趣味漫画解读人机大战:机器人真能取代人类了?科普中国头条推送 2017-12-18 |
最近各个网路上被一场正在上演的“人狗大战”纷纷刷屏…比赛还在继续,但阿尔法狗目前以3:1胜韩国棋手李世石的事迹已经引起了众多网友的热议。今天就让我们就来聊聊关于这只阿尔法狗的那些不得不说的事儿……

这不是《疯狂动物城》里面最近出风头的狐狸吗?阿尔法狗虽然被中国网友们“亲切的”称为是狗狗,但事实上它既不是一个机器人,更不是一只会下围棋的狗。你可以想象它是任何的样子,所以是你喜欢的狐狸也不为过。
与“国际象棋高手”“深蓝”相似,阿尔法狗是由人类研发的一个专门针对围棋的算法程序软件。而就是这样一个软件到底是如何在围棋这个号称人类的游戏巅峰的游戏中夺魁并打败人类的呢?

由于围棋过于复杂,所以就先让我们拿简单的井字棋来举例。我们先行一棋开局,而再轮到程序时,它将会有8种不同的地方选择落子,然后轮到我们,然后程序…如图类推,几个回合后,总有一方获胜或是平局结束这场棋局。简单讲,每次下棋的步骤就抽象成搜索空间的一条路径了。
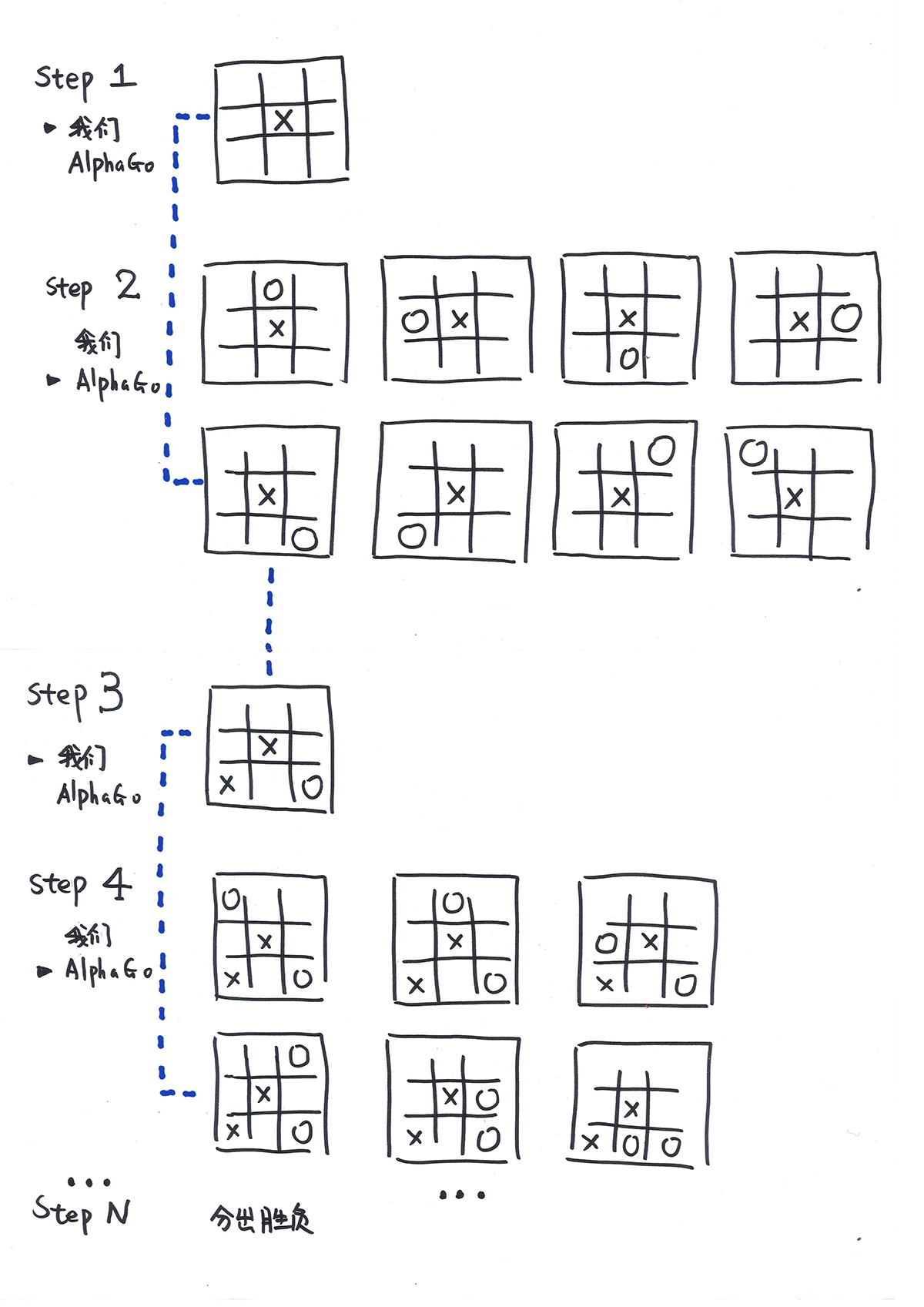
然而游戏最终目的就是获胜,怎么才能让程序在所有落子的可能性中选择那个最可能接近胜利的一步呢?这就是我们接下来要讲到的关于阿尔法狗软件程序的核心算法或者是它的厉害武器。

先来说说第一种厉害武器,叫做策略函数,是通过有监督学习来训练的。 有监督学习可以理解为计算机基于人类的经验来进行学习。

就像孩子通过父母传授的经验来认识世界,阿尔法狗可以通过学习以往棋局里多数人类为了获取胜利在这一步的落子的地方来进行这一步落子的选择。

第二种厉害武器,叫做评价函数,是通过增强学习来训练的。 增强学习的本质是通过最终得到的结果来判断过程的好坏从而进行学习。这个其实和我们训练狗狗是一个道理,当狗狗做对时,我们会给他鼓励,当它做错时我们则会惩罚它从而让它记住达到训练目的。
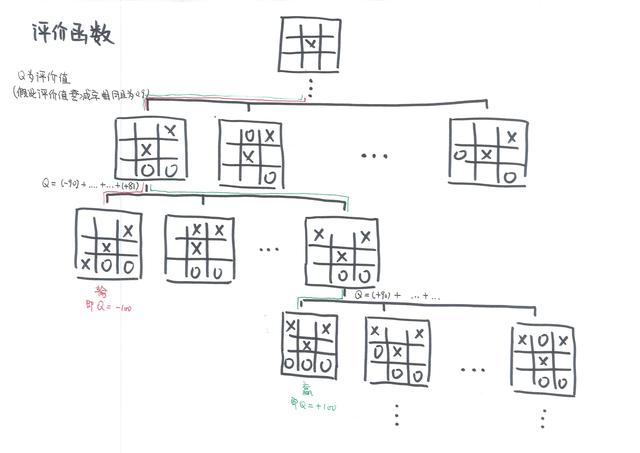
阿尔法狗也是如此,它可以通过最终各个胜负的棋盘局反推每一步落子的“好坏”的几率,从而与人下棋时步步逼近胜利。图中告诉我们,如果程序下赢了就沿着路径逐步返回正分数的奖赏,如果输了就逐步返回打负分数的惩罚,分数呢会随着返回步数的长度来衰减,之后每个状态的分数可以通过简单加和求得。

阿尔法狗就是基于这厉害武器来运行的,当然,由于围棋要比井字棋复杂得多得多, 这也就需要将策略函数和评价函数的升级即通过策略神经网络和评价神经网络来运算。这样阿尔法狗才得以成为围棋中的“神算子”。这些复杂模型就是机器学习领域的新宠,叫“深度神经网络”。以后我们专门给大家讲解。

这些神算子要求的计算量也是特别巨大的, 所以阿尔法狗的背后是庞大的计算系统。它用了1202个CPU, 176个GPU, 一场比赛下来的耗能是人类的300多倍。

而对于网上众多网友担心的人工智能统治地球则实在是是中美国科幻大片儿的毒太深。阿尔法狗确实强大到征服了以高智慧之称的围棋,但事实上无论围棋再怎么复杂,其运算原理依旧和简单的井字棋类似,是在有限的“解空间” 中进行比较和选择。而在现实中有很多问题却都是开放式的问题,拥有无限的可能,比如在艺术与文学等方面上人类的成就是很难被人工智能所超越的。所以让李世石输掉的不是人工智能,而是我们人类越来越高的智慧。作者:未来实验室转载请注明来自“科普中国”。
责任编辑:科普云
 科普中国APP
科普中国APP
 科普中国微信
科普中国微信
 科普中国微博
科普中国微博






最新文章
-
为何太阳系所有行星都在同一平面上旋转?
新浪科技 2021-09-29
-
我国学者揭示早期宇宙星际间重元素起源之谜
中国科学报 2021-09-29
-
比“胖五”更能扛!我国新一代载人运载火箭要来了
科技日报 2021-09-29
-
5G演进已开始,6G研究正进行
光明日报 2021-09-28
-
“早期暗能量”或让宇宙年轻10亿岁
科技日报 2021-09-28
-
5G、大数据、人工智能,看看现代交通的创新元素
新华网 2021-09-28




