

一.定义
社交网络中的行为是海量的、多种多样的。例如:撰写一篇博客,浏览一组照片,点击一个广告,购买一件商品,订阅特定新闻话题等等。我们的任务是预测社交网络中的行为。该问题可以被转化成多标签分类问题(Multi-label Classification)。
给定一个社交网络,并已知其中一些用户(节点)的行为标签信息,我们的任务是分类同一网络中其他未分类节点的行为标签。假设一个网络中的所有行为可以用K类标签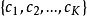 来描述,每个标签
来描述,每个标签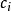 的值为1或0。比如,一个用户可能加入多个兴趣小组,
的值为1或0。比如,一个用户可能加入多个兴趣小组,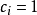 表示该用户加入了兴趣小组,否则
表示该用户加入了兴趣小组,否则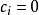 。我们的研究问题可以正式表述如下:
。我们的研究问题可以正式表述如下:
假设有K类标签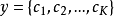 ,给定网络
,给定网络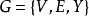 ,其中V是顶点集,E是边集,
,其中V是顶点集,E是边集,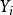 ⊆y是顶点
⊆y是顶点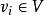 的类标签,并且已知道一些顶点
的类标签,并且已知道一些顶点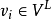 (
(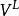 ⊆V)的
⊆V)的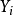 值,我们如何推断其余顶点
值,我们如何推断其余顶点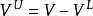 的 值(或针对每个标签的概率分布)?
的 值(或针对每个标签的概率分布)?
二.多标签分类方法关联分类方法(relational classifier)基于马尔科夫依赖性假设(Markov dependency assumption),利用行为标签间的依赖性来提升分类器的性能123。麦克斯卡西(Macskassy)等提出了的加权投票关联分类模型(weighted vote relational neighborhood classifier)4,该方法对于结构简单的网络分类较为有效,但难以处理异构网络中的行为标签分类问题。然而,许多真实世界的网络被认为是由多种类型的节点和链接组成的异构网络。因此,研究者提出一种基于潜在组(latent groups)56为异构网络连接或类标签建模的方法。Ji 等为异构信息网络,提出了一个基于排名的分类模型对标签排名7。当分类数据对象时,模型根据每个标签的重要性为每个对象排名,以提供标签的汇总信息。戈德堡(Goldberg)等发现在社交媒体中,即使节点间不是相似标签,该节点也会链接到另一个节点8。他们使用两条边的类型来表明链接对象之间是亲密或是分歧的类别标签,并且将链接类型信息引入到判定学习中。希瑟利(Heatherly)等引入了一个链接类型关系贝叶斯分类器,和其他链接类型一样,根据邻居的标签来预测节点的类别标签9。关联分类方法的优势在于利用邻接节点的标签信息,对于一些不太复杂且规模较小的关系数据,能够获得较好的分类精度。但节点的特征难以通过关联分类模型从数据中学习获得。因此难以描述节点和节点间的影响和互动关系。
唐(Tang)等提出了Edge-cluster算法来捕获每个实体潜在的关系,实现对节点社会特征的提取,再通过构造分类器实现标签分类,该方法能有效处理包含数百万边的网络1011。该方法的思想是通过抽取社会维来表达网络成员的潜在隶属社团来区分一个网络中的异构关系,并建议采用软聚类方案的社区隶属关系作为社会维度,再将社会维度视为节点的特征向量用于分类。
王(Wang)和苏克山噶(Sukthankar)提出了SCRN算法融合了关联分类器和社会特征提取方法12。利用社会特征计算网络中的每个实例与多标签的子集关联;同时引入一个类别传播概率,融合同质性和特征相似性,解决了异构网络多标签分类的问题。SCRN算法也有不足之处。它仅能利用与待分类节点直接相邻的节点,限制了对邻接信息的充分利用,且无法有效学习孤立节点的标签;同时该方法只能解决静态的网络分类问题,没有考虑特征与标签间的潜在时序因果关联,难以处理数据流环境的复杂行为标签学习问题。

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国