

图形数据库是NoSQL数据库的一种类型,它应用图形理论存储实体之间的关系信息。图形数据库是一种非关系型数据库,它应用图形理论存储实体之间的关系信息。最常见例子就是社会网络中人与人之间的关系。关系型数据库用于存储“关系型”数据的效果并不好,其查询复杂、缓慢、超出预期,而图形数据库的独特设计恰恰弥补了这个缺陷。1
组成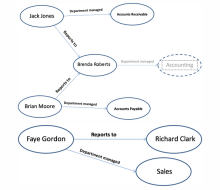
优势在需要表示多对多关系时,常常需要创建一个关联表来记录不同实体的多对多关系,而且这些关联表常常不用来记录信息。如果两个实体之间拥有多种关系,那么就需要在它们之间创建多个关联表。而在一个图形数据库中,我们只需要标明两者之间存在着不同的关系。如果希望在两个结点集间建立双向关系,就需要为每个方向定义一个关系。4
也就是说,相对于关系数据库中的各种关联表,图形数据库中的关系可以通过关系能够包含属性这一功能来提供更为丰富的关系展现方式。因此相较于关系型数据库,图形数据库的用户在对事物进行抽象时将拥有一个额外的武器,那就是丰富的关系。4
应用在许多情报和执法程序中,重要的是要寻找一个模式的事件。这些事件中的任何一个都可能看起来是无害的,但他们观点以及他们是怎样直接或间接相关的,概念是不一样的。再例如社会网络分析(SNA)对许多供应商的消费品非常感兴趣,他是构建人与人之间的关系图。Facebook是一个社交网络,它可以与家人和朋友之间保持联系。图形数据库能很好地显示出这个人在他/她的朋友圈中是否有影响力,这群朋友是否有着共同的兴趣爱好。3
截至2013年6月底,我国网民规模达5.91亿人,随着越来越多用户的加入,数据量呈指数增长,对社交网络的分析将面临很大的困难。Aggarwal等在文献中介绍了一些社交网络分析应用场景,以及在中心地位分析、角色分析、网络建模等方面研究中存在的问题。针对在社交网络分析面临数据增量较大和图形数据库更适于存储和处理社交网络关系的特点,R.Soussi等提出了一种从关系数据库数据转换成图形数据库数据的机制,并从图形数据库中抽取社交网络关系的方法。S.Kadge等提出了基于图预测社交网站,预测是基于有向加权的社交图,方法是构建用户行为的社交网络图,用图挖掘技术预测未来的社交行为,并与Apriori和F-Tree两种算法的预测效率进行了对比。J.Cao等分析和模拟企业社交网络中的用户交互行为,形成企业用户的组织图和社交图,用两类图构建用户交互模型,用于预测企业用户之间的交互行为。李孝伟等提出了一种融合节点与链接属性的社交网络社区划分算法,该算法融合节点属性的相似度、节点间链接权值等链接属性信息,结合聚类算法实现了对社交网络的社区划分。5
常见图形数据库Neo4jNeo4j是一个流行的图形数据库,它是开源的。最近,Neo4j的社区版已经由遵循AGPL许可协议转向了遵循GPL许可协议。尽管如此,Neo4j的企业版依然使用AGPL许可。Neo4j基于Java实现,兼容ACID特性,也支持其他编程语言,如Ruby和Python。1
FlockDBFlockDB是Twitter为进行关系数据分析而构建的。FlockDB迄今为止还没有稳定的版本,对于它是否是一个真正的图形数据库,尚有争议。FlockDB和其它图形数据库(如Neo4j、OrientDB)的区别在于图的遍历,Twitter的数据模型不需要遍历社交图谱。尽管如此,由于FlockDB应用于Twitter这样的大型站点,以及它相比其它图形数据库的简洁性,仍然值得我们值得关注。1
AllegroGrapAllegroGrap是一个基于W3c标准的为资源描述框架构建的图形数据库。它为处理链接数据和Web语义而设计,支持SPARQL、RDFS++和Prolog。1
GraphDBGraphDB是德国sones公司在.NET基础上构建的。Sones公司于2007年成立,近年来陆续进行了几轮融资。GraphDB社区版遵循AGPL v3许可协议,企业版是商业化的。GraphDB托管在Windows Azure平台上。3
InfiniteGraphInfiniteGraph基于Java实现,它的目标是构建“分布式的图形数据库”,已被美国国防部和美国中央情报局所采用。除此之外,还有其他一些图形数据库,如OrientDB、InfoGrid和HypergraphDB。Ravel构建在开源的Pregel实现之上,微软研究院的Trinity项目也是一个图形数据库项目。3
HugeGraph百度开源的分布式图数据库。6支持标准的Apache Tinkerpop Gremlin图查询语言,支持属性图,可支持千亿级规模关系数据;支持多种后端存储(Cassandra,HBase,RocksDB,MySQL,PostgreSQL,ScyllaDB);支持各类索引(二级索引、范围索引、全文索引、联合索引,均无需依赖第三方索引库);7提供可视化的Web界面,可用于图建模、数据导入、图分析;提供导入工具支持从多种数据源中导入数据到图中,支持的数据源包括:CSV、HDFS、关系型数据库(MySQL、Oracle、SQL Server、PostgreSQL);支持REST接口,并提供10+种通用的图算法;支持与Hadoop、Spark GraphX等大数据系统集成。8
研究现状图形数据库是非关系型数据库NoSQL按照数据模型分类中的一个分支体系,通过应用图形存储实体W及实体间的关系信息,为某一图模型问题提供了良好的数据库存储与数据处理解决方案。W最常见的社交网络中人与人的关系信息为例,使用传统关系型数据库RDBMS存储社交网络数据的效果并不理想,难以查巧及深度遍历大量复杂且互连接的数据,响应时间缓慢超出预期,而图形数据库的恃点恰到好处的填补了这一短板。作为NoSQL的一种,图形数据库很长一段时间都局限于学术与实验室,它利用圈的顶点和边来表示要素和要素之间的关系。随着社交网络Facebook、电子商务以及资源检索等领域的发展,急需一种可以处理复杂关联的存储技术,而采用图形数据库组织存储、计算分析挖掘低结构化且互连接的数据则更为有效,因此图形数据库得W逐渐从实验室走出,同时反过来也极大地推动了图形数据库的飞速发展。图数据库依托图论为理论基础,描述并存储了图中节点与其之间的关系。国内外基于图论数据挖掘展开的工作分为图的匹配、关键字查询、图的分类、图的聚类和频繁子图挖掘问题等五个方面。2
图的匹配即通过研究图与图之间的拓扑结构,从而分析图之间的相似度大小,Conte等在图匹配方面有着突出的贡献;在团形数据库关键字检索方面,一方面是通过研巧网络关系图的巧化关系从而分析检索子图,包括双向查询算法算法,另一方面则基于索引指导图挖掘,著名的有BLINKS算法;图分类包括有监督分类和无监督分类两种,Boser等基于core进行分类,Horvath等提出一种基于支持向量机分类的方法;图的聚类算法包括节点和对象两种不同的范围,Aggarwal等则使用文挡结构进行聚类;频繁子图挖掘是指在图集合中挖掘公共子结构,常见的频繁子图挖掘算法包括FSG(Frequent Subgraph Discovery)、FFSM(Fast Frequent Subgraph Minning)和Splat等。同时,为改善围形数据库的性能,相关学者进行了广泛的研究,巧得了一些研究成果:N.Mar提出了一种性能化良的存储结构DEX,其利用位图的设计思想,对检索进行优化处理后,能够准确岛效的检索高达10亿级别的数据;Prima针对图数据库访问节点延迟较大这一问题,设计了一类线上数据隔离模型;Ylping等则基于皮尔森相关系数(Pearson correlation coefficient)方法设计了CGS(Correelated Graph Search)算法,其优点是提高了图的遍历速度及稳定性,同时大大减少了检索过程中的服务器压力,减少系统开销。2
本词条内容贡献者为:
尚轶伦 - 副教授 - 同济大学数学科学学院

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国