

部分可观察马尔可夫决策过程(Partially Observable Markov Decision Process,缩写:POMDP),是一种通用化的马尔可夫决策过程。POMDP模拟代理人决策程序是假设系统动态由MDP决定,但是代理人无法直接观察目前的状态。相反的,它必须要根据模型的全域与部分区域观察结果来推断状态的分布。
因为POMDP架构的通用程度足以模拟不同的真实世界的连续过程,应用于机器人导航问题、机械维护和不定性规划。架构最早由研究机构所建立,随后人工智能与自动规划社群继续发展。
定义离散时间POMDP模拟代理与其环境之间的关系。 形式上,POMDP是7元组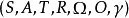 ,其中
,其中
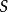 是一组状态,
是一组状态,
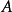 是一组动作,
是一组动作,
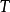 是状态之间的一组条件转移概率,
是状态之间的一组条件转移概率,
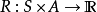 是奖励函数。
是奖励函数。
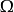 是一组观察,
是一组观察,
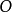 是一组条件观察概率,
是一组条件观察概率,
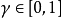 是折扣因子。
是折扣因子。
在每个时间段,环境处于某种状态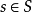 .The agent在A中采取动作
.The agent在A中采取动作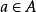 ,这会导致转换到状态
,这会导致转换到状态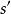 的环境概率为
的环境概率为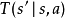 。同时,代理接收观察
。同时,代理接收观察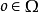 ,它取决于环境的新状态,概率为
,它取决于环境的新状态,概率为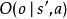 。最后,代理接收奖励
。最后,代理接收奖励 等于
等于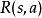 。然后重复该过程。目标是让代理人在每个时间步骤选择最大化其预期未来折扣奖励的行动:
。然后重复该过程。目标是让代理人在每个时间步骤选择最大化其预期未来折扣奖励的行动: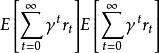 。折扣系数
。折扣系数 决定了对更远距离的奖励有多大的直接奖励。当
决定了对更远距离的奖励有多大的直接奖励。当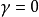 时,代理人只关心哪个动作会产生最大的预期即时奖励;当
时,代理人只关心哪个动作会产生最大的预期即时奖励;当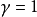 时,代理人关心最大化未来奖励的预期总和。
时,代理人关心最大化未来奖励的预期总和。
近似POMDP解决方案在实践中,POMDP通常在计算上难以解决,因此计算机科学家已经开发了近似POMDP解决方案的方法。基于网格的算法包括一种近似解决方案技术。 在该方法中,针对置信空间中的一组点计算值函数,并且使用内插来确定针对不在该组网格点中遇到的其他信念状态采取的最优动作。 最近的工作利用了采样技术,泛化技术和问题结构的利用,并将POMDP解决扩展到具有数百万个州的大型域。例如,基于点的方法对随机可达信念点进行抽样,以将规划约束到信念空间中的相关区域。还探索了使用PCA降低尺寸的方法1。
讨论由于代理不直接观察环境的状态,因此代理必须在真实环境状态的不确定性下做出决策。然而,通过与环境交互并接收观察,代理可以通过更新当前状态的概率分布来更新其对真实状态的信念。这种性质的结果是最佳行为通常可能包括信息收集行动,这些行动纯粹是因为它们改善了代理人对当前状态的估计,从而使其能够在未来做出更好的决策。
将上述定义与马尔可夫决策过程的定义进行比较是有益的。 MDP不包括观察集,因为代理总是确切地知道环境的当前状态。或者,通过将观察组设定为等于状态组并定义观察条件概率以确定性地选择对应于真实状态的观察,可以将MDP重新表述为POMDP。
本词条内容贡献者为:
孔祥杰 - 副教授 - 大连理工大学软件学院

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国