

统计学,数据挖掘和机器学习中的决策树训练,使用决策树作为预测模型来预测样本的类标。这种决策树也称作分类树或回归树。在这些树的结构里,叶子节点给出类标而内部节点代表某个属性。
在决策分析中,一棵决策树可以明确地表达决策的过程。在数据挖掘中,一棵决策树表达的是数据而不是决策。
推广在数据挖掘中决策树训练是一个常用的方法。目标是创建一个模型来预测样本的目标值。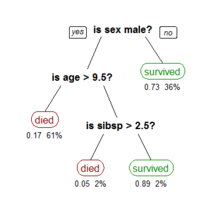 例如右图。每个内部节点 对应于一个输入属性,子节点代表父节点的属性的可能取值。每个叶子节点代表输入属性得到的可能输出值。
例如右图。每个内部节点 对应于一个输入属性,子节点代表父节点的属性的可能取值。每个叶子节点代表输入属性得到的可能输出值。
一棵树的训练过程为:根据一个指标,分裂训练集为几个子集。这个过程不断的在产生的子集里重复递归进行,即递归分割。当一个训练子集的类标都相同时 递归停止。这种决策树的自顶向下归纳 (TDITD) 1是贪心算法的一种, 也是当前为止最为常用的一种训练方法。
数据以如下方式表示:
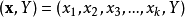 其中Y是目标值,向量x由这些属性构成, x1, x2, x3 等等,用来得到目标值。
其中Y是目标值,向量x由这些属性构成, x1, x2, x3 等等,用来得到目标值。
决策树的类型在数据挖掘中,决策树主要有两种类型:
分类树的输出是样本的类标。
回归树的输出是一个实数 (例如房子的价格,病人待在医院的时间等)。
术语分类和回归树 (CART) 包含了上述两种决策树, 最先由Breiman 等提出。分类树和回归树有些共同点和不同点—例如处理在何处分裂的问题。
有些集成的方法产生多棵树:
装袋算法(Bagging), 是一个早期的集成方法,用有放回抽样法来训练多棵决策树,最终结果用投票法产生。
随机森林(Random Forest) 使用多棵决策树来改进分类性能。
提升树(Boosting Tree) 可以用来做回归分析和分类决策。
旋转森林(Rotation forest) – 每棵树的训练首先使用主元分析法 (PCA)。
还有其他很多决策树算法,常见的有:
ID3算法
C4.5算法
CHi-squared Automatic Interaction Detector (CHAID), 在生成树的过程中用多层分裂2。
MARS可以更好的处理数值型数据。
模型表达式构建决策树时通常采用自上而下的方法,在每一步选择一个最好的属性来分裂。"最好" 的定义是使得子节点中的训练集尽量的纯。不同的算法使用不同的指标来定义"最好"。本部分介绍一些最常见的指标。
基尼不纯度指标在CART算法中, 基尼不纯度表示一个随机选中的样本在子集中被分错的可能性。基尼不纯度为这个样本被选中的概率乘以它被分错的概率。当一个节点中所有样本都是一个类时,基尼不纯度为零。
假设y的可能取值为{1, 2, ..., m},令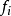 是样本被赋予i的概率,则基尼指数可以通过如下计算:
是样本被赋予i的概率,则基尼指数可以通过如下计算:
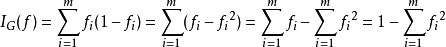
信息增益ID3,C4.5 和C5.0决策树的生成使用信息增益。信息增益 是基于信息论中信息熵的理论。
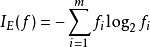
决策树的优点与其他的数据挖掘算法相比,决策树有许多优点:
易于理解和解释 人们很容易理解决策树的意义。
只需很少的数据准备 其他技术往往需要数据归一化。
即可以处理数值型数据也可以处理类别型 数据。其他技术往往只能处理一种数据类型。例如关联规则只能处理类别型的而神经网络只能处理数值型的数据。
使用白箱 模型. 输出结果容易通过模型的结构来解释。而神经网络是黑箱模型,很难解释输出的结果。
可以通过测试集来验证模型的性能 。可以考虑模型的稳定性。
强健控制. 对噪声处理有好的强健性。
可以很好的处理大规模数据 。
缺点训练一棵最优的决策树是一个完全NP问题。因此, 实际应用时决策树的训练采用启发式搜索算法例如 贪心算法 来达到局部最优。这样的算法没办法得到最优的决策树。
决策树创建的过度复杂会导致无法很好的预测训练集之外的数据。这称作过拟合。 剪枝机制可以避免这种问题。
有些问题决策树没办法很好的解决,例如 异或问题。解决这种问题的时候,决策树会变得过大。 要解决这种问题,只能改变问题的领域或者使用其他更为耗时的学习算法 (例如统计关系学习 或者 归纳逻辑编程).
对那些有类别型属性的数据, 信息增益 会有一定的偏置3。
延伸决策图在决策树中, 从根节点到叶节点的路径采用汇合或与。 而在决策图中, 可以采用 最小消息长度 (MML)来汇合两条或多条路径。
用演化算法来搜索演化算法可以用来避免局部最优的问题4。
本词条内容贡献者为:
何星 - 副教授 - 上海交通大学

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国