

尼德曼-翁施算法(Needleman-Wunsch Algorithm)是基于生物信息学的知识来匹配蛋白序列或者DNA序列的算法。这是将动态算法应用于生物序列的比较的最早期的几个实例之一。该算法是由 Saul B. Needlman和 Christian D. Wunsch 两位科学家于1970年发明的。本算法高效地解决了如何将一个庞大的数学问题分解为一系列小问题,并且从一系列小问题的解决方法重建大问题的解决方法的过程。该算法也被称为优化匹配算法和整体序列比较法。时至今日,Needleman-Wunsch 算法仍然被广泛应用于优化整体序列比较中。
历史与算法发展通过Needleman和Wunsch的描述的算法的最初目的是找到在两种蛋白质的氨基酸序列的相似性。Needleman和Wunsch的描述他们的算法为明确的情况下,当对准被匹配和不匹配仅仅惩罚,并差距没有惩罚(D =0)。从1970年最初发布提示递归。
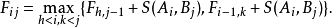 对应的动态规划算法需要立方时间。同时,递归可容纳任意差距处罚公式: 惩罚因子,减去对于由每个间隙,可被评估为阻挡在允许的间隙。惩罚因子可以是间隙的大小和/或方向的函数。
对应的动态规划算法需要立方时间。同时,递归可容纳任意差距处罚公式: 惩罚因子,减去对于由每个间隙,可被评估为阻挡在允许的间隙。惩罚因子可以是间隙的大小和/或方向的函数。
一个更好的动态规划算法二次运行时间为同样的问题(无间隙罚款)最早是由大卫Sankoff1972年类似的二次时间算法推出了由TK Vintsyuk于1968年独立发现了一种语音处理(“时间扭曲”),由罗伯特·瓦格纳和迈克尔·J·菲舍尔在1974年的字符串匹配。Needleman和Wunsch的配制最大化相似性的问题。另一种可能性是最小化序列之间的编辑距离,弗拉基米尔的Levenshtein引入。彼得·塞勒斯在1974年发现的两个问题是等价的。Needleman-Wunsch算法仍是广泛使用的最佳全局比对,特别是当全局比对的质量即结果是最重要的。然而,该算法是相对于时间和空间的昂贵,正比于两个序列,因而不适合长度特别长的序列比对。
最近的发展一直专注于提高算法的时间和空间成本,同时保持质量。例如,在2013年,快速优化整体序列比对算法(FOGSAA)1,建议比其他最佳全局比对的方法,其中包括中的Needleman-Wunsch算法更快核苷酸/蛋白质序列的比对。纸张声称相比中的Needleman-Wunsch算法时,FOGSAA达到70-90%为高度相似核苷酸序列的时间增益(具有>80%的相似性),并且对于具有30-80%的相似性的序列54-70%。
全局性配对和局部性配对的比较全局性配对和局部性配对的基本区别是在局部性配对中,你将尝试用你诉求的序列的片段或局部来进行配对。而在全局性配对中,你将尝试使用整个序列(从起始端到结束端)来进行配对,也即是说,在全局性配对中,当你的比对序列长度不一致时,在配对过程中可能会产生间隔或者不匹配的情况。注意,在局部性配对中也有可能产生间隔。2
局部性配对:

全局性配对:

在Needleman-Wunsch(全局性)算法中,分数跟踪系统是基于得分矩阵的右下角开始的。然而在Smith-Waterman(局部性)算法中,得分矩阵的起始点是基于分数最高的坐标位置。 全局性配对主要应用于比较同源性的基因的相似性而局部性配对主要应用于在非同源性的基因序列中寻找具有相似性的同源的基因域。
尼德曼-翁施算法简介本算法可以用于比较任意两个序列。下面将会使用两个短小的DNA序列作为例子来演示该算法。
有序列: GCATGCU
GATTACA
初始化得分矩阵首先建立如图一的得分矩阵。从第一列第一行的位置起始。计算过程从d 0 , 0开始,可以是按行计算,每行从左到右,也可以是按列计算,每列从上到下。当然,任何计算过程,只要满足在计算d i , j时d i-1 , j、d i-1 , j-1和d i, j-1都已经被计算这个条件即可。在计算d i , j后,需要保存d i , j是从d i-1 , j、d i-1 , j-1或di, j-1中的哪一个推进的,或保存计算的路径,以便于后续处理。上述计算过程到d m , n结束。
选择得分体系接下来我们需要决定如何给每个独立配对打分。从我们的序列中,你可能就能发现最好的序列配对之一:
GCATG-CU
G-ATTACA
我们可以看出每个位置配对都有三种可能情况:匹配, 不匹配与错位(或插入):
匹配: 两个字母相同
不匹配:两个字母不相同
错位:一个字母与另一个序列中的间隔(空白)相匹配
这三种得分情况有很多打分标准,这些情况都总结在得分体系的部分。从现在开始,我们将使用Needleman 和Wunsch创造的简单体系来进行打分,即匹配得一分,不匹配得-1分,错位得-1分.
填充得分矩阵开始于第二行中的第二列,初始值为0。通过矩阵一行一行移动,计算每个位置的分数。得分被计算为从现有的分数可能的最佳得分(即最高)的左侧,顶部或左上方(对角线)。当一个得分从顶部计算,或从左边这代表在我们的对准的插入缺失。当我们从对角线计算分数这表示两个字母所得位置匹配的对准。定不存在“向上”或“左上”的位置对第二行,我们只能从现有单元向左添加。因此,我们添加-1的权利,因为这代表了从以前的比分插入缺失。这导致在第一行是0,-1,-2,-3,-4,-5,-6,-7。这同样适用于第二列,因为我们只具有以上现有分数。因此,我们有:

所以根据该矩阵就可以方便的求出匹配路径:
|| ||
得分体系基础得分标准最简单的打分体系只考虑匹配,不匹配与间隔三种情况。在新手指南中使用的打分体系是匹配=1,不匹配=-1,间隔=-1。在这种情况下序列越长,得分越低,在本体系中我们期望好的匹配取得高分。另一种打分体系如下:
匹配=0
间隔=1
不匹配=1
在本体系中得分将会代表两序列中匹配的距离。不同的得分体系适用于不同的情况。例如,如果在你的匹配中间隔被认为有很大的负面影响,你可以使用间隔扣分很多的打分体系:
匹配=0
间隔=10
不匹配=1
相似度矩阵更复杂的打分体系不仅仅考虑选择的不同类型,也考虑每个不同的字母的影响。例如,字母A与A匹配将得到4分。为了表示所有字母匹配得分的情况,我们将会使用相似度矩阵来帮助计算。
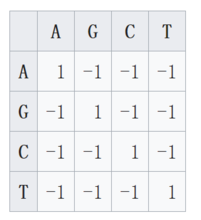
每个分数代表从一个字母转换到下一个位置的所有可能的情况的得分。

不同的得分矩阵适用于不同的情况。该得分体系对于蛋白序列的匹配比对尤为重要。以下为两种广为引用的蛋白序列相似度矩阵
PAM
BLOSUM
间隔补偿当比对序列往往存在差距(即插入缺失),有时路数。生物学上,有很大的差距更容易,而不是多个单一缺失的发生为一体的大型删除。因此,我们应该进球两个小的插入缺失是有过之而无不及一个大的。简单和常见的方式做,这是通过一个大的差距,比分开始一个新的插入缺失和一个较小的间隙延伸得分为每个扩展了插入缺失信。例如,新插入缺失可能会花费-5和扩展,插入缺失可能会花费-1。
进阶矩阵例如,如果相似度矩阵如下图所示:
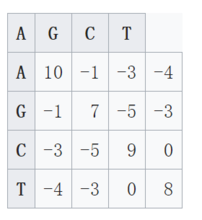
那么匹配结果如下:
AGACTAGTTAC
CGA----GACGT
如果间隔惩罚因子是-5,那么该匹配的得分为:
S(A,C) + S(G,G) + S(A,A) + (3 × d) + S(G,G) + S(T,A) + S(T,C) + S(A,G) + S(C,T)
= -3 + 7 + 10 - (3 × 5) + 7 + (-4) + 0 + (-1) + 0 = 1
计算序列相似程度时还应该考虑序列长度的影响。令S(s, t) 表示两条长度分别为m和n的序列的相似性得分,假设S(s, t) = 99,两条序列有99个字符一致。如果 m=n=100 ,则可以说这两条序列非常相似,几乎一样。但是,如果m=n=1000,则仅有10% 的字符相同。所以,在实际序列比较时,使用相对长度的得分就更有意义,定义: (4) 以sim(s,t)作为衡量序列相似性的指标。 从所使用的数据结构d i , j本身及其计算过程来看,序列两两比对基本算法的空间复杂度和时间复杂度都是O (mn)。如果两条序列的长度相近,空间和时间复杂度就为O (n2)。
程序代码本算法可以在多个平台上实现运算,常见的编程语言均有公开的代码可以参考使用。
OPTIONS: --file 同时读取比对的两序列文件 --files --stdin 读取标准文件头 --case_sensitive 使用大小写字母区分 --match [默认: 1] --mismatch [默认: -2] --gapopen [默认: -4] --gapextend [默认: -1] --scoring --substitution_matrix --substitution_pairs freestartgap 间隔不扣分 freeendgap 序列结束不扣分 printscores 打印优化后的比对分数 zam printmatrices 打印动态矩阵 printfasta 打印fasta格式的文件头 pretty 打印描述行 colour 打印颜色 可选优化项: nogapsin1 被比对序列不允许有间隔 nogapsin2 比对序列不允许有间隔 nogaps 所有序列均不允许有间隔 nomismatches 不允许有误差配对应用三维立体画三维立体画是利用人眼立体视觉现象制作的绘画作品。普通绘画和摄影作品,包括电脑制作的三维动画,只是运用了人眼对光影、明暗、虚实的感觉得到立体的感觉,而没有利用双眼的立体视觉,一只眼看和两只眼看都是一样的。充分利用双眼立体视觉的立体画,将使你看到一个精彩的世界。人有两只眼,两只眼有一定距离,这就造成物体的影象在两眼中有一些差异,见右图,由图可见,由于物体与眼的距离不同,两眼的视角会有所不同,由于视角的不同所看到是影象也会有一些差异,大脑会根据这种差异感觉到立体的景象。三维立体画就是利用这个原理,在水平方向生成一系列重复的图案,当这些图案在两只眼中重合时,就看到了立体的影象。参见下图,这是一幅不能再简单的立体画了。图中最上一行圆最远,最下一行圆最近,请注意:最上一行圆之间距离最大,最下一行圆之间距离最小。重复图案的距离决定了立体影象的远近,生成三维立体画的程序就是根据这个原理,依据三维影象的远近,生成不同距离的重复图案。 立体画有两种形式:第一种是由相同的图案在水平方向以不同间隔排列而成,看起来是远近不同的物体。 另一种立体画较复杂,在这种立体画上你不能直接看到物体的形象,画面上只有杂乱的图案,制作这样的立体画只有使用程序了。两种作品看法是一样的,原理都是使左眼看到左眼的影象,让右眼看到右眼的影象。
电脑立体视觉效果立体匹配是从一对立体图像的三维重建进程的一个重要步骤。当图像已被纠正,打个比方可以对准核苷酸/蛋白序列和匹配像素属于扫描线,因为这两个任务,着眼于人物的两个字符串之间建立最佳的对应关系绘制。实际上,一对立体声的“正确”的图像可以被看作是“左”图像的突变版本:噪声和单个摄像机的灵敏度改变的像素值(即字符取代);和不同的视角揭示以前闭塞的数据,并引入新的闭塞(即插入和字符删除)。作为结果,中的Needleman-Wunsch算法的小的修改,使其适合于立体匹配3。尽管该算法在准确性方面性能都不算是最先进的,该但算法的相对简单性允许其在嵌入式系统上执行,使其有广泛的应用。4
本词条内容贡献者为:
王沛 - 副教授、副研究员 - 中国科学院工程热物理研究所

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国