

内省排序(英语:Introsort)是由David Musser在1997年设计的排序算法。这个排序算法首先从快速排序开始,当递归深度超过一定深度(深度为排序元素数量的对数值)后转为堆排序。
简介内省排序(英语:Introsort)是由David Musser在1997年设计的排序算法。这个排序算法首先从快速排序开始,当递归深度超过一定深度(深度为排序元素数量的对数值)后转为堆排序。采用这个方法,内省排序既能在常规数据集上实现快速排序的高性能,又能在最坏情况下仍保持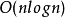 的时间复杂度。由于这两种算法都属于比较排序算法,所以内省排序也是一个比较排序算法。
的时间复杂度。由于这两种算法都属于比较排序算法,所以内省排序也是一个比较排序算法。
在快速排序算法中,一个关键操作就是选择基准点(Pivot):元素将被此基准点分开成两部分。最简单的基准点选择算法是使用第一个或者最后一个元素,但这在排列已部分有序的序列上性能很糟。Niklaus Wirth为此设计了一个快速排序的变体,使用处于中间的元素来防止在某些特定序列上性能退化为{\displaystyle O(n^{2})}的状况。这个3基准中位数选择算法从序列的第一,中间和最后一个元素获取中位数来作为基准,虽然这个算法在现实世界的数据上性能表现良好,但经过精心设计的序列仍能大幅降低此算法性能。这样就有攻击者精心设计序列发送到因特网服务器以进行拒绝服务(DoS)攻击的潜在可能性。
Musser研究指出,在为3基准中位数选择算法精心设计的100,000个元素序列上,introsort的运行时间是快速排序的1 / 200。在Musser的算法中,最终较小范围内数据的排序由Sedgewick提出的小数据排序算法完成。
在2000年6月,SGI的C++标准模板库的stl_algo.h中的不稳定排序算法采用了Musser的introsort算法。在此实现中,切换到插入排序的数据量阈值为16个。1
排序算法在计算机科学与数学中,一个排序算法(英语:Sorting algorithm)是一种能将一串数据依照特定排序方式进行排列的一种算法。最常用到的排序方式是数值顺序以及字典顺序。有效的排序算法在一些算法(例如搜索算法与合并算法)中是重要的,如此这些算法才能得到正确解答。排序算法也用在处理文字数据以及产生人类可读的输出结果。基本上,排序算法的输出必须遵守下列两个原则:
输出结果为递增序列(递增是针对所需的排序顺序而言);
输出结果是原输入的一种排列、或是重组。
虽然排序算法是一个简单的问题,但是从计算机科学发展以来,在此问题上已经有大量的研究。举例而言,冒泡排序在1956年就已经被研究。虽然大部分人认为这是一个已经被解决的问题,有用的新算法仍在不断的被发明。2
排序算法列表稳定的排序冒泡排序(bubble sort)
插入排序(insertion sort)
鸡尾酒排序(cocktail sort)
桶排序(bucket sort)
计数排序(counting sort)
归并排序(merge sort)
原地归并排序
二叉排序树排序(binary tree sort)
鸽巢排序(pigeonhole sort)
基数排序(radix sort)
侏儒排序(gnome sort)
图书馆排序(library sort)
块排序(block sort)
不稳定的排序选择排序(selection sort)
希尔排序(shell sort)
Clover排序算法(Clover sort)
梳排序
堆排序(heap sort)
平滑排序(smooth sort)
快速排序(quick sort)
内省排序(introsort)
耐心排序(patience sort)
不实用的排序Bogo排序
Stupid排序
珠排序(bead sort)
煎饼排序
臭皮匠排序(stooge sort)
本词条内容贡献者为:
李嘉骞 - 博士 - 同济大学

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国