

无监督聚类是深度学习中一种建模框架,无监督聚类只能够聚类成指定数量的类,但却不能够说明每一个类到底代表着什么。
评价指标对于无类标的情况,没有唯一的评价指标。对于数据凸分布的情况我们只能通过类内聚合度、类间低耦合的原则来作为指导思想,如下如: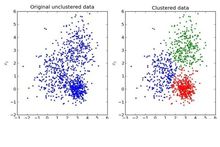
当然,有这些还不够,对于如下图所示的数据在N维空间中的不是凸分布的情况下,此时我们就需要采用另外的一些评价指标。典型的无监督聚类算法也很多,例如基于局部密度的LOF算法,DBSCAN算法等,在此种情况下的聚类效果就非常的优秀。1
目标优化在大多数我们已经学到的监督学习算法中类似于线性回归逻辑回归以及更多的算法,所有的这些算法都有一个优化目标函数或者某个代价函数需要通过算法进行最小化处理。事实上 K均值也有 一个优化目标函数或者需要最小化的代价函数。
算法的第一步就是聚类中心的分配,在这一步中我们要把每一个点划分给各自所属的聚类中心,这个聚类簇的划分步骤实际上就是在 对代价函数进行最小化。
随机初始化如何初始化K均值聚类的方法将引导我们讨论如何避开局部最优来构建K均值,我们之前没有讨论太多如何初始化聚类中心,有几种不同的方法可以用来随机初始化聚类中心,但是事实证明有一种效果最好的一种方法。
1.当运行K-均值方法时,需要有一个聚类中心数量K,K值要比训练样本的数量m小;
2.通常初始化K均值聚类的方法是随机挑选K个训练样本;
3.设定μ1到μk让它们等于这个K个样本。2
本词条内容贡献者为:
李斌 - 副教授 - 西南大学

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国