

导语
自由能原理被认为是“自达尔文自然选择理论后最包罗万象的思想”,从第一性原理出发解释智能体更新认知、探索和改变世界的机制,被认为有可能成为智能的第一性原理的重要候选方案,并有望成为新时代复杂系统的大统一理论。自由能原理对强化学习世界模型、通用人工智能等前沿方向具有重要启发意义,本文介绍自由能原理在神经科学、人工智能等领域的应用。
关键词:自由能原理,主动推理,强化学习世界模型,强化学习探索,预测编码理论,预测加工理论
作者|牟牧云
编辑|梁金
目录
1. 智能的第一性原理
2. 意识理论:预测加工理论与预测编码理论
3. 强化学习世界模型与强化学习探索
4. 最后
1、智能的第一性原理
以ChatGPT为代表的大语言模型的诞生,让我们看到了通用人工智能的曙光。ChatGPT的核心原理在于训练一个参数庞大的神经网络,它能够从海量的文本数据中学习如何根据输入的一段文字预测下一个词语。然而,一些批评者质疑,这不过是模型通过庞大的参数量来记忆训练文本,类似于鹦鹉学舌,并非真正的智能,也缺乏创造力。但事实真的如此吗?或许预测这件事情并不像我们想象的这么简单。
图灵奖得主、深度学习之父Geoffrey Hinton,提出这样的观点:“为了精确预测下一个词,模型必须理解上下文,这涉及到对问题或对话内容的深入理解。因此,预测下一个词的行为实际上迫使模型去理解语境,这种理解方式与人类的思维方式有相似之处。”Hinton的学生、OpenAI前首席科学家、被誉为ChatGPT之父的IlyaSutskever,在多次采访中强调:“当我们训练一个大型神经网络来准确预测互联网上众多不同文本中的下一个单词时,我们实际上是在学习一个世界模型。”
世界模型(World Model)可以看作是一种高度抽象和压缩的信息表示,它能够捕捉并模拟现实世界中的关键特征和规律,从而使得智能体能够进行有效的预测和决策。这一观点可以被概括为“预测即压缩,压缩即智能”。然而,为何通过预测能够实现类似人类的语言理解和思考能力,人工智能算法背后仍然缺少一个原理性的解释。
这是因为,这些基于深度学习和大模型的人工智能系统都存在一个共同的弱点:它们大多是通过工程技术手段构建的,缺乏对智能本质的深刻理解。当前人工智能研究偏重于实现技术细节,却忽略了真正智能的基本原理。例如,现有人工智能系统能耗巨大,而人类大脑却以远低于此的能耗完成各种复杂任务。因此,我们迫切需要寻找智能的第一性原理。
在这方面,Karl Friston 的自由能原理可能成为智能的第一性原理的重要候选方案。自由能原理提出了生物系统如何通过减少自由能来理解和适应环境的理论框架。它将系统视为试图最小化与外部世界的差异,以最有效地预测和适应外部环境的变化。通过最小化自由能,系统调整内部表示和行为,实现更好的环境适应性。这一理论不仅适用于认知神经科学和人工智能领域,还可应用于其他领域,如机器学习和自动控制。
自由能原理不仅可以解释智能现象,还可以解释从物质到生命的各种现象,可能成为新时代复杂系统的大统一理论。通过自由能原理,我们可以更深入地理解智能系统如何运作,为未来的人工智能研究和发展提供更加深刻和基础的理论支持。
自由能的概念起源于统计物理和热力学,后被引入机器学习和信息加工领域,表示系统内部表征状态与环境真实状态间的差异。自由能原理认为,所有可变的量,只要作为系统的一部分,都会为最小化自由能而变化。自由能原理提供了一个统一的规范性理论,用于理解和模拟复杂系统的自组织、自适应行为,特别是在生物系统和大脑功能方面。这一原理不仅解释了感知、行为和学习的统一过程,还对复杂系统建模、认知过程和意识的理解,以及生物和人工智能系统的设计原则产生了深远影响,跨越了生物学、神经科学、心理学和人工智能等多个领域,为揭示这些系统背后的统一原理提供了有力的工具。
这篇文章我们介绍自由能原理作为一种高度抽象的底层原理,在认知神经科学、强化学习等领域的广泛应用。
2. 预测加工与预测编码理论
自由能原理是一种广泛适用的理论,它认为所有非平衡稳态系统——从微小的细菌到复杂的动物,甚至包括人类社会和生态系统——都在追求自由能的最小化。当这一原理应用于人脑时,它激发了一系列具体的理论和实践框架,例如预测编码理论(Predictive Coding)和预测加工模型(Predictive Processing)。预测编码理论和预测加工模型是两个紧密相关的概念,预测编码理论提供了一个关于大脑如何运作的高层次描述,而预测加工模型则提供了一个具体的计算框架来实现这一理论。它们在认知科学和神经科学中描述了大脑如何处理信息。
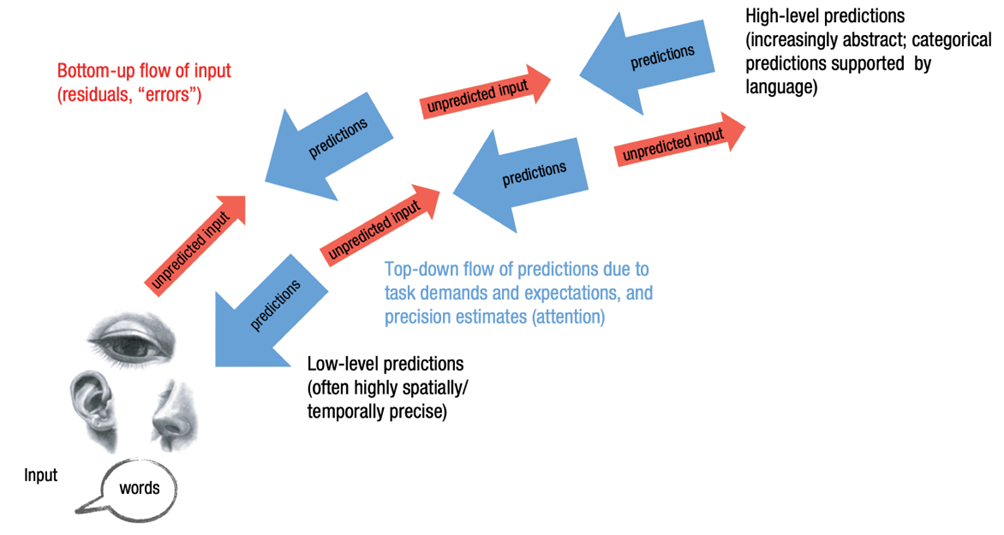
图1. 预测加工模型
预测编码理论认为,大脑通过不断生成关于外部世界和内部状态的预测,并将其与实际感觉输入相比较来执行其功能。这种比较如果出现偏差,将产生预测误差,这一误差信号随后会被反馈至大脑的更高层次,用以调整和优化内部模型,目的是减少未来的预测误差。这个过程体现了自上而下的预测信息流和自下而上的感觉信息流的交互。
预测加工模型可以看作是预测编码理论的一个具体实现,它提供了一个计算和数学框架来描述大脑如何通过预测和更新来处理信息,这一模型和上述提到的贝叶斯定理出发的主动推理路径一脉相承,为解释大脑的认知行为现象提供了有力工具。
在实证研究中,重复抑制现象(Repetition suppression)是一个典型例子,它在多种情境下均有体现,比如EEG研究中的失匹配负相关(Mismatch Negativity)和fMRI研究中的面部处理。重复抑制现象揭示了当被试面对重复出现的刺激时,其诱发反应会减少或受到抑制。根据自由能原理,不可预测或不连贯的刺激会引发比熟悉或连贯的刺激更大的预测误差,这一点在相应脑区的激活水平上得到了实证支持[3]。
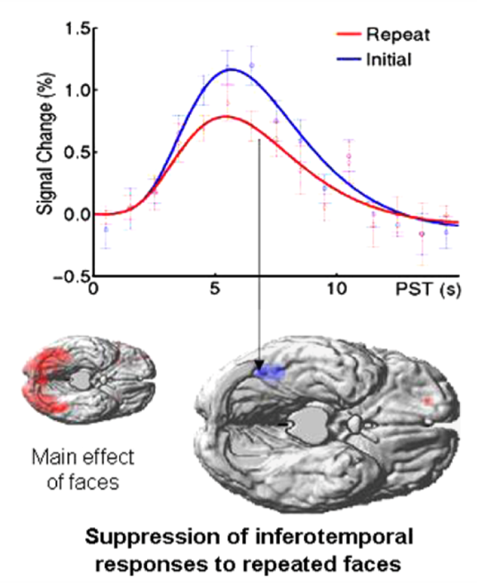
图2. 向被试呈现相同面孔时,第一次呈现(蓝色)和第二次呈现(红色)的反应
不论是预测编码理论还是预测加工模型,都认为预测在大脑认知活动中扮演着重要(甚至是唯一重要)的功能,这与文章开头提到的“预测即压缩,压缩即智能”的观点形成了共鸣,进一步强调了预测在智能行为中的基础性地位。对于自由能原理在大脑认知以及意识领域应用感兴趣的读者可以参考《预测心智》和《预测算法》两本书。
3. 强化学习世界模型与强化学习探索
人工智能领域中强化学习(ReinforcementLearning,简写为RL)与以自由能原理基础的主动推理框架存在紧密联系,智能体的感知与行动是二者共同关心的话题。
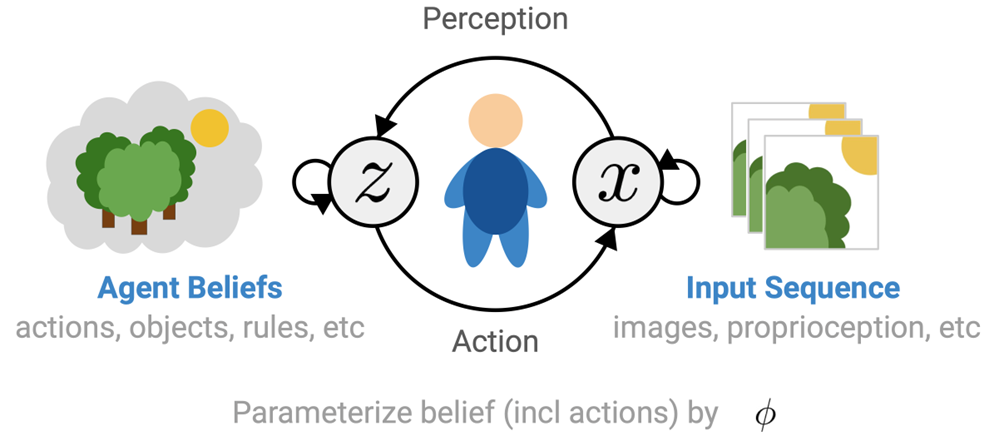
图3. 人工智能领域中的强化学习与以自由能原理基础的主动推理框架存在紧密联系
强化学习中关系的核心问题是智能体如何通过观测和行动与环境进行交互以获得最大的累积奖励,强化学习方法可以分为无模型强化学习(Model-free RL)与基于模型的强化学习(Model-based RL),后者又被称为世界模型(WorldModel),这与主动推理框架中智能体内部的生成模型一致。在主动推理框架中变分自由能最小化的过程可以看作是在模型预测准确性与模型复杂度之间进行平衡,这在强化学习中对应世界模型的学习。主动推理框架中预期自由能最小化的过程包括信息增益与偏好两个方面,分别对应了强化学习中探索与利用的平衡。
在世界模型中,智能体首先通过观测数据推断隐状态的动力学模型,学习世界模型后,智能体基于此模型进行决策规划以及探索。在面对复杂的环境时,智能体往往需要学习一个多尺度的世界模型,世界模型的多尺度特性涉及时间和空间维度,以及状态和动作两个重要层面。
尽管在具体实现的细节上存在差异,我们仍能看到到两者之间核心机制的高度相似性。这一发现启示我们,不论是自然演化下的生物智能,还是由人类设计的人工智能,它们在运作的底层逻辑上或许殊途同归。另一方面,强化学习领域研究中,新算法的设计大多依赖启发式的想法,缺乏第一性原理。从自由能原理出发,为不同强化学习算法提供了一个统一性的视角,对强化学习与自由能原理之间更深层联系感兴趣的读者可以参考[8,9]。
4. 最后
当然,自由能原理这一理论也并非完美,它仍然面临许多争议。作为一个高度抽象并声称适用于所有非平衡稳态系统的理论,其可检验性是一个受到广泛质疑的点。当这一原理应用于具体系统时,往往需要研究者根据具体的研究问题提出新的假设,这正是自由能原理以及主动推理框架规范性的一面。不过当我们为特定问题定义了状态空间和生成模型,就可以从规范性理论过渡到过程理论,进而产生具体且可检验的实证预测。
自由能原理还是一个处于不断发展和完善阶段的理论,笔者受限于自己的知识视野,对于该理论的阐述难免存在不够准确的地方。这一系列文章也是希望以介绍的方式与大家共同学习,促进对这一原理更深入的理解。欢迎感兴趣的朋友和我们一起探索!
参考文献
1. HintonG E, Dayan P, Frey B J, et al. The" wake-sleep" algorithm forunsupervised neural networks[J]. Science, 1995, 268(5214): 1158-1161.
2. DayanP, Hinton G E, Neal R M, et al. The helmholtz machine[J]. Neural computation,1995, 7(5): 889-904.
3. FristonK, Kilner J, Harrison L. A free energy principle for the brain[J]. Journal ofphysiology-Paris, 2006, 100(1-3): 70-87.
4. FristonK, Ao P. Free energy, value, and attractors[J]. Computational and mathematicalmethods in medicine, 2012, 2012.
5. KarlF. A free energy principle for biological systems[J]. Entropy, 2012, 14(11):2100-2121.
6. ParrT, Pezzulo G, Friston K J. Active inference: the free energy principle in mind,brain, and behavior[M]. MIT Press, 2022.
7. ClarkA. Surfing uncertainty: Prediction, action, and the embodied mind[M]. OxfordUniversity Press, 2015.
8. Hafner D, Ortega P A, Ba J, et al. Action and perception asdivergence minimization[J]. arXiv preprint arXiv:2009.01791, 2020.
9. Mazzaglia P, Verbelen T, Çatal O, etal. The free energy principle for perception and action: A deep learningperspective[J]. Entropy, 2022, 24(2): 301.
本文为科普中国·创作培育计划扶持作品
作者:牟牧云
审核:张江 北京师范大学系统科学学院教授
出品:中国科协科普部
监制:中国科学技术出版社有限公司、北京中科星河文化传媒有限公司




 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国