

出品:科普中国
作者:王琛(中国科学院计算技术研究所在读博士)
监制:中国科普博览
编者按:为展现智能科技动态,科普中国前沿科技项目推出“人工智能”系列文章,一窥人工智能前沿进展,回应种种关切与好奇。让我们共同探究,迎接智能时代。
在过去的两年中,OpenAI的ChatGPT引爆全球。就在大家翘首以待GPT-5的发布时,9月13日凌晨,OpenAI发布了OpenAI o1,致力于解决复杂问题的新推理模型。

(图片来源:OpenAI官网)
从比赛排名看OpenAI o1有多强大
上月初,OpenAI的首席执行官Sam Altman发布了自家花园的草莓的照片。随后,据知情人士的消息透露,OpenAI将发布新的AI模型,内部代号为Strawberry(草莓)。
草莓模型的前身是Q*,Q*暗示其结合了两种著名的人工智能方法——Q-learning和A*搜索。据传Q*过于强大的能力使得研究人员担心它会对人类构成潜在的威胁,是此前 OpenAI内乱风波的关键原因之一。

Sam Altman发布的草莓照片
(图片来源:Sam Altman 的 X(twitter) 账号)
OpenAI发布的OpenAI o1模型正是草莓模型。由于它在复杂推理问题上取得的重要进步,OpenAI重新从1开始计数,将新模型命名为OpenAI o1。据OpenAI发布的信息,OpenAI o1可以像人类一样,在回答问题前使用更多时间思考。因此o1模型可以通过推理在科学、编程和数学领域解决比先前更难的问题。
与先前OpenAI最新的模型GPT-4o相比,OpenAI o1在数学竞赛、编程竞赛,以及博士基准的科学问题中取得了显著提高,展现了它在复杂推理任务中的强大能力。它在编程竞赛 (Codeforces) 中排名89%,在美国数学奥林匹克预选赛 (AIME) 中跻身全美前500名,并且在物理、生物、化学的基准问题(GPQA)上的回答准确度超过了人类博士。
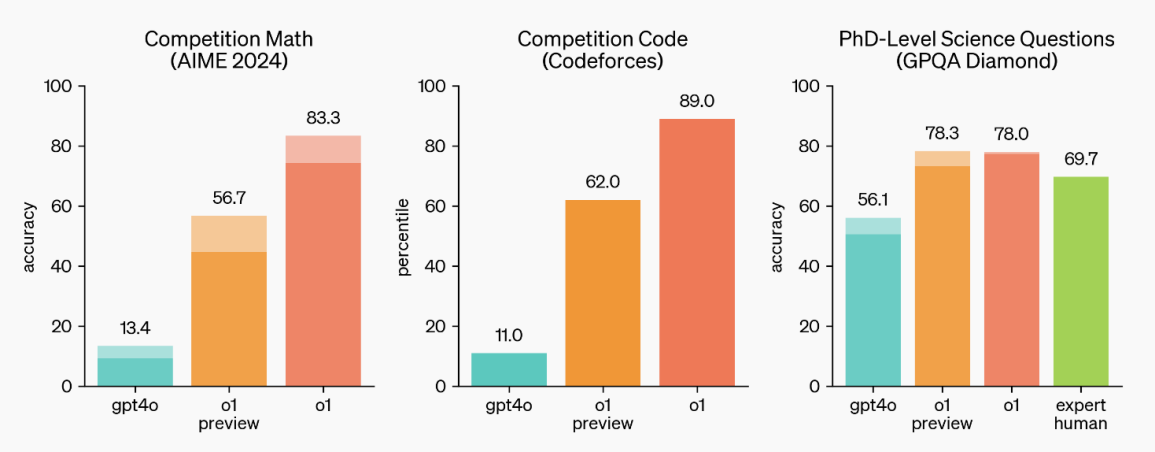
OpenAI o1在数学、编程、科学问题上和GPT-4o的对比
(图片来源:OpenAI官网)
OpenAI o1的秘密武器——基于思维链的强化学习
OpenAI o1之所以能取得远超GPT-4o的推理能力,关键就在于它使用了基于思维链(Chain of Thought)的强化学习。就像人类在回答一个困难问题之前可能会进行长时间思考一样,OpenAI o1在尝试解决问题时,也会使用思维链。通过思维链,模型会将任务分解成更为简单的步骤,一步一步进行解决,这比让模型直接输出问题答案通常更加准确。
其实思维链并不是一个新的概念,早在GPT-3发布以前,科研人员已经发现了思维链可以引导大语言模型进行推理。
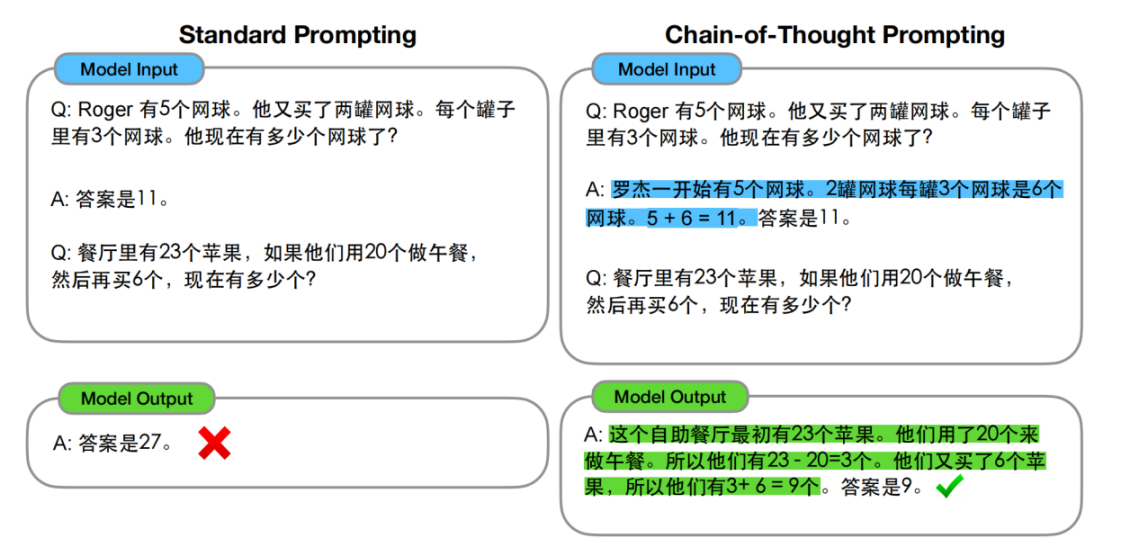
大语言模型使用思维链的示例
(图片来源:根据参考文献2翻译)
上图的示例有两组大语言模型的输入和输出,在输入中,首先向模型输入了一个计算网球个数的问答,然后向模型提问了一个类似的问题,让模型计算苹果的个数。
下方左侧是直接的问答,模型给出了错误的回答。下方右侧是使用思维链的问答,研究人员对向模型输入的关于网球个数的问答做了补充,向模型展示了得到网球个数的推理过程,再让模型去回答苹果的个数。
这一次,模型正确地通过推理计算出了苹果的个数。这样引导模型生成问题的一系列中间推理步骤的方法称为思维链。通过思维链,可以让大语言模型在解决问题时将推理步骤详细、直观地展示出来,不仅提升了大语言模型在解决推理问题时的准确性,也让大语言模型的回答有了可解释性,不再是完全的黑盒。
在GPT-3发布之后,人们进一步发现了这种提示(Prompt)的重要性。对于能力较强的大语言模型,在提问时甚至不需要给出类似前面计算网球个数的示例,只需要告诉模型“让我们一步一步思考”(Let's think step by step),就可以提升模型处理复杂推理问题的能力。
以上的尝试都是在向模型提问时加入引导。如果思维链如此有用,是否可以在模型构建与训练时就将思维链固化在模型内部呢?这就是OpenAI o1做出的尝试。
OpenAI o1的强化学习与新的Scaling Law(尺度定律)
GPT模型在回答问题时,本质上是在进行“文字接龙”,它依据训练时大量的统计概率数据,估计出在模型的输入下续写怎样的回答是最合适的。
为了让大语言模型学习如何使用思维链,而不是仅依据概率进行续写,OpenAI o1使用了名为强化学习的机器学习方法。
强化学习是指模型以“试错”的方法进行学习,在训练的过程中并不告诉模型标准结果是什么,而是告诉模型它结果的好坏程度。当模型的结果是对的时,模型会在以后的输出中倾向于采取这种结果;当模型的结果是错的时,它在以后的输出中倾向于避免这种结果。在经过多轮的试错以后,模型会依据自身的经验学习到一套判断标准。
强化学习这种不给出标准答案的学习方式适用于复杂环境下的决策问题,例如机器人控制、金融交易、棋类游戏等领域。在这些领域中,我们往往无法给出一个标准意义上的正确答案,只能得知采取一个行动后的结果。例如,机器人是否摔倒、金融交易是否获利,游戏是否胜利。
强化学习的一个著名的案例是2016年Deepmind开发的围棋AI AlphaGo。在围棋领域中,可能的局面总数甚至超过了可观测宇宙中的原子总数,即使是顶尖围棋高手也不能判断出任意情况下最好的下法是什么。因为围棋过于复杂,无法通过穷举获得最佳的下法。在 AlphaGo出现以前,人们一度认为人工智能在围棋上不可能战胜人类。
AlphaGo使用强化学习进行训练,它自己和自己下棋,并从每一局棋的胜负中学习到经验。并不需要人类告诉它哪一步是对的,也不需要学习任何过往人类的棋谱,它在短短数天的训练后就达到了人类棋手望尘莫及的水平。
在AlphaGo决策的过程中,它首先对局面进行大致判断,判断在哪里下棋更有可能使自己获胜。这种感觉或者说直觉,通常被人类称之为棋感。在大致判断出在哪里下棋更可能有利后,AlphaGo对这些不同下法的后续可能性进行进一步计算,并从中选择最佳的下法。
因此,AlphaGo的实力主要有两个影响因素,包括对局面进行判断的能力和对可能下法进行计算的计算量。其中,模型的强化学习过程可以提升模型对局面进行判断的能力。
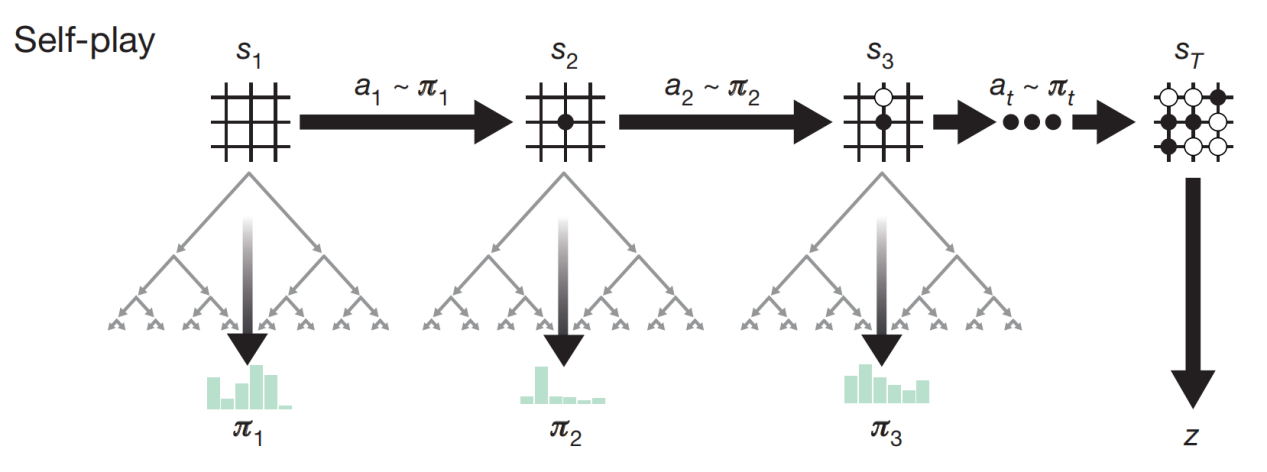
AlphaGo的自我对弈
(图片来源:参考文献1)
在OpenAI o1的训练中,通过强化学习,OpenAI o1学会磨炼其思维链并完善其使用的策略,它学会将困难的问题分解为更简单的步骤,在分析过程中认识并纠正错误。这个过程极大地提高了模型的推理能力。
在学会了使用思维链之后,OpenAI o1的输入不再需要人为引导它使用思维链。相反,OpenAI建议在使用OpenAI o1时保持提示的简单和直接,并避免使用思维链提示。
研究人员在对OpenAI o1的测试中发现,增加强化学习训练的时间和在推理时增加更多的思考时间都可以让模型的性能得到改善,这和前面提到的AlphaGo的实力的影响因素相一致。
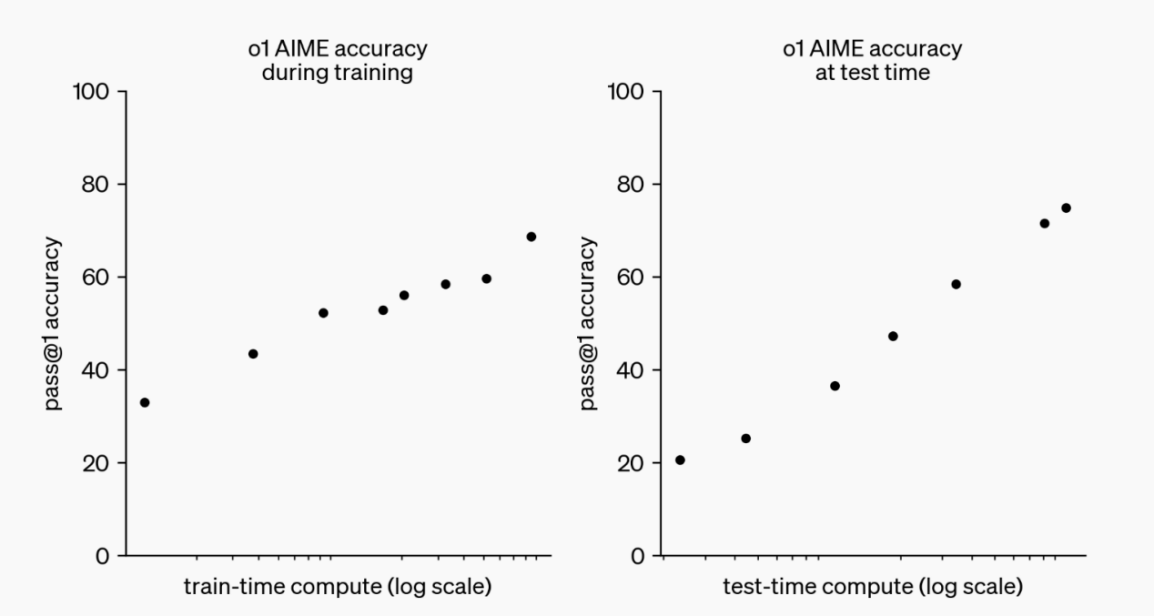
OpenAI o1的Scaling Law
(图片来源:OpenAI)
OpenAI 的研究人员在2020年发现了大语言模型的Scaling Law(尺度定律),大语言模型的性能会随着模型大小、训练集大小、训练时的计算量的增加而增加。
OpenAI o1展现了新的Scaling Law,在提升模型性能方面,它还可以通过增加推理时间使得模型获得更强的性能,这为未来大语言模型进一步发展提供了新的可能。
OpenAI o1系列目前包含三个模型,o1,o1-preview,o1-mini。它们的模型大小不同,o1最大并且拥有最强的推理能力,o1-mini最小但在使用时消耗较小的成本。它们在数学竞赛上的表现如下图所示,o1-mini在数学竞赛上的表现甚至强于o1-preview,但它在其他需要非STEM(科学、技术、工程、数学)知识的任务上会表现较差。同时,随着推理时间的增加,三个模型的表现都会有所提升。
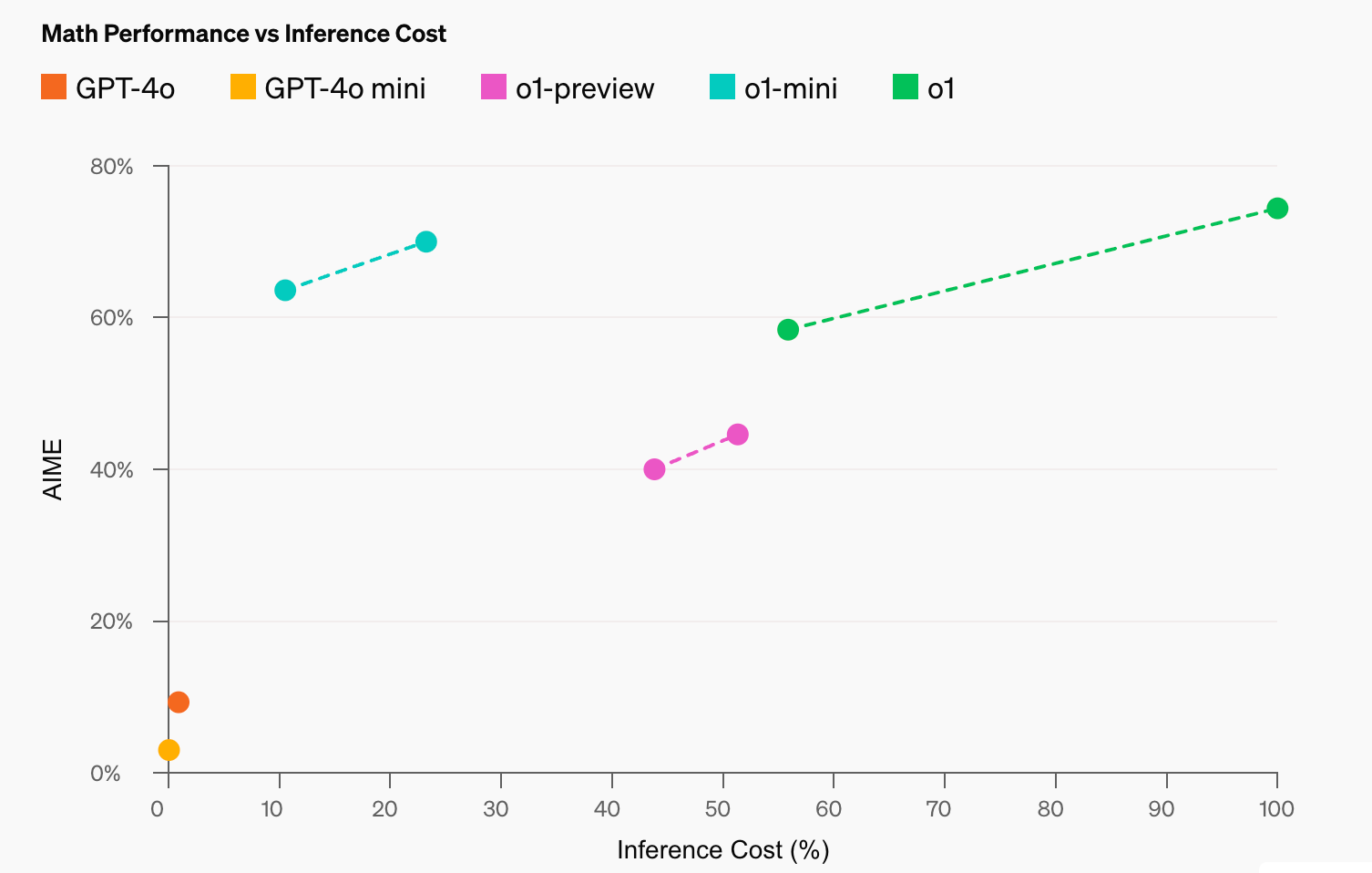
OpenAI o1不同版本的模型在数学竞赛上的表现
(图片来源:OpenAI)
OpenAI o1会带来更多安全问题吗?
OpenAI o1模型的突破,无疑更进一步提升了大语言模型的能力。OpenAI曾提出构建通用人工智能(AGI)的五个阶段,第一阶段是实现可以和人交流的人工智能,第二阶段是实现具有推理能力的人工智能。ChatGPT达到了第一阶段的目标,而OpenAI o1的出现使得我们离第二阶段更近了一步。
在OpenAI o1展现出强大推理能力的同时,正如研究人员对Q*的担心,人们不禁想问OpenAI o1是否会带来更多的安全性问题。
OpenAI的报道中指出,思维链为提升模型的安全性提供了新的机会。在训练过程中,可以把人类的价值观集成进模型的思维链之中,让模型拒绝执行有害的行为。同时,思维链可以让我们以清晰的方式观察模型的思维,从而增强模型的安全性。
未来,也许超乎想象
目前,OpenAI o1的preview版本和mini版本已经开放给用户使用,随后也将添加浏览、文件和图像上传等实用的功能。它在真实的场景中的效果如何有待大家进一步地体验和测试。总而言之,OpenAI o1在推理能力上的重要进步,或许意味着我们离通用人工智能更近了一步。未来人工智能将会走向何处,能否为造福人类社会带来更大的贡献,让我们继续保持期待。
参考文献:
1.Silver, D., Schrittwieser, J., Simonyan, K. et al. Mastering the game of Go without human knowledge. Nature 550, 354–359 (2017). https://doi.org/10.1038/nature24270
2.https://proceedings.neurips.cc/paper_files/paper/2022/hash/9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.html


 2024-09-24
2024-09-24

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国