

领域自适应是与机器学习和转移学习相关的领域。 当我们的目标是从源数据分布中学习在不同(但相关)的目标数据分布上的良好性能模型时,就会出现这种情况。 例如,常见垃圾邮件过滤问题的任务之一在于使模型从一个用户(源分发)适应到接收显着不同的电子邮件(目标分发)的新模型。 注意,当有多个源分发可用时,该问题被称为多源域自适应。
形式化设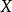 为输入空间(或描述空间),让
为输入空间(或描述空间),让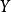 为输出空间(或标签空间)。机器学习算法的目的是学习数学模型(假设)
为输出空间(或标签空间)。机器学习算法的目的是学习数学模型(假设)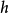 :→到的例子。从学习样本
:→到的例子。从学习样本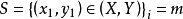 学习该模型。
学习该模型。
通常在监督学习中(没有域适应),我们假设示例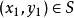 是
是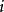 ,从支持×的分布
,从支持×的分布 (未知和固定)。然后,目标是学习
(未知和固定)。然后,目标是学习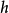 (来自
(来自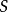 ,使得它尽可能地提交最小的错误来标记来自分布的新例子。
,使得它尽可能地提交最小的错误来标记来自分布的新例子。
监督学习和领域适应之间的主要区别在于,在后一种情况下,我们研究×上的两个不同(但相关)的分布和 。域适应任务则包括从源域到然后,目标是学习(来自两个域的标记或未标记样本),使得它在目标域上尽可能少地提交错误1。
。域适应任务则包括从源域到然后,目标是学习(来自两个域的标记或未标记样本),使得它在目标域上尽可能少地提交错误1。
主要问题如下:如果从源域学习模型,它能够正确标记来自目标域的数据的能力是多少?
不同类型的域适应域适应有几种情况。它们在为目标任务考虑的信息方面有所不同。
1、无监督域适应:学习样本包含一组标记的源示例,一组未标记的源示例和一组未标记的目标示例。
2、半监督域适应:在这种情况下,我们还考虑一组“小”标记的目标示例。
3、监督的域适应:所有考虑的例子都应该被标记。
三种算法原理重新加权算法目标是重新加权源标记样本,使其“看起来像”目标样本(根据所考虑的误差测量)。
迭代算法用于适应的方法包括迭代地“自动标记”目标示例。原理很简单:从标记的例子中学习模型h;
h自动标记一些目标示例;
从新标记的示例中学习新模型。
注意,存在其他迭代方法,但它们通常需要目标标记示例。
搜索公共表示空间目标是为这两个域找到或构建一个公共表示空间。目标是获得域彼此接近的空间,同时在源标记任务上保持良好的性能。这可以通过使用对抗机器学习技术来实现,其中鼓励来自不同域中的样本的特征表示难以区分。
本词条内容贡献者为:
王慧维 - 副研究员 - 西南大学

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国