

上下文无关解析就是对无关上下文的分析。
简介编程语言大部分是上下文无关语言,查询语言通常也是上下文无关语言。英语也可以看成是上下文无关语言。这些语言中的字符串需要用编译器、查询引擎和各种其他应用程序分析与解释。因此我们需要一个算法,给定上下文无关文法G,完成下列工作:
1.检查一个字符串,确定其是否L(G)的语法形式合理成员。
2.如果是,指定其解析树,描述其结构,从而作为进一步解释的基础。
编程语言真的是上下文无关语言吗?
已经有两种方法,可以从文法G构建一个决策过程,回答字符串W是否属于L(G)的问题。但我们还没有完事,还要回答下列问题:
1 第一个过程decideCFLusingGrammar要求Chomsky范式文法。第二个过程 decideCFLusingPDA要Greibach范式文法。我们希望使用自然文法,使解析过程生成自然解析树。
2 这两个过程都要搜索,时间与输入字符串长度成指数关系。但我们需要更高效的解析器,最好时间与输入字符串长度成线性关系。
3 这两个过程都确定L(G)中的成员关系,而不产生解析树。
查询语言是上下文无关语言。
这些问题的算法,组织如下:
1 简单问题:
2 实际建立解析树:我们介绍的所有解析树都采用语法规则进行工作。因此,要建立解析树,只要对解析树提供一个函数,每次采用一个规则时建立一个树块。
一用向前看文法减少非确定性:为了减少或消除非确定性,可以让解析树向前看下 一个或几个输入符号,然后确定进行什么操作。
3 辞典分析:这是个预处理步骤,各个输入符的字符串分成串大单位(令牌)的字符 串,然后输入解析树。
4 自顶向下解析树:
·简单但效率不同的递归向下解析树。
·修改文法进行自顶向下解析。
. LL解析。
5 自底而上解析树:
.简单而效率不高的Cocke—Kasami—Younger(CKY)算法。
·LL解析。
6 英文和其他自然语言解析。
上下文无关的效率底线上下文无关解析的效率底线如下。设n为要解析的字符串长度,则:
1 存在简单的算法(CKY),可以在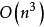 时间内解析任何上下文无关语言。尽管这比模拟所建立的非确定性PDA所要的指数级时间好,但对许多实际应用仍然不够好。此外,CKY要求文法为Chomsky范式。CKY还有一个更复杂的版本:可以在接近
时间内解析任何上下文无关语言。尽管这比模拟所建立的非确定性PDA所要的指数级时间好,但对许多实际应用仍然不够好。此外,CKY要求文法为Chomsky范式。CKY还有一个更复杂的版本:可以在接近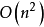 时间内解析任何上下文无关语言。
时间内解析任何上下文无关语言。
2 存在一个算法,可以使解析大部分上下文无关语言(包括许多我们关心的上下文无关语言,如大多数编程语言和查询语言)的时间减到Dm)。可以手工建立比较直观的自顶向下算法。还有更高效更复杂的由下而上算法,但利用一些工具可以方便地建立实用的自下而上解析器。1
3 英文和其他自然语言比解析大多数人工语言难,因为人工语言的设计可以考虑到解析效率。
本词条内容贡献者为:
李岳阳 - 副教授 - 江南大学

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国