

在平时的业务场景中,经常有一些场景需要使用定时任务,而且对于现在快速消费的时代,每天都需要发送各种推送,消息都需要依赖定时任务去完成,应用非常广泛,这时候选择一个好的定时任务调度系统就显得尤为重要。
1.1 什么是定时任务
定时任务是按照指定时间周期运行任务。使用场景为在某个固定时间点执行,或者周期性的去执行某个任务,比如:每天晚上24点做数据汇总,定时发送短信等。
1.2 常见定时任务方案
While + Sleep : 通过循环加休眠的方式定时执行。
Timer和TimerTask实现 :JDK自带的定时任务,可以实现简单的间隔执行任务(在指定时间点执行某一任务,也能定时的周期性执行),无法实现按日历去调度执行任务。
ScheduledExecutorService : Java并发包下,JDK1.5出现,是比较理想的定时任务实现方案。Eureka就使用的是它。
QuartZ :使用Quartz,它是一个异步任务调度框架,功能丰富,可以实现按日历调度,支持持久化。
使用Spring Task:Spring 3.0后提供Spring Task实现任务调度,支持按日历调度,相比Quartz功能稍简单,但是在开发基本够用,支持注解编程方式。
pringBoot中的Schedule :通过@EnableScheduling+@Scheduled最实现定时任务,底层使用的是Spring Task。
1.3 分布式定时任务面临的问题
上述的定时任务都是集中式(单体项目使用)的定时任务,在分布式中将会面临一些问题或不足
业务量大,单机性能瓶颈需要扩展;
多台机器部署如何保证定时任务不重复执行;
定时任务时间需要可调整,可以暂停;
机器发生故障down机,定时任务依然可用,如何实现故障转移;
定时任务,执行日志是否可监控。
1.4 分布式定时任务面临的问题
执行器:批量运行程序,即实际运行作业逻辑的进程;
执行器组:逻辑概念,是多个执行器的集合。每个作业都需要绑定一个执行器组,根据作业所配置的路由策略进行派发;
作业JOB:作业是批量逻辑的载体,是批量运行的最小单位;在Java里,作业对应的就是一个方法函数;在shell里,作业对应的就是一个sh脚本。
任务Task:任务是作业编排的容器,是多个作业如何有序运行的工作流定义。
1.5 分布式定时任务xxl-job
XXL-JOB是一个分布式任务调度平台,于2015问世,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。其具备且不止如下能力:
简单:支持通过Web页面对任务进行CRUD操作,操作简单,一分钟上手;
动态:支持动态修改任务状态、启动/停止任务,以及终止运行中任务,即时生效;
调度中心HA(中心式):调度采用中心式设计,“调度中心”基于集群Quartz实现并支持集群部署,可保证调度中心HA;
执行器HA(分布式):任务分布式执行,任务"执行器"支持集群部署,可保证任务执行HA;
弹性扩容缩容:一旦有新执行器机器上线或者下线,下次调度时将会重新分配任务;
路由策略:执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮询、随机、一致- 性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等;
故障转移:任务路由策略选择"故障转移"情况下,如果执行器集群中某一台机器故障,将会自动Failover切换到一台正常的执行器发送调度请求。
任务失败告警:默认提供邮件方式失败告警,同时预留扩展接口,可方面的扩展短信、钉钉等告警方式;
2、xxl-job架构设计
2.1 设计思想
将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。
将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性;
2.2 架构设计图
xxl-job分为调度中心和执行器两大模块。
2.2.1 调度模块(调度中心)
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块;
支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover(故障转移)。
2.2.2 执行模块(执行器)
负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效;
接收“调度中心”的执行请求、终止请求和日志请求等。
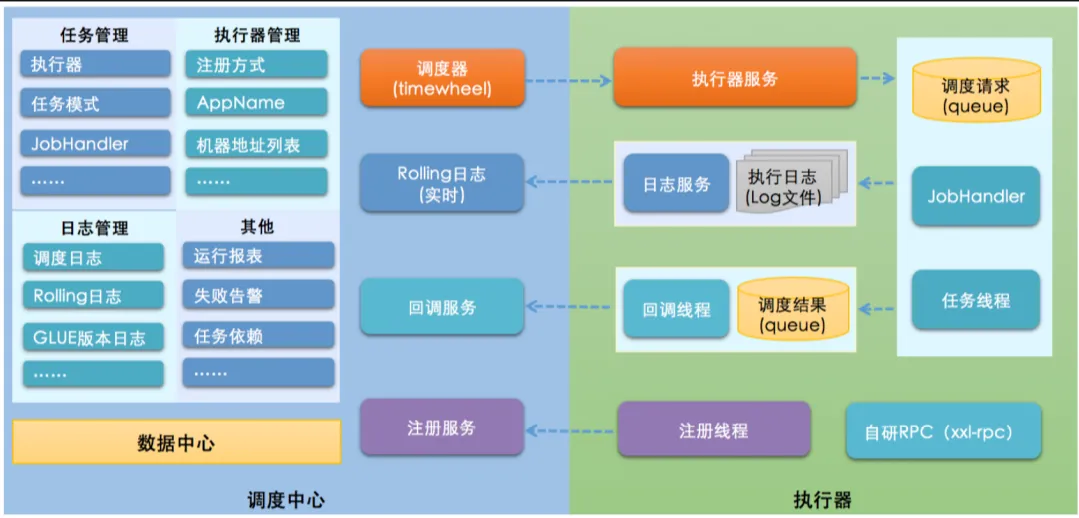
XXL-JOB架构图V2.1.0
2.2.3 调度中心高可用
基于数据库的集群方案,数据库选用Mysql;集群分布式并发环境中进行定时任务调度时,会在各个节点会上报任务,存到数据库中,执行时会从数据库中取出触发器来执行,如果触发器的名称和执行时间相同,则只有一个节点去执行此任务。
2.2.4并行调度
调度采用线程池方式实现,避免单线程因阻塞而引起任务调度延迟。XXL-JOB调度模块默认采用并行机制,在多线程调度的情况下,调度模块被阻塞的几率很低,大大提高了调度系统的承载量。
XXL-JOB的不同任务之间并行调度、并行执行。XXL-JOB的单个任务,针对多个执行器是并行运行的,针对单个执行器是串行执行的。同时支持任务终止。
2.2.5执行器(任务)高可用
执行器如若集群部署,调度中心将会感知到在线的所有执行器,如“127.0.0.1:9997, 127.0.0.1:9998, 127.0.0.1:9999”。多个执行器可以选择“路由策略”来采用轮询,随机等方式进行多机器调度。
当任务”路由策略”选择”故障转移(FAILOVER)”时,当调度中心每次发起调度请求时,会按照顺序对执行器发出心跳检测请求,第一个检测为存活状态的执行器将会被选定并发送调度请求。调度成功后,可在日志监控界面查看“调度备注”
3、xxl-job具体实践
3.1.下载源码
请下载项目源码并解压,使用IDEA工具导入项目
源码仓库地址
https://github.com/xuxueli/xxl-job
项目代码结构如下:

3.2. 导入数据库
打开项目代码,获取 “调度数据库初始化SQL脚本” 并执行即可。
“调度数据库初始化SQL脚本” 位置为:
xxl-job/doc/db/tables_xxl_job.sql
数据库名:xxl_job
xxl_job_lock:任务调度锁表;
xxl_job_group:执行器信息表,维护任务执行器信息;
xxl_job_info:调度扩展信息表:用于保存XXL-JOB调度任务的扩展信息,如任务分组、任务名、机器地址、执行器、执行入参和报警邮件等等;
xxl_job_log:调度日志表:用于保存XXL-JOB任务调度的历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等等;
xxl_job_log_report:调度日志报表:用户存储XXL-JOB任务调度日志的报表,调度中心报表功能页面会用到;
xxl_job_logglue:任务GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能;
xxl_job_registry:执行器注册表,维护在线的执行器和调度中心机器地址信息;
xxl_job_user:系统用户表;
3.3. 启动调度中心
打开 xxl-job-admin 的配置文件,
xxl-job/xxl-job-admin/src/main/resources/application.properties
对调度中心进行配置,重要配置如下:
server.port : 根据情况修改端口
spring.datasource.url :指向刚才准备的数据库
spring.datasource.password : 记得修改成自己的数据库密码
spring.mail.username :配置自己的邮件账号
spring.mail.password :邮件的授权码
根据自己的情况进行修改,然后启动调度中心 ,执行XxlJobAdminApplication#main 方法 ,启动之后,浏览器访问
http://localhost:8080/xxl-job-admin;
注意URL中有个上下文路径。默认登录账号 admin/123456, 登录后运行界面如下图所示。




 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国