

增量编译技术的研究始于上世纪60年代末70年代初,并在80年代获得了大量的研究,使得增量编译理论得到了进一步的成熟。
增量编译技术,顾名思义,是在源程序已经完成第一次编译的基础上再次编译时采取的一种增量性编译技术。增量编译技术可以减少源程序再次编译的时间,这对于源程序只作了微小的改动,而要求再次编译时是非常有利的,它不仅可以提高软件开发的效率,还可以提高软件测试人员的效率。目前,增量技术已经广泛的运用于许多商用的集成开发环境当中。要实现增量编译技术,当然就需要对源程序第一次编译的结果进行有选择的保存,当对源程序再次编译时,可以在第一次编译的基础上进行增量计算,以实现增量编译。
增量编译程序建立在语法制导编辑器的基础之上,是语言集成化环境的重要组成部分。它对用户源程序局部修改后进行的重新编译的工作只限于修改的部分及相关部分的内容。相关部分的确定由系统完成,对用户是透明的。增量编译器的这种局部编译,对软件开发,尤其是在调试期,无疑会大大缩短编译时间,提高编译效率。
和传统编译器把多次输入的用户源程序都作为孤立对象相比,增量编译器保留了用户源程序的某些“历史”知识,所以报适合于集成化环境。同时,增量编译器还支持抽象级别上的程序设计方法学,为用户的编程和调试提供方便。1
增量编译方法目前,实现增量编译技术一般有三种方法:
第一种方法是首先确定编译的最小单元,当源程序修改后,以编译单元对源程序进行增量编译。
第二种方法是基于语法制导编辑技术,首先必须开发出语法制导编辑器,其中语法制导编辑器除了是用户输入源程序的接口,而且还动态维持着源程序的中间表示形式,一般是抽象语法树形式。当源程序发生修改,语法制导编辑器遍历抽象语法树,同时调用预先设计实现的例程,根据源程序所作的修改来完成所需的增量计算,主要是语法树的局部调整,以实现增量编译。
第三种方法是采用属性文法的实现方式,属性文法描述了源程序的语义,从属性文法的定义中,可以计算出语言属性之间的依赖关系,当源程序发生修改时,从属性文法中可以计算出源程序中需要重新编译的最小编译单元,以实现增量编译的目的。
基于最小编译单元该方法是最易于实现的一种方法,基本思想是:首先确定编译的最小单元,当程序发生改变时,以最小编译单元提取源程序代码,并对提取的代码进行增量编译。比如:对于以行为编辑单位的语言,如BASIC或Fortran语言,最小编译单元可以细到语句级别;而像过程式语言如C,Pascal,Smalltalk,最小编译单元可是过程或函数。当然还存在一些更为复杂的语言,其定义体间的交叉引用关系过于复杂,一条语句或一个定义的改变,可能导致程序许多地方需要重新编译,对于这种程序语言,对其实现增量编译有可能是无意义的。
该方法的另一个特点是具体实现方法的多样性,所以,该方法可以紧密的结合目标语言的语言特性,充分利用目标语言自身的特点,开发出适合该语言的增量编译方法。目前,该方法一般通过对编译的结果进行转储的方式来实现,最常见的是将其保存在外部存储器上,在下次编译时在将其调入内存。具体实现时,主要是对源程序编译后的中间表示形式进行保存,目前程序的中间表示形式大都是抽象语法树形式,所以就需要对整个语法树进行编码,压缩,并将其保存在外部文件中,当再次对源程序进行编译时;把外部文件的内存读入内存,恢复上一次编译时的语法树形式,并在此基础上实现增量编译。该方法的实现有一个关键就是语法树向外部文件转储的格式转换问题,如何对抽象语法树进行高效的编码,压缩并将其保存在外部磁盘上是该方法的一个关键点,也是难点,而且由于该方法存在大量的I/O操作,会严重影响编译的效率。由于以上所提到的原因,导致该方法并未在实际中得到大量的使用。
另一种实现方法也是对源程序的某种形式进行转储,但并不是对源程序编译后的中间表示形式进行保存,而是对源程序文本的结构信息进行保存。这主要是通过对源程序增加一遍扫描来实现的,增加的扫描过程并不涉及到对源程序语法,语义的理解,而是对源程序的文本结构进行记录,并通过外部文件的形式将其进行转储。当需要对源程序进行再次编译时,先对该程序完成一遍文本扫描过程,然后将扫描的结果与在外部文件中保存的数据进行比对,以此来标记源程序中发生修改的编译单元。此外,该方法所保存的数据要比保存源程序的中间表示形式要小很多,所以I/O操作的效率也较高。2
基于语法制导编辑基于语法制导编辑器的实现方法是目前实现增量编译的一般性方法,也为目前大多数的系统所采用,其中比较具有代表性的有ALOEEdito以及Gandalf项目。
该方法的基本思想是:语法制导编辑器负责调用编译器对输入的源程序进行编译,并维护源程序的中间表示形式,抽象语法树;所有的编辑操作除了一般意义上的文本操作外,其实都是对抽象语法树节点的操作;通过预先编写好的基于特定文法的诸多例程,当对源程序进行编辑的同时,语法制导编辑器遍历语法树,调用预先编写好的例程对语法树进行必要的操作以反映目前对源程序所作的修改。该方法打破了传统的“先编辑,后编译’’的方法,而且在编辑的同时也对源程序进行编译,并对语法树进行增量计算。该方法是以语法制导编辑器为基础,所以也称为基于语法制导编辑技术的增量编译方法。
语法制导编辑,顾名思义,就是整个程序的编辑是在语言语法的约束下完成的,语法制导编辑是在语法制导编辑器的引导下完成。语法制导编辑器的另一个重要任务就是要在源程序编辑的同时调用相应的语法分析器来对刚刚编辑的程序单位进行语法分析,语法分析器应当实现增量的功能,这样当程序修改后,语法分析只对程序中修改的部分进行语法分析,这样可以大大提高语法分析的效率,也可作为实现增量编译的基础。
语法制导编辑技术的研究开展于七十年代,在这之后取得了长足的进步。其中,由美国Comell大学开发的CPS系统是其中的代表之作。CPS采用的是模板驱动的方式,模板是预先定义好的,通过模板的展开来引导程序员自顶向下来开发程序。而在程序的内部表示中,模板则对应于语法中的非终结符。在国内,由中国科学院软件研究所研制的C语言结构编辑器也是基于模板驱动实现的,是结构编辑器的经典之作。
具体来说,模板由关键字,特殊符号和占位符构成,一个典型的模板展开形式如下图所示:
模板驱动的方式提供了一种有助于输入语法正确的源程序的方法,整个程序的输入是按照自顶向下通过一系列模板的展开而完成的。在CPS系统所描述的结构编辑技术中,对光标的位置作了严格的规定。在图的模板展开中,光标只能停留在占位符的下面,每次光标的移动实际上都是对程序内部表示的语法树节点进行操作,在这种基于结构编辑的实现方式下,编辑命令的实现过于复杂,更重要的是丧失了程序编辑的灵活性,而程序编辑的灵活性往往是大多数程序员所希望的。2
属性文法属性文法存在许多缺点:首先,属性文法定义了源语言语义的低级表示形式,而且还必须为源语言制定出适合增量计算的属性文法,而这一点本身并不容易做到,况且,对于有些语言,甚至很难制定出这样的文法;其次,该方法必须在语法树节点中保存大量的状态信息,否则一个变量声明的改变就有可能导致程序中大部分需要重新编译,所以该方法的实现要求对原有编译器的语法树结构及其符号表进行重新的设计,这显然不利于整个系统的设计与实现。2
编译程序工作流程编译程序的输入Verilog(标准硬件描述语言)设计源描述了词法分析和语法分析采用一遍扫描的策略。词法和语法分析程序使用Unix系统提供的词法、语法自动生成工具Lex和YACC生成。与编译有关的编译指令在词法分析部分予以处理,其它与模拟有关的编译指令保存在编译结果之中由模拟器处理。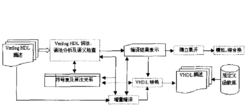
在编译器的构成中,增量编译部分的作用是利用已经建立的符号表和设计层次信息对修改模块及其影响到的模块重新编译,在编译后更新符号表、、蹬计层次关系和编译结果,并可调用VHDI,转换程序对重新编译的模块实行转换(转换以模块——实体/结构体对为单位)。
对应于Vefilog设计组成和增量编译的需要,编译结果和符号表都采取层次化的组织方式。顶层都是模块类对象链表。符号表内部分类记录了各种标识符的属性,按标识符的作用域进行组织,以提高查找的效率。
编译程序中的各项功能都是建立在符号表和设计层次关系的基础上。为了实现增量编译,将通常在确立阶段进行的设计层次信息提取提前到语法分析和语义检查中完成。这样做除了可以实现增量编译之外,还有利于VHDL转换程序的工作:VHDI中被侧示的实体/结构体必须首先声明,而Vefilog则没有这个要求,因此在转换时要根据设计层次关系从最低层的模块开始进行转换。3
未来发展趋势增量编译技术的目的是提高开发人员与测试人员的工作效率,但是增量编译技术也只能提高源程序二次编译的效率,并不能解决源程序首次编译的效率。展望下一步的工作主要有以下两个方面:一是对翻译文件的格式作进一步的优化,由于目前的翻译方案中存在有翻译代码过大的问题,该问题在整个系统实现中仍然还没有得到有效的解决,导致该系统在实际的工业测试中仍然存在着一定的缺陷,由于开放的编译环境,如:微软的Phoenix编译器的出现,定义一种更低级,高效,更易于优化的中间表示形式已成为可能,比如:三地址码格式,而且该中间表示形式更贴近机器语言,从而省去了由于翻译为C++文件而导致的对C++文件的编译过程,能够从根本上提高整个系统的执行效率,提高系统的可用性;二是通用的增量编译环境的开发,目前绝大多数的增量编译技术都是在语法制导编辑器的基础上实现的,虽然语法制导编辑技术存在灵活性上的缺陷,但是随着结构编辑技术的发展,该技术目前已在商用集成开发环境中有限的采用,所以开发基于语法制导编辑技术的增量编译器仍具有实际意义,而且基于语法制导编辑技术的增量编译方法由于在编辑的同时即对源程序进行编译从而更能发挥目前多核,多线程计算的优点。
另外,从长远的角度考虑,由于分布式技术以及互联网应用的进一步发展,构建一个支持分布式应用的测试系统是非常必要的,这仍然需要我们对基于编译执行的技术方案作进一步的改进与完善,这些都是值得尝试的研究方向。2

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国