超算神威太湖之光仅仅跑分强劲?科普中国-科普融合创作与传播 2017-12-18 |
11月14日,新一期全球超级计算机500强(TOP500)榜单在美国盐湖城公布,中国神威太湖之光蝉联冠军,中国天河二号屈居次席。除神威太湖之光和天河二号外,中国也在TOP500上榜总数上与美国持平。
正如天河2号获得6连冠后却因为使用了Intel公司的至强Phi计算卡而被一些别有用心之徒百般诋毁,在神威太湖之光实现了包括处理器在内的所有核心部件全部国产化后,网络上又传来了不和谐的音符——有媒体认为,神威太湖之光的“可用性能与理论性能相去甚远”,并以“HPL效率是74.16%”,“HPCG测试只有0.371PFLOPS,效率则只有0.3%,这比天河2号的1.1%还要低”来质疑神威太湖之光。
言下之意,就是神威太湖之光的可用性能与理论性能相去甚远,只能用来跑分,根本就用不来。那么什么是Linpack和HPCG,神威太湖之光真的只能用来跑分么?
什么是Linpack?
上面媒体的一段话引用了几个测试的结果,并以74.16%、0.3%、1.1%等实际数据来说明中国超算可用性能与理论性能相去甚远,非常具有迷惑性。笔者简单的就Linpack测试和HPCG测试做个简要说明。
Linpack指的是矩阵求解,在科学计算中把实际问题抽象成方程组,然后离散成矩阵计算矩阵倍,代表的是传统的以矩阵为基础的数值计算方法,常用于理科和工科的数值求解和数值模拟。那么为何超算大多以Linpack测试成绩论高低呢?原因就在于很多科学计算模型都包含了矩阵求解,比如解微分方程,因此在超算任务中具有不可取代性——像辐射流体力学就是求解微分方程;而核爆炸模拟其实就是辐射流体力学+蒙特卡洛预测;雷达截面的矩量法计算也有赖于解微分方程;业内专家还告诉笔者“现在的深度学习算法的核心算法与Linpack的是一个”.......因此,linpack测试并非是一些跑分软件那样:不服跑个分,而是真正具有实战价值的测试。
Linpack效率指的是实际计算时的次数除以理论计算,举例来说:
神威太湖之光的理论性能为125.4 PFlops,Linpack浮点性能93PFlops,Linpack效率为74.16%。
天河2号的理论性能54.9Pflops,Linpack双精浮点性能33.8PFlops, Linpack效率61.5%
泰坦的理论性能27 Pflops,Linpack双精浮点性能17.6 PFlops,Linpack效率为65.19%。
红杉的理论性能为20.1Pflops,Linpack测试双精浮点性能为16.3P,Linpack效率高达81%。
这里要说明一点,就是超算的规模越大,Linpack测试效率的提高就越难——规模大到如一定程度,维持一段时间的稳定运行是非常难的,何况是太湖神威之光93PFlops的高性能。而神威太湖之光在Linpack测试性能是美国超算泰坦5倍以上的情况下,Linpack测试效率大幅领先于泰坦,这就非常可贵了!至于红杉的Linpack测试效率为何会高达81%,笔者会在下文做讲解。
另外还要说明的的一点,天河2号Linpack效率低于美国泰坦的原因——一方面是因为天河2号的规模更大,影响了效率;另一方面是因为天河2号采用的是Intel的至强PHI计算卡,而该计算卡就以理论性能强大,但稳定性能相对偏低著称——同样使用E5和至强PHI计算卡的美国超算Stampede,不仅运算能力仅为天河2号的五分之一左右(未升级前,升级后为三分之一),整机效率比天河2号更低,只有60.7%。
总而言之,以神威太湖之光的规模,取得Linpack效率达到74.16%已经非常厉害了,在采用异构计算的超算中属于顶尖水平,大家千万不要被一些无良媒体误导了。
异构超算在Linpack效率上天然低于同构超算
对于笔者认为的神威太湖之光Linpack效率达到74.16%属于顶尖水平的结论,也许某些人会提出异议,比如会列举出TOP500排名第四的美国超算红杉,红杉的理论性能为20.1Pflops,Linpack测试双精浮点性能为16.3P,Linpack效率高达81%。
那么为何红杉的Linpack效率如此之高呢?原因就在于和神威太湖之光、天河2号、泰坦等采用异构计算的超算不同,红杉采用的依旧是传统的同构计算技术。
超算可以分为两种架构。采用同构计算架构的超算只需要单纯使用一种处理器,在同一类型的处理器上执行计算任务。举例来说,中国超算神威蓝光采用了申威1600,美国的米拉和红杉采用了PowerPC-A2处理器,这些超算都没有采用GPU或其它类型的众核芯片等加速器。因此,红杉、米拉、神威蓝光都是采用同构计算架构超算的代表。
异构计算使用CPU、GPGPU、GPDSP、ASIC、FPGA和其它类型的众核处理器来处理不同类型的计算任务。采用异构计算架构的超算会使用至少2种类型的处理器,其中异构计算架构中通用CPU负责逻辑复杂的调度和串行任务,加速器负责并行度高的任务,实现计算加速。具体来说,采用异构计算架构的超算在运算中既使用处理器,又使用GPU或众核芯片等加速器。以中国天河2号和神威太湖之光为例,天河2号有16000个计算节点,每个节点由2片Intel-E5-2692和3片Xeon-Phi组成,共使用了32000片Intel-E5-2692和48000片Xeon-Phi。神威太湖之光虽然只采用了申威26010众核处理器,看起来像同构超算,但由于申威26010集成了4个管理核心和256个运算核心,一片申威26010就是一个计算节点,管理核心执行类似于天河计算节点中E5的功能,而256个运算核心则发挥了类似于Xeon-Phi的加速作用,因此也属于异构超算。
由于异构编程需要提前预知模型并做特殊优化,而且很多应用未必适合异构模型,使得采用异构计算的超算对于编程和优化的要求更高——一位业内人士就评价,“异构编程太劳心劳力了,高端人才的精力应该用在关注自己的专业上来,而不是当代码狗......年纪大一点的科研人员就不愿自己编代码了,一些年青但不愿劳思费神的科研人员也不愿意编写异构代码......”。因此,采用异构计算的超算在Linpack效率上天然低于采用同构计算的超算。
那么既然同构超算在编程方便和效率上具有优势,为何全球超算都转向异构计算呢?原因就在于,这样超算可以获得更高的性能,之前抱怨异构编程太劳心劳力的业内朋友就表示,“超算方面众核是近些年的趋势,虽然编程劳心费力,但是在性能面前我们还是得忍,相同成本谁不想性能更好,科研对性能的需求可以用饥渴来形容”。
唠唠叨叨说这么多,主要是为了打一个补丁,防止别有用心之徒用美国同构超算和中国异构超算比Linpack效率,进而抹黑中国超算Linpack效率低下,何况前者的规模远远小于后者。
什么是HPCG
目前,评价超算的指标有不少,除了测试Linpack的TOP500,还有强调的是内存带宽和延迟的Graph500,Graph500对全系统的内存带宽和内存延迟有很高的要求,而计算能力本身已经不影响测试结果了,这种测试偏向于访存密集型运算,在大数据分析等场景下比较有意义。
除Graph500之外,还有强调节能环保的Green500。那么,在Graph500和Green500排行榜上,神威太湖之光的表现如何呢?Graph500名列第二,Green500名列第三。
不过,也有工程师认为无论是TOP500,还是Graph500都过于极端——TOP500过于强调计算性能,Graph500过于强调带宽和延迟等因素,因此采用了新的标准HPCG。
HPCG是美国正在推的一个新测试标准,目前还没有被业界广泛接受,HPCG代表了共轭梯度迭代法的一类应用的计算和通信特征,仅仅代表了某一个方面的特征,并不能涵盖超算的所以特征。HPCG比较重视计算性能和通信的平衡,如果计算性能和通信不是一个量级的,即便两项指标分开看都很强,但也会导致HPCG偏低的结果。
另外,HPCG也存在一些缺陷,据业内人士介绍,“由于针对具体硬件结构修改共轭梯度算法很容易得到高得多的成绩,为了避免这一点,HPCG代码目前还在锁定状态,不准修改算法本身。但在使用中,用户是会修改算法的,这使得这一测试会脱离实际”。
在某媒体的报道中,“但在更具实战意义的HPCG性能(高性能共轭梯度基准测试)中,太湖之光只有0.371PFLOPS,效率则只有0.3%,这比天河2号的1.1%还要低”,0.3%和1.1%的数据和该媒体的这种表述很容易让人误认为,天河2号和神威太湖之光的HPCG测试结果非常差,但实际上,在HPCG测试排行榜中,天河2号位列第一,而神威太湖之光为列第三,这其实是很不错的成绩。而且一位业内人士猜测,“也许神威还没有好好进行优化”。
必须指出的是,神威太湖之光的HPCG低于天河2号,并非是因为计算性能或在通信上不如天河2号,恰恰相反,在计算性能上神威太湖之光大幅领先于天河2号,而在互联网络方面,神威太湖之光也不逊色于天河2号——虽然在带宽上有差距,但在实际应用中,带宽指标比较延迟等指标而言并不太重要(延时指的是1个CPU把自己的计算结果交给其他CPU,如及时送到,其他CPU就能继续计算,否则就要等待了,芯片、链路、协议等都会影响延时)。因此,神威太湖之光在HPCG上逊色于天河2号,原因就在于计算性能实在是过于强悍,以至于产生了计算和通信上的不平衡,并最终导致自HPCG上逊色于天河2号。
神威太湖之光能否用得起来?
对于神威太湖之光根本用不起来的说法,其实只要关注新闻,就能明白这是彻头彻尾的谎言。凭借“神威•太湖之光”强悍的计算性能,国内科研单位在天气气候、航空航天、海洋科学、新药创制、先进制造、新材料等重1要领域取得了一批应用成果——由中科院软件所、清华大学和北京师范大学申报的“全球大气非静力云分辨模拟”课题,由国家海洋局海洋一所和清华大学申报的“全球高分辨率海浪数值模式”课题,由中科院网络中心申报的“钛合金微结构演化相场模拟”课题分别入围了戈登贝尔奖,使中国在该领域实现零的突破。戈登贝尔奖是高性能计算应用领域的最高奖,神威太湖之光用事实说明,完全自主研发的超算不仅可以用起来,还能用的好。
另外,笔者介绍几个神威太湖之光的具体应用:
应用一:基于国产平台的国产地球系统模式。
公共地球系统模式是一个MPMD的大型并行系统,经历了30年的建立与发展,核心代码量超过150万行,是目前全球使用最广泛的地球模式,也是高性能计算的传统应用。CESM计算模式多样,各个部分并不相同,对计算机器以及并行算法都有不同要求,在移植、加速以及优化算法等方面都具有较高的挑战。清华大学地学中心、清华大学计算机系为了将代码量巨大的CAM模式扩展到神威系统的百万计算核上,对公共大气模式CAM的代码重构与性能优化设计了与神威系统计算、存储模型相匹配的计算代码,有效地提高了计算性能。与纯主核版本相比,同时使用主、从核的优化程序能取得22倍的性能提升。通过使用24,000个主核以及1,536,000个从核,全球范围25公里分辨率的模拟速度可以达到2.81模式年/天
应用二:航天飞行器统一算法数值模拟。
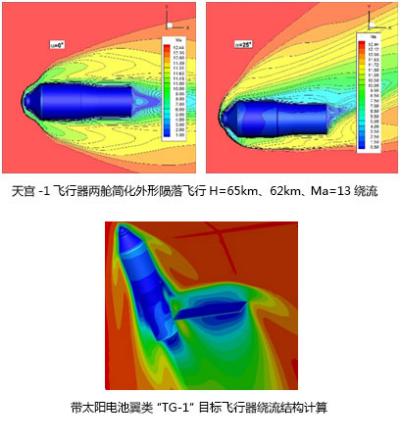
国家计算流体力学实验室基于”神威·太湖之光“超级计算机,对”天宫一号“飞行器两舱简化外形(长度10余米、横截面直径近3.5米)陨落飞行(H=65km、62km、Ma=13)绕流状态大规模并行模拟,使用16,384个处理器在20天内便完成常规需要12个月的计算任务,计算结果与风洞实验结果吻合较好,为”天宫一号“飞行试验提供重要数据支持。
应用三:纳米线热导率的大规模分子动力学模拟

低维纳米材料由于具有许多独特的光、热、电、磁等性质,已成为当前材料领域研究的重要方向。当前的实验测量技术在处理纳米尺度传热时遇到许多困难,实验测量结果会存在较大的偏差。分子动力学(NAMD)模拟方法能够细致刻画院子振动周期内的微观过程,已经成为研究低维纳米结构导热性质的主要手段。非平衡分子动力学模拟(NEMD)由于类似于直接的实验测量,并且模拟收敛快,计算效率高,能够处理像纳米线、多晶这样的不均匀结构,因此得到广泛应用。
中科院过程所利用“神威·太湖之光”计算机系统的大规模并行计算能力,模拟体系原子数目达到了了20亿量级,单一方向空间特征尺度达到500微米以上,从而可以考察低维纳米材料力学和热学性质的一些临界尺寸效应。计算取得了良好的性能,有效扩展到122,880个主核,共计798万个计算核心,并达到了70%的并行效率。
除上述介绍的应用之外,还有基于受体库的药物结合能力研究与生物大分子的分子动力学模拟、岛礁建设浮式平台的移植与优化、真实感动漫渲染系统研究与应用等具体应用。在最近曝光率非常高的深度学习方面,无锡超算中心和北邮合作,实现在SW26010芯片上,对占卷积神经网络90%计算时间的卷积层操作进行深度优化,相比今年八月份的工作有26%的性能提高,在SW26010单核组上还实现了智能围棋神经网络的正向传播过程......从上述例子可以看出,神威太湖之光不仅拥有可以用来争夺戈登贝尔奖的应用,还有科学研究和商业用途的超算渲染方面发挥着巨大作用。
结语
虽然有观点认为不能过度看中Linpack成绩,但考虑到Linpack在科学计算中的实际价值,以及至今没有可以替代Linpack的权威测试,超算的Linpack成绩依然非常具有借鉴意义,从这个角度上讲,将神威太湖之光全球最强超算的冠冕当之无愧。虽然神威太湖之光并没有在所有的测试中获得第一,但这并非是可以诋毁神威太湖之光的理由——以神威太湖之光在一些测试中仅夺得第二名、第三名就否定这台100P超算,这种否定方式绝不是科学的态度。
关于神威太湖之光超算到底是只能跑分还是真正的科研利器,戈登贝尔奖和文章里介绍的具体应用已经对各种质疑做出了有力的回击。
责任编辑:科普云
 科普中国APP
科普中国APP
 科普中国微信
科普中国微信
 科普中国微博
科普中国微博






最新文章
-
为何太阳系所有行星都在同一平面上旋转?
新浪科技 2021-09-29
-
我国学者揭示早期宇宙星际间重元素起源之谜
中国科学报 2021-09-29
-
比“胖五”更能扛!我国新一代载人运载火箭要来了
科技日报 2021-09-29
-
5G演进已开始,6G研究正进行
光明日报 2021-09-28
-
“早期暗能量”或让宇宙年轻10亿岁
科技日报 2021-09-28
-
5G、大数据、人工智能,看看现代交通的创新元素
新华网 2021-09-28




