

克拉玛依市科技馆
AI展品
北京航空航天⼤学
智能计算与机器学习实验室2024年04⽉
1 创作背景
人工智能飞速发展的当下,基于人工智能算法的各类产品已经渗透到了生活中的方方面面,给我们的工作、生活都带来了巨大的便利。而由于客观存在的地区差异,人工智能产品在边疆地区的普及程度与北京等一线城市相差甚远,其背后的基本原理更是让大众很难短时间了解与接受。因此我们的项目则是希望利用几个简单、好用的人工智能算法,将其包装成为数个有趣的应用,让大家在体验到人工智能带来的乐趣的同时,简单了解其背后的算法原理。
2 展品项目
2.1 我的数字信息
该展项依赖的技术背景是人脸识别,主要目的是让游客通过体验面部信息录入的过程,了解人脸识别技术。
人脸识别的应用场景有很多,最常见的是人证对比,在地铁口,高铁入站,或是酒店入住之前,都需要进行人脸识别,以确保持证人的身份与所持证件上一致。随着人工智能的不断发展,人脸识别也越来越多的被用在移动支付,上班打卡等活动中。
该展项的设计是让游客在体验识别过程时观察到算法的实现原理。当点击我们“人脸识别”的功能的时候,会弹出摄像头,点击拍照,此时我们将卷积神经网络做了可视化,游客可以观察到拍到的照片从原本的三维图像矩阵被逐渐压缩成为一个数学表征,通过最后的结果我们就可以做对比并得出结果。如果是一张新的人脸,就需要输入姓名;如果是库中已有的人脸,就会弹出名字以及年龄等信息。
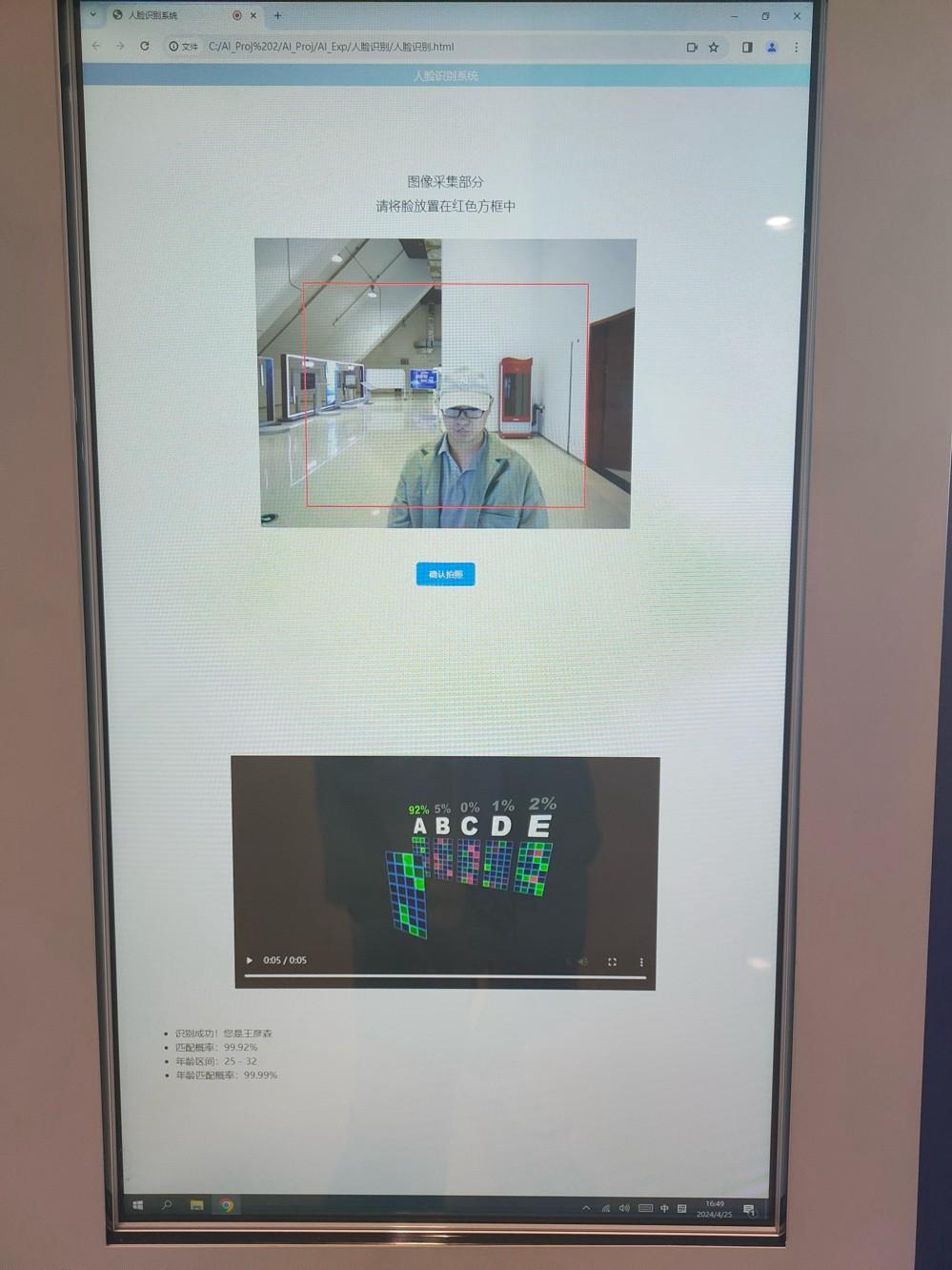
“我的数字信息”展品示意图
对于人脸识别,未来的大势所趋是改2D的图片识别为3D建模,可以大大提高识别精度,对于部分遮挡的人脸,旋转后的人脸都能
进行更好的识别和应对;除了人脸识别,还有很多传统的人物对比方式比如虹膜识别,指纹识别,声纹识别,将所有的这些信息都结合起来形成新的数据库,也将是未来的趋势所在。游客通过该展项的体验,会对未来该方向的发展产生较高的兴趣。
2.2 AI创作
该展项依赖的技术背景是图像生成技术,主要目的是让游客了解目前的图片生成、视频生成的发展情况。
AI生成的原理是利用diffusion(扩散)模型。它依靠的原理就像它的名字:扩散。在物理学中,扩散是任何事物的整体运动。
(原子,能量)从较高浓度的区域到较低浓度的区域。现在想象一下,将一小滴油漆滴入一杯水中,油漆的密度将集中在一个位置,但随着时间的推移,该滴将扩散到水中直至达到平衡。在现实世界中,我们无法再将油漆恢复成最初的状态。但在扩散模型中,我们可以依靠数学原理试图构建一个模型,该模型输入一张全是噪声的杂乱图案和我们想看到的画面的文字描述,便可以恢复成一张漂亮的图片。其基本思想是通过迭代前向扩散过程系统地、缓慢地破坏数据分布中的结构。然后,我们学习反向扩散过程,恢复数据结构,产生高度灵活且易于处理的数据生成模型。
该展项的设计是让游客体验利用扩散模型训练的生成模型,用户只需要给到一段简短的文本,即可生成一张图片,或者一段视频。同时我们还支持利用用户拍照的头像按照用户的要求进行风格转换,
生成卡通、科幻类的数字头像,让游客体验到图像生成模型的乐趣。
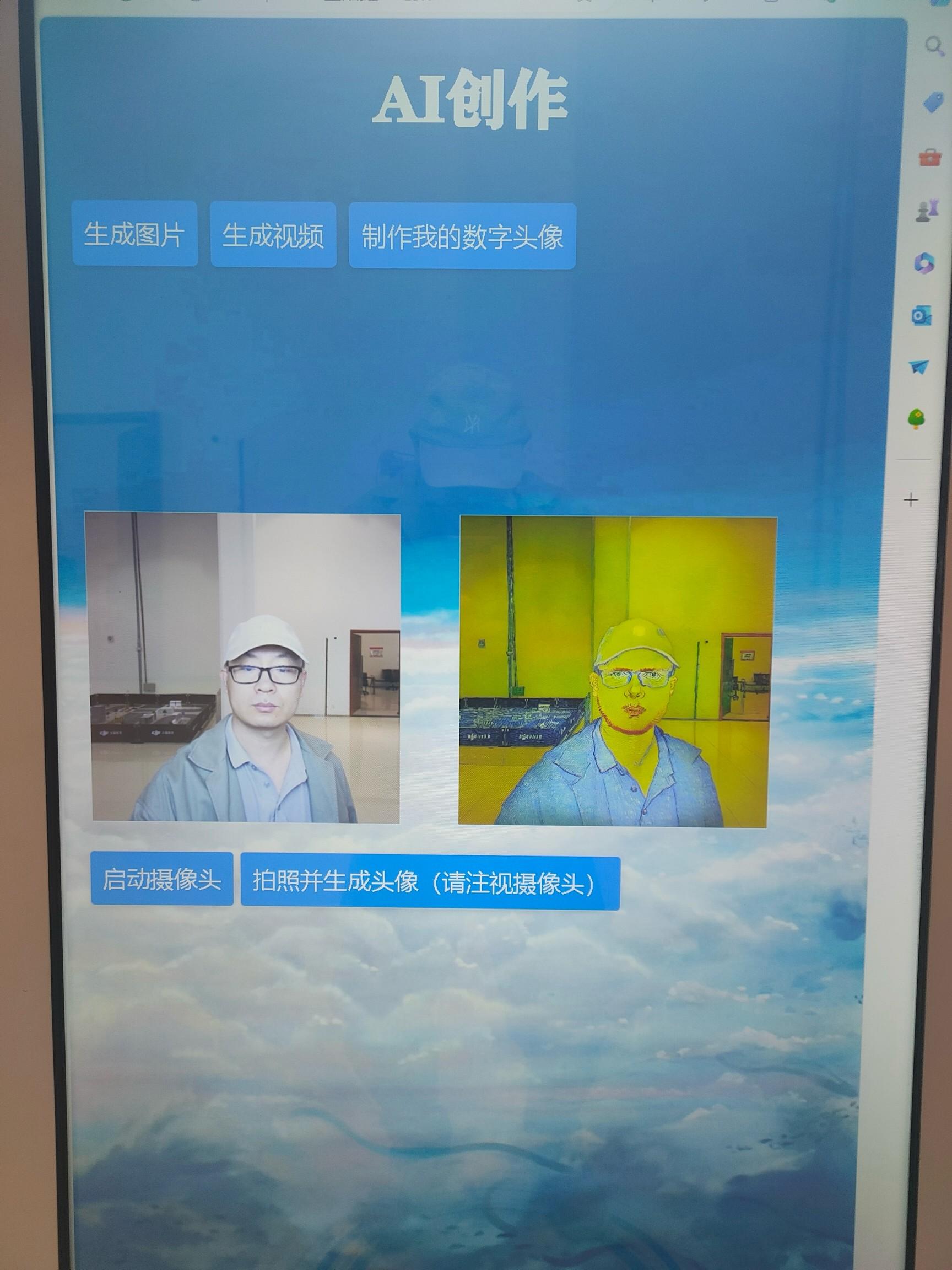
“AI创作”展品示意图
即使是没有绘画功底的人,也可以通过向AI描述自己想要的画面在很短的时间内来得到一张完成的图片。作为海报、插图等等。AI生成视频也在快速发展中,相信在未来我们能看见AI创造出更加绮丽丰富的虚拟世界。
2.3 我想对你说
该展项依赖的技术背景是ASR翻译,主要目的是让游客了解语音输入、识别、翻译的发展情况。
ASR在技术领域通常指的是“自动语音识别”(AutomaticSpeechRecognition),可以将人的语音转换成机器可以理解和处理的文本。在这种技术在识别语音之后,将其转换成一种语言的文本,再通过翻译技术转换成另一种语言的文本。这个过程经常用于多语言通讯和国际合作中,比如会议翻译、多语言客户支持等场景。在本次展览中,我们将其设计成了语音输入,然后自动翻译为英文,在界面上精准显示两种语言结果。
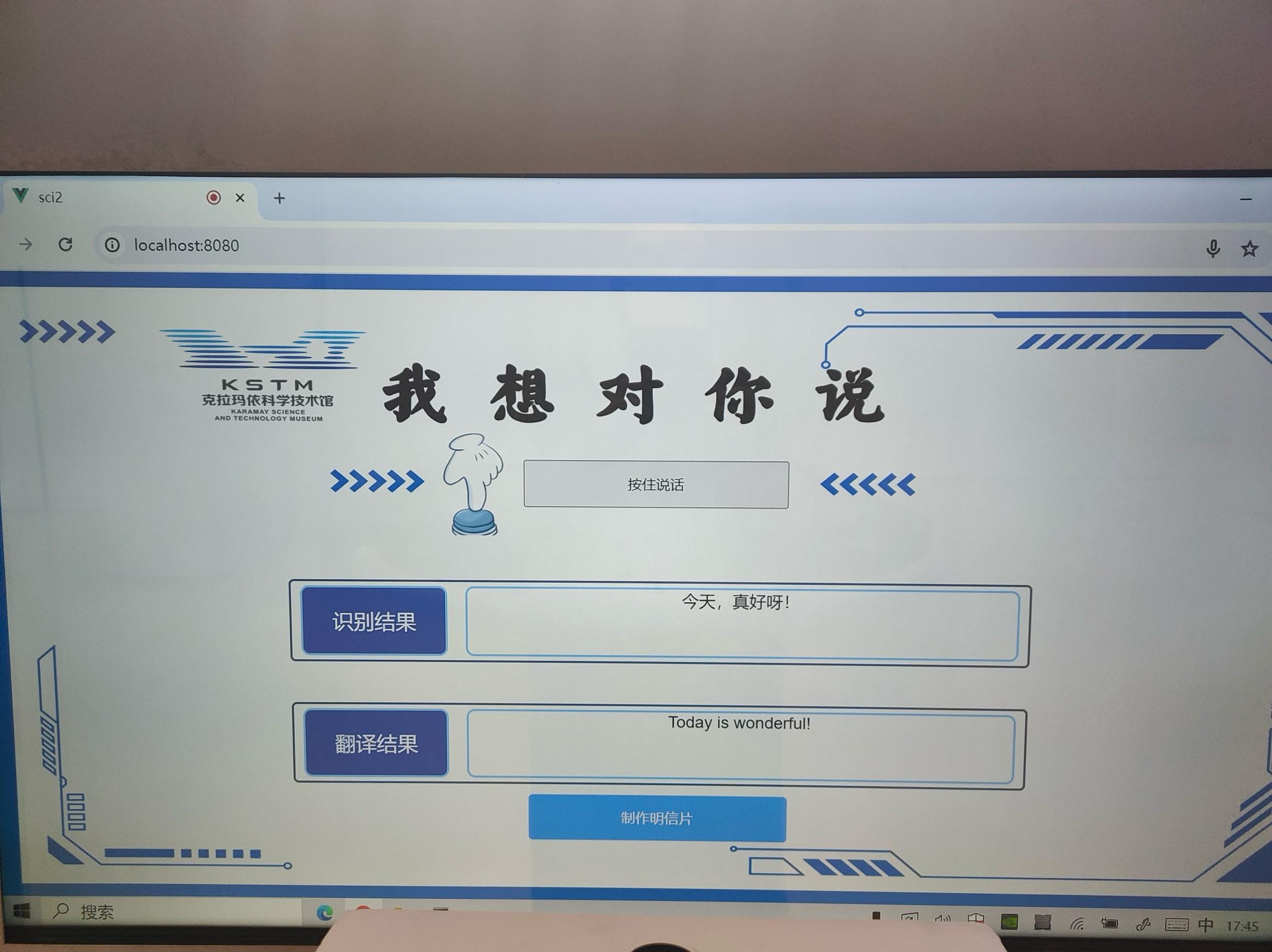
“我想对你说”展品示意图
该展项为了向儿童科普ASR翻译,搭建了一个简单的声音识别和翻译模型。用户点击“开始录制”并说出任意内容,松手后便可以完成录制,随后模型会自动分析并学习,将原结果和英文结果展示。用户可以选择自己喜欢的背景,将自己的话和翻译结果打印下来,作为纪念。
对于外语并不熟练、语言不通甚至是不认识文字的人,都可以利用这一项技术实现跨语言交流。对于ASR翻译,支持的语言种类十分广泛:英语、法语、阿拉伯语、西班牙语等都可以实现精准翻译;而且其应用场景非常广泛,可以实现更多语言种类的翻译,实现和外国友人无障碍交流;也可以更精准用于同声传译和商务会议辅助翻译等。
2.4 模拟配音
该展项依赖的技术背景是声音克隆技术,主要目的是让游客了解当前声音克隆技术的发展现状。
声音克隆的基本技术原理是基于语音合成和人工智能技术。它收集并分析目标人物的语音样本,然后使用深度学习和神经网络等技术来生成一个能够模拟目标人物声音的语音合成模型,产生与目标人物相似的语音,从而实现声音克隆。声音克隆技术的实际应用场景包括:语音助手:允许个人用户或者企业定制他们自己的语音助手,使其具有特定声音特征;虚拟代言人:可以为虚拟人物或品牌创建具有特定声音的虚拟代言人,用于广告、营销等用途;语音
合成技术:改善语音合成系统,使其更加自然、逼真,适用于多种场景,如有声读物、语音导航等。
该展项为了向游客科普声音克隆,搭建了一个简单的声音克隆模型。用户点击“开始录制”并阅读指定内容,再点击“停止录制”便可以完成录制,随后模型会自动分析并学习声音特征。随后,用户可以在文本框输入自己想听到的话,模型则会根据学习到的声音特征生成对应音频,并播放出来,从而实现声音克隆。
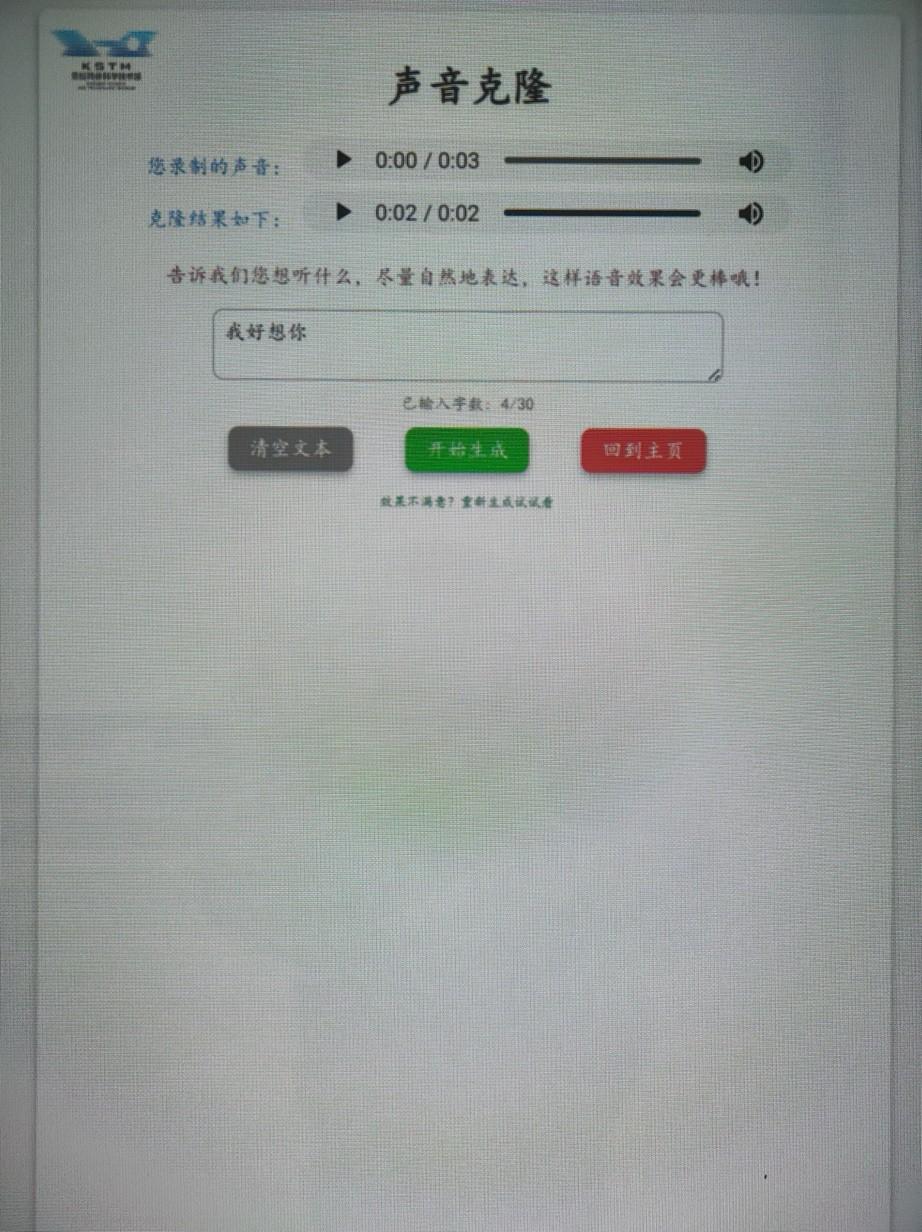
“模拟配音”展品示意图
如果声音克隆技术能够进一步提高语音合成的逼真度和个性化程度,并且在各种领域得到广泛应用,那么其市场潜力可能非常巨大,涵盖消费者市场、企业市场以及娱乐产业等多个领域。
2.5 大语言模型
该展项依赖的技术背景是大语言模型技术,主要目的是让游客通过与大语言模型对话,感受到近两年大语言模型的重大突破带来的巨大发展前景。
近两年来随着以ChatGPT为代表的大语言模型的兴起,大语言模型已经被广泛部署到产品的方方面面。基于其强大的语义理解能力,无论是作为聊天机器人,还是帮助用户做好文档总结、编写文档大纲,抑或是作为游戏的智能NPC提升玩家的游玩沉浸度,大语言模型都发挥了重要的作用。
该展项提供了两种使用方法,用户可以选择使用线上的ChatGPT,获得更加强大的对话能力,体会到大语言模型的魅力。用户也可以选择使用我们本地部署的大模型,来自阿里巴巴公司的千问模型。本地模型的好处是开源、可调整,在一定的技术支持下可以将模型定制化出我们想要的专用功能。

“大语言模型”展品示意图
大语言模型作为近两年最热门的AI技术,对该技术的深入了解是符合当今时代背景的。当前无数创业公司正在依赖该技术开发更加便利的产品,帮助我们在生活、工作中获得更高的效率,其被称为通往通用人工智能的一把钥匙,在可以预见的未来,该技术一定会对我们的社会带来翻天覆地的变化,因此通过向游客们普及该技术具有深刻的意义。

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国