

概率潜在语义分析(PLSA)**,**也称为 概率潜在语义索引(PLSI),尤其是在信息检索领域)是一个一种用于分析双模式和共现数据的统计技术。 实际上,就像从PLSA进化而来的潜在语义分析一样,可以根据它们对某些隐藏变量的亲和性来导出观察变量的低维表示。
与源自线性代数的标准潜在语义分析和缩小发生表(通常通过奇异值分解)不同的是,概率潜在语义分析基于从潜在类模型导出的混合分解。
简介潜在语义分析是一种对双模型和同现数据进行分析的统计技术,它已经被应用于信患的检索与过滤、自然语言处理、机器学习和一些相关的领域。标准的潜在语义分析主要是基于线性代数并且对同现表格进行奇异值分解。而概率潜在语义分析则是基于从潜在的类模型中获取一个混合分解。这样就得到了一种更有原则性的,并且在统计方面有巩固基础的方法。
众所周知,潜在语义分析是专门讨论这些问题的一项技术。它的关键思想是映射高维计数向量,就像是把一个以文本文档的矩阵空间形式在一个称为潜在语义空间的地方变为一个更低维的形式。正如它的名字所提到的那样,LSA的目的就是找到数据映射,这种数据映射在词汇层次之外也能很好地提供信息,并且揭露相关实体间的联系。由于LSA的一般性,它被证明是非常有价值并且有着广泛应用的分析工具。然而,它的理论基础在很大程度上还不令人满意并且不完整。
模型以单词和文档的共现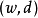 形式进行的观察,PLSA将每次共现的概率建模为条件独立的多项分布的混合:
形式进行的观察,PLSA将每次共现的概率建模为条件独立的多项分布的混合:
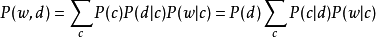
'c'是单词w的'主题'。请注意,主题数是一个超参数,必须事先选择,而不是从数据中估算。第一个公式是对称公式,其中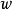 和
和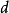 都是以类似方式从潜类
都是以类似方式从潜类 生成的(使用条件概率
生成的(使用条件概率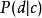 和
和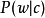 ,而第二个公式是不对称公式,其中,对于每个文件
,而第二个公式是不对称公式,其中,对于每个文件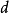 ,a根据
,a根据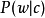 对文档有条件地选择潜在类,然后根据
对文档有条件地选择潜在类,然后根据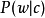 从该类生成一个单词。虽然我们在这个例子中使用了单词和文档,但是任何一些离散变量的共现可以以完全相同的方式建模。
从该类生成一个单词。虽然我们在这个例子中使用了单词和文档,但是任何一些离散变量的共现可以以完全相同的方式建模。
因此,参数的数量等于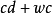 。参数数量随文档数量呈线性增长。此外,虽然PLSA是该集合中文档的生成模型,但估计它不是新文档的生成模型。
。参数数量随文档数量呈线性增长。此外,虽然PLSA是该集合中文档的生成模型,但估计它不是新文档的生成模型。
使用EM算法学习它们的参数。
应用PLSA可以通过Fisher内核用于判别设置。1
PLSA在信息检索和过滤,自然语言处理,文本机器学习以及相关领域都有应用。
据报道,概率潜在语义分析中使用的方面模型存在严重的过度拟合问题。
扩展分层扩展:
不对称:MASHA(“多项式非对称分层分析”)
对称:HPLSA(“分层概率潜在语义分析”)
生成模型:已经开发了以下模型来解决经常被批评的PLSA缺点,即它不是新文档的正确生成模型。
Latent Dirichlet分配 - 在每个文档主题分布上添加Dirichlet
高阶数据:尽管在科学文献中很少讨论这一点,但PLSA自然地延伸到更高阶数据(三种模式和更高阶),即它可以模拟三个或更多变量的共现。 在上面的对称公式中,这可以通过为这些附加变量添加条件概率分布来完成。 这是非负张量因子分解的概率类比。2
本词条内容贡献者为:
孔祥杰 - 副教授 - 大连理工大学软件学院

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国