

近年来,深度学习在很多领域的都取得了突破性进展,但大家似乎发现了这样的一个现实,即深度学习取得突破性进展的工作基本都是判别模型相关的。2014 年 Goodfellow 等人启发自博弈论中的二人零和博 弈 ,开创性地提出了生成对抗网络1(GAN)。生成对抗网络包含一个生成模型和一个判别模型。其中,生成模型负责捕捉样本数据的分布,而判别模型一般情况下是一个二分类器,判别输入是真实数据还是生成的样本。这个模型的优化过程是一个“二元极小极大博弈”问题2,训练时固定其中一方(判别网络或生成网络),更新另一个模型的参数,交替迭代,最终,生成模型能够估测出样本数据的分布。生成对抗网络的出现对无监督学习,图片生成的研究起到极大的促进作用。生成对抗网络已经从最初的图片生成,被拓展到计算机视觉的各个领域,如图像分割、视频预测、风格迁移等。
定义生成对抗网络(GAN)包含一个生成模型G 和一个判别模型D ,其结构如图1所示。 生成对抗网络的目的是学习到训练数据的分布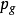 ,为了学习该分布,首先定义一个输入噪声变量
,为了学习该分布,首先定义一个输入噪声变量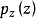 ,接下来将其映射到数据空间
,接下来将其映射到数据空间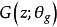 ,这里的 G 就是一个以
,这里的 G 就是一个以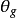 作为参数的多层感知网络构成的生成模型。此外,定义一个判别模型
作为参数的多层感知网络构成的生成模型。此外,定义一个判别模型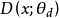 用来判断输入的数据是来自生成模型还是训练数据,D 的输出为 x 是训练数据的概率。最后训练 D 使其尽可能准确地判断数据来源,训练 G 使其生成的数据尽可能符合训练数据的分布3。
用来判断输入的数据是来自生成模型还是训练数据,D 的输出为 x 是训练数据的概率。最后训练 D 使其尽可能准确地判断数据来源,训练 G 使其生成的数据尽可能符合训练数据的分布3。
值得说明的是,D 和 G 的优化必须交替进行,因为在有限的训练数据情况下,如果先将 D 优化完成会导致过度拟合,从而模型不能收敛。

生成对抗网络的各种变体条件生成对抗网络条件生成对抗网络(CGAN)是生成对抗网络的一个扩展,其结构图如图2所示,它的生成模型和判别模型都基于一定的条件信息 y 。这里的 y 可以是任何的额外信息,例如,类别标签或者数据属性等。这样生成模型 G 就有两个输入: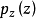 和 y 。一般情况下, 和 y 以隐藏节点连接的方式结合在一起。因此,该二元极小极大问题的目标函数就变为:
和 y 。一般情况下, 和 y 以隐藏节点连接的方式结合在一起。因此,该二元极小极大问题的目标函数就变为:
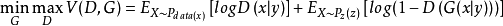
条件生成对抗网络可以根据输入条件不同生成相应类型的图片。
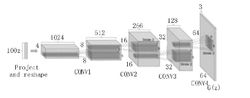
深度卷积生成对抗网络深度卷积生成网络(DCGAN)将卷积神经网络(CNN)4引入到了生成模型和判别模型当中,使得生成性能有了质的提升,以至于后来很多工作都在该网络的基础上进行改进。该网络结构的几个设计要点为:1)将卷积网络中的池化层用相应步长的卷积层代替;2)在生成模型和判别模型中都使用了批归一化层;3)去掉了网络中的全连接层;4)在生成模型中采用Re LU激活函数;5)在判别模型中采用Leaky Re LU激活函数。其生成模型结构图如图3所示。深度卷积生成网络相对于一般的生成对抗网络而言具有更强大的生成能力,同时训练起来更加稳定、容易,生成样本更加多样化等优点。深度卷积生成网络生成的图片足以以假乱真,但缺点是生成图像分辨率比较低(64 * 64),这也是现阶段各种生成对抗网络及其变体所具有的共同问题,因此,如何生成高质量、高分辨率图像将会是一个热门研究方向。
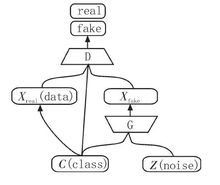
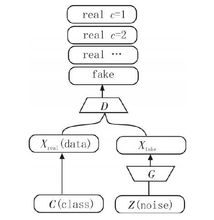
半监督生成对抗网络半监督生成对抗网络(SGAN)的判别模型不仅仅判断图像的来源(由 G 生成或者来自训练数据)同时判断图像的类别,这样使得判别模型具有更强的判别能力,其网络结构图如图4所示。另一方面,输入网络的类别信息也在一定程度上提高了生成模型生成图片的质量,因此半监督生成抗网络的性能要比普通的生成对抗网络的性能略好一些。
信息生成对抗网络信息生成对抗网络5(Info GAN),其结构图如图5所示,它在一般的生成对抗网络的基础上增加了一个潜在编码 c ,其中 c 可以包含多种变量,比如在MNIST中,c 可以一个值来表示类别,一个高斯分布的值来表示手写体的粗细。网络中生成模型的输入 和 y ,输出为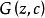 。为了避免网络没有监督使用 c ,信息生成对抗网络在优化的目标函数中增加了一项:
。为了避免网络没有监督使用 c ,信息生成对抗网络在优化的目标函数中增加了一项: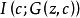 用来表示共同信息的程度。因此该网络的目标函数为:
用来表示共同信息的程度。因此该网络的目标函数为:
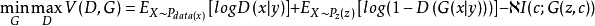
信息生成对抗网络可以通过改变潜在编码 c 的值来控制生成图片的属性,例如生成不同倾斜度或者粗细的数字。
生成对抗网络的应用图像分割图像分割是指将图像的中的内容根据不同的语义分割开来。绝大多数分割的方法是将图像的每个像素进行分类,这样就忽略了空间一致性这个重要信息。生成对抗网络做图像分割时,生成模型被图像像素分类的网络替换,判别模型用于判断是网络的分类产生的分割图(Class predictions)还是标准的分分割图(Ground truth)。
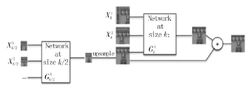
视频预测视频预测是根据当前的几帧视频预测接下来的一帧或者多帧视频。一般常用的做法是用最小二乘回归视频帧的逐个像素值,这样做的一个问题就是生成视频帧存在动作模糊(Motion blur)。一种采用生成对抗网络的做法是,将现有视频帧改变不同尺寸 输入生成模型 G ,让 其 输 出 接 下 来 的 真 值 帧(Ground truth frame)。图6给出了生成对抗网络应用于视频预测时生成网络部分示意图。判别模型和一般生成对抗网络相同,即判断视频帧是生成的还是训练数据原有的
风格迁移风格迁移是指将目标图像的风格迁移到源图像当中,使得源图像保留内容的同时具有目标图像的风格,比如将卡通人物的风格迁移到真实人脸图像使其成为卡通头像。生成对抗网络用于图像风格迁移时其特点有3个:1)将源图像输入生成网络后,生成网络输出目标图像风格的图片;2)生成图像和源图像特征相同(或者说保持内容);3)当把目标图像输入生成网络后,生成网络仍然输出目标图像(相当于单位映射)。
本词条内容贡献者为:
王沛 - 副教授、副研究员 - 中国科学院工程热物理研究所

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国