全相同,在训练过程中,DQN算法使用Target-Net来生成目标Q值,而不是Q-Net。Target-Net保持稳定的权重,使用Target-Net生成的目标Q值来计算损失函数,这可以有效解决目标Q值的不稳定性和发散问题。Target-Net处于慢更新状态,每隔一定的时间步,Target-Net使用Q-Net的参数来实现自身的更新:
v的值也发生了变化,即模型追求的目标Q值处于一种变化的状态,具有不稳定性,以变动的目标值来训练网络则导致估计值也陷入不稳定的状态,因此DQN算法引入了另一个网络结构Target-Net。Target-Net的网络结构与Q-Net完全相同,在训练过程中,DQN算法使用Target-Net来生成目标Q值,而不是Q-Net。Target-Net保持稳定的权重,使用Target-Net生成的目标Q值来计算损失函数,这可以有效解决目标Q值的不稳定性和发散问题。Target-Net处于慢更新状态,每隔一定的时间步,Target-Net使用Q-Net的参数来实现自身的更新:

其中 表示Target-Net的参数,
表示Target-Net的参数, 表示Q-Net的参数,
表示Q-Net的参数, 参数用来调整更新幅度。
参数用来调整更新幅度。
DQN算法在Atari游戏中取得了优异的表现,它的成功也促进了更多深度学习与强化学习融合研究的发展。
4、深度强化学习的经验回放机制
深度强化学习智能体的交互行为可以用四元组 来记录,其中s为t时刻的环境状态,a为t时刻的智能体动作,r为t时刻的奖励,
来记录,其中s为t时刻的环境状态,a为t时刻的智能体动作,r为t时刻的奖励,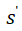 为t+1时刻的环境状态。通过对该交互记录进行计算,可以得到损失函数用于训练网络。
为t+1时刻的环境状态。通过对该交互记录进行计算,可以得到损失函数用于训练网络。
传统的Q-learning算法使用的是在线更新方式,每次训练都只使用当前的交互记录,训练结束后就会丢弃该条交互记录,继续采集新记录,这种方式更新较慢。事实上,模型每次采集的记录可以重复使用。通过使用一个经验回放池来存储智能体交互产生的记录样本,然后从经验回放池批量采集经验进行网络训练,可以增加样本的利用率,减少采样压力。在实际应用中,要当经验回放池中存储了足够数量的经验后才会开始采样并更新网络,当经验回放池的容量达到上限时,每存进一条新样本,就会以先进先出的方式删除最早进入经验池的一条样本。
同时,在一些连续场景如游戏场景中,当前的画面状态与下一时刻的画面状态会比较接近,导致两个相邻的样本间据有很强的相关性,如果对样本进行顺序采样,则可能导致网络更新过拟合。所以经验回放池在设计上采用了随机抽样的方式,降低采样结果之间的关联,该随机采样方式可以提升模型训练的效果。
5、总结
近年来,深度强化学习像一颗新星冉冉升起,迎来了研究的热潮,同时研究的成果也被各大主流媒体争相报道,比如击败人类围棋世界冠军的AlphaGo、击败DOTA2世界冠军战队的OpenAI Five、击败KPL顶尖战队的腾讯AI-绝悟等等,深度强化学习展现出了越来越令人惊奇的潜力。
当然,深度强化学习不仅仅局限于应用在游戏领域,它在许多领域都有着应用潜力,比如自动驾驶、金融交易和医疗保健等领域,就连当下大放异彩的ChatGPT也应用了深度强化学习。
深度强化学习不仅是让机器变得更智能,更重要的是,它让科技变得更加有趣和有益。让我们期待未来,看看深度强化学习会带给我们怎样的惊喜吧!
参考文献
[1] 数科每日.什么是深度强化学习?|CSDN,2022.
作者:李凡聪
单位:中国移动智慧家庭运营中心



 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国