

0 引言
生物免疫系统是脊椎动物为了保护机体抗御病原体等“非我”(non-self)的侵害所进化出的防御机制。鉴于其具有自学习、记忆机制、模式识别、动态自适应、动态鲁棒性和并行性等优越的特质,生物免疫系统为解决实际复杂工程问题提供了大量的仿生灵感。人工免疫系统(Artificial Immune System, AIS)通过模拟生物免疫系统功能、原理和模型来构造算法,被广泛应用于函数优化、异常检测、模式识别和工业工程等诸多领域。
由于生物免疫系统自身的复杂性,形成了多种免疫学说。其中,Burnet 在 1959 年提出克隆选择学说构建了克隆选择算法的基础。克隆选择学说解释了在抗原刺激下适应性免疫反应的基本特征,其基本思想是只有那些能识别抗原的细胞才被选择进行增殖,而那些不能识别抗原的细胞则不被选择,被选择的细胞通过增殖和超变异的过程提升其亲和度直至达到亲和度成熟。根据克隆选择理论,De Castro 等通过仿生免疫反应中的亲和度成熟过程,提出了克隆选择算法 CLONALG,成功应用于字母识别、多模态函数优化、组合优化和 TSP 问题等,掀起了免疫克隆选择算法的研究热潮。
随着研究的深入,克隆选择算法被不断改进,并与其他策略混合,在多模态优化、约束优化、动态优化、多目标优化、模式识别和路径优化等领域取得了亮眼的成绩。本文重点阐述克隆选择算法的基本原理、研究现状和需要进一步研究的热点问题。
1 克隆选择算法
由于生物免疫系统庞大且复杂,为便于模型设计,从计算的角度可以将生物免疫系统原理进行简化。“非我”的物质被统称为抗原,免疫系统受抗原刺激引发免疫应答产生抗体。抗体能与抗原产生特异性结合。抗体通过其抗体决定基和抗原的抗原决定基之间的模式互补匹配,来与它能识别的抗原结合。结合的强度取决于模式匹配程度,这种结合力称为亲和度。亲和度越高,抗原与抗体之间的关联越紧密。特定的抗体分子对不同的抗原具有不同的亲和力。抗体也能和其他抗体结合,这样抗体便具有识别抗原又被其他抗体识别的“双重身份”。如图 1 所示,在生物免疫系统克隆选择过程中,与抗原亲和度高的抗体被选择,然后通过克隆快速增殖分化,并通过超变异调整自身抗体与抗原亲和度直至亲和度成熟(affinity maturation),产生最佳抗体,最终消除抗原。一些抗体会转化为记忆细胞,当遭遇相同或相似抗原攻击时能迅速反应。
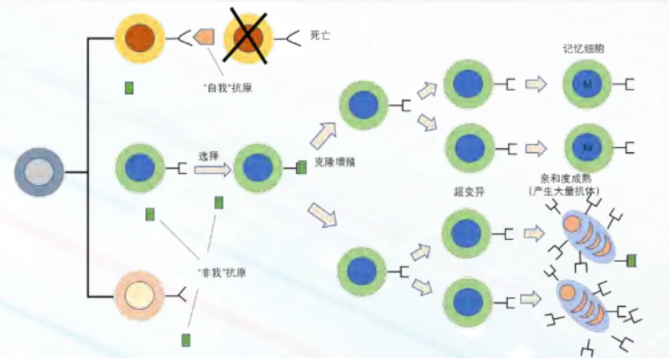 图 1 生物免疫系统克隆选择过程
图 1 生物免疫系统克隆选择过程
克隆选择算法(Clonal Selection Algorithm, CSA)是通过仿生生物免疫系统通过克隆选择实现适应性免疫过程的计算模型。克隆选择算法的基本框架如算法 1 所示。通常情况下,需要解决的问题被映射为抗原,问题的解被映射为抗体。
算法 1 克隆选择算法基本框架
-----------------------------------------------
输入:种群数目,相关参数设定等
输出:问题的解
------------------------------------------------
Step 1: 初始化:产生初始抗体种群
Step 2: 亲和度计算:计算抗体 - 抗原亲和度,即抗
体的适应度值
Step 3: 选择:选择 m 个与抗原亲和度高的抗体
Step 4: 克隆:对所选择的抗体进行克隆操作
Step 5: 超变异:对克隆个体实施超变异操作
Step 6: 对新产生的抗体的亲和度进行评估
Step 7: 选择亲和度高的 n 个抗体到下一代
Step 8: 受体编辑:随机产生 d 个抗体,加入到种群中
Step 9: 终止条件判断。如果终止条件未满足则算法
继续,否则结束,输出最优抗体及其适应度值。返回 Step4
2 关键算子定义及其改进
2.1 亲和度
亲和度是对抗体质量进行评价的度量。根据不同的问题和编码方式,亲和度的定义各有不同。在模式识别和路径优化等问题中,通常采用二值编码或者整数编码等方式。此时,通常选择相似度距离计算方法,比如汉明距离和曼哈顿距离作为亲和度的衡量标准。对于连续优化问题,通常以实数编码实现,一般采用目标函数本身,或者是欧式距离来衡量。在处理多模态问题时需要同时考虑抗体与抗原的匹配度,以及抗体的多样性,亲和度被细化为抗原 -抗体亲和度和抗体 - 抗体亲和度并分别定义。
2.2 克隆
克隆是无性繁殖,复制自身的过程。克隆选择的过程如图 2 所示。在克隆增殖过程中,抗体克隆子代的数目与抗原的亲和度值正比,即越优秀的个体产生的克隆子代越多。因此,在算法实现时,克隆子代的数目也遵循与其比例克隆的定义方式。比例克隆在当前最优的局部增加搜索,能增强局部搜索能力。如果优化过程旨在单个抗体种群中定义多个最优值,那么可以选择种群中的所有抗体参与克隆过程。此时,比例克隆不再适用,新的克隆个数被重新定义为每个抗体都将拥有相同的克隆数目,即等比例克隆。
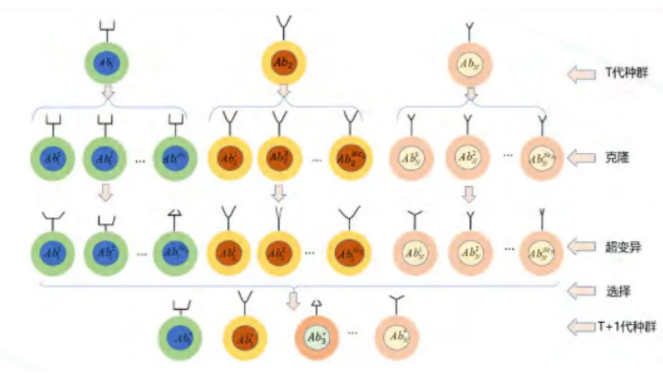
图 2 克隆选择算法中的克隆、超变异和选择过程
相较于遗传算法的两个父代通过交叉产生两个子代(2-2),粒子群算法一个父代通过位置更新生成一个子代(1-1)的产生方式,克隆操作的一个父代在一次迭代中就产生了多个子代(1-Nc)。这种方式虽然为产生更优秀的子代提供了更多的可能性,但显然也带来了计算资源的大量消耗。因此,为节约计算资源,有时会给克隆数目增加上界的阈值限制。极端情况下,克隆个数被设定为 1 个,这与 1-1 的设定在生成子代数目上几乎一致。
2.3 超变异
超变异是指高频的变异,抗体通过这种高频的变异修改自身可变区域结构,以期提升与抗原的亲和度。不同于遗传算法中的交叉操作,超变异直接在单个父代上进行,随机选择一个或者一段基因位进行改变,能显著增加抗体的多样性。在克隆选择过程中,超变异的频率一般遵循与抗体的亲和度成反比的规律,即适应度高的个体其变异的频度越低。
在遗传算法中,变异是与交叉算子配合使用的,变异频率通常较低,而且变异的主要的是增加算法的跳出局部最优的开拓能力。而在克隆选择算法中,变异算子作为主要算子之一,需要同时兼顾局部的勘探能力和全局的开拓能力,因此其设计更为复杂,每个抗体的突变率可以各不相同。在亲和度低的地方,则突变率较大,增加全局开拓能力;而在亲和度高的地方,变异率较低,增加局部勘探能力。
在克隆选择算法中,不同编码方式有不同变异算子的实施方式。对于二值编码或者整数编码,往往采取某些基因位或者基因段上值的改变,而对于实数编码其操作方式更加多样,常用的方式有采用亲和度的负指数函数,也有高斯变异和柯西变异等方式。超变异的实施主要集中在控制变异的步长上。在具体问题背景下,超变异的设定有时也与循环次数等相关,即变异的步长随着迭代次数的增加变小,从全局搜索逐渐到局部搜索。
2.4 选择
选择是指新产生的子代会以一定的生存几率存活或者死亡。一般来说,适应度值高的个体被选取到下一代继续生存的几率更大。在实际操作中,常用的方法有以下几种。
(1)轮盘赌选择:它属于比例选择操作,首先将适应度值归一化,然后把概率分布看作一个轮盘,轮盘的每一个切片的大小都与归一化后的个体选择概率成比例,选择的过程如同旋转轮盘,它停止旋转时,最上方的切片对应的个体即被选择。
(2)锦标赛选择:锦标赛选择从群体中随机选择 nts 个个体作为一组,其中 nts
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国