

简介定义
印刷文本识别是指印刷在纸张上的中文或英文文档,用扫描仪或者其他光学方式输入后得到灰度或者二值图像,然后利用各种模式识别算法对文本图像中的文字进行定位,提取文字的特征,之后再与识别字典中的标准字符进行匹配判断,从而达到识别文档内容以及任意修改文档内容的目的。其实质是让计算机能够“看懂”输入文档的内容。1
研究背景随着信息时代的来临,各种各样的信息充斥在人们周围。信息存储和传播形式的多样性加大了信息处理的难度,如何快速、有效的管理、组织数量日益膨胀的信息,以方便检索、利用,是当今社会越来越迫切的需求之一,
可视化的信息,尤其是各种文档,一直是最重要的信息存储和传播形式之一,但是,传统的纸质文档不利于长期保存,且有不易检索、传播成本高且速度慢的缺点,具有强大多媒体处理能力的计算机出现后,人们开始广泛使用计算机处理和存储各种文档,并提出了无纸化办公的概念,但是,由于纸质文档阅读方便且阅读成本低,不需要特殊阅读设备,而且某些文档(如合同,证书等)必须以纸质形式保存,随着打印机等计算机输出设备的普及,纸质文档的数量不但没有减少,反而以比从前更快的速度增加,为了能够使用计算机管理、存储、传播和共享记录在纸张上的信息,必须将纸质文档通过扫描或人工录入等手段电子化,而靠人工将大量文本重新录入计算机显然是不现实的。目前,将纸质文档转化成电子化的最简单手段,是通过扫描仪等计算机输入设备将文档以图像格式输入计算机系统。2
研究历史及发展为实现从文档图像中自动提取其文字部分所包含的信息的目的,研究者们提出了光学字符识别(Optical Character Recognition,简称OCR)技术,事实上,OCR的概念早在数字计算机能够进行文字处理之前就被提出了。早在十九世纪,就有人申请了关于辅助盲人阅读和输入电报报文的OCR方面的专利,现代意义上的OCR是一个涉及到模式识别、人工智能、模糊数学、计算机科学等多学科的的综合课题,具有大概40年的发展史,19世纪五十年代,能够识别以特殊设计的字体(称为OCR字体)打印的数字的OCR系统首次投入商用,随着个人计算机、扫描仪等设备的迅速发展和普及,OCR系统的价格不断降低,从上世纪八十年代起,各种各样的OCR系统开始大量出现在市场上。汉字识别的研究虽然开始稍晚,但发展迅速,上世纪九十年代起,我国市场上开始出现多种汉字识别系统,汉王、清华文通、清华紫光等公司都相继推出了各种用于中文文本和特定格式表格(如机票、保险单)的OCR系统。2
印刷中文文档识别概述中文文档识别是指印刷在纸张上的中文文档,用扫描仪或者其他光学方式输入后得到灰度或者二值图像,然后利用各种模式识别算法对中文文档图像中的文字进行定位,提取文字的特征,之后再与识别字典中的标准字符进行匹配判断,从而达到识别文档内容以及任意修改文档内容的目的。其实质是让计算机能够“看懂”输入文档的内容。印刷体中文文档识别技术主要包括输入文档图像的预处理、识别和后处理三个阶段,其中文档的识别是难点和热点问题。
印刷中文文档识别技术属于文字识别的一种。文字识别技术又叫做OCR技术,经过近一个世纪的发展,OCR已经成为当今模式识别领域中最活跃的研究内容之一。它综合了数字图像处理、计算机图形学和人工智能等多方面的知识,并在计算机及其相关领域中得到了广泛应用。通常OCR识别方法可以分为如下3类:统计特征字符识别技术、结构特征字符识别技术和基于人工神经网络的字符识别技术。
目前,对于纯汉字的中文文档而言,现有的OCR技术已经有较高的识别率。然而,对于一些科技文档(汉字与数学公式混排)而言,现在还没有较成型的技术。这种中文文档识别起来就相对更复杂更困难些,首先,要将文档图像中的汉字和非汉字字符进行分离,因为汉字与其他字符有较大的区别无法混为一谈。其次,在提取特征时要注意根据不同字符的不同特征进行提取,最后,要根据不同字符的特征设计出不同的分类器。1
汉字识别的分类中国的汉字其数量是很多的,按GB2312-80标准汉字共有6763个,其中包括一级汉字3768个,二级汉字3008个。因此,汉字识别问题属于超多类模式集合的分类问题。目前汉字识别技术按照字体的不同可分为:
1)单体印刷体汉字识别(primed character recognition):仅识别某种单一印刷体字体或者某种打印机、照排机输出的文字。
2)多体印刷体汉字识别(multi-font printed character recognition):能识别出印刷出的多种字体文字,如黑体,宋体,楷体等等。
3)手写印刷体汉字识别(hand primed character recognition):用于识别人写在纸上的规整汉字,不能连笔,书写比较受限。
4)特定人手写体汉字识别(personal handwritten character recognition):是手写体识别的一个特例,笔迹鉴别也属于这一类。
5)非特定人手写体汉字识别(unconstrained handwritten characterrecognition):对于任何人自由书写的文字都能正确识别,这是手写体识别的最终目的。1
汉字识别的研究历程据文献记载,印刷体汉字的识别最早可以追溯到60年代。1966年,IBM公司的Casey和Nagy在一篇文章中利用简单的模板匹配法识别了1000个印刷体汉字。1977年东芝综合研究所研制了可以识别2000个汉字的单体印刷体汉字识别系统。80年代初期,日本舞藏野电气研究所研制了可以识别2300个多体汉字的印刷体汉字识别系统,代表了当时汉字识别的最高水平。此外,日本的三洋、松下、理光和富士等公司也有其研制的印刷汉字识别系统。这些系统在方法上,大都采用了基于K—L变换的匹配方案,使用了大量专用硬件,其设备有的相当于小型机甚至大型机,价格极其昂贵,因而并没有得到广泛的应用。
我国对印刷体汉字识别的研究开始于70年代末、80年代初,大致分为以下三个阶段:
1)第一阶段:从70年代末期到80年代末期,主要是算法和方案探索。
2)第二阶段:90年代初期,中文OCR由实验室走向市场,初步试用。
3)第三阶段:目前,主要是印刷体汉字识别技术和系统性能的提高,包括汉英双语混排识别率的提高和稳健性的增强。
虽然汉字识别在我国研究的起步较晚,然而经过多年的努力,印刷体汉字识别技术的发展和应用已有了长足的进步:从简单的单体识别发展到多种字体混排的多体识别,从中文印刷文档的识别发展到中英文混排的文档识别。
如今,各种汉字系统可以支持简、繁体汉字的识别,解决了多体多字号混排文本的识别问题,对于简单的版面可以进行有效的定量分析,同时汉字识别率己达到了98%以上。1
困难正如前面提到的,很多已有的文档识别OCR技术的汉字识别率已经相当可观。但是,现有的OCR技术在对于一些中文文档中出现的公式字符的识别问题还是存在着一些困难的。近些年,中文文档识别系统一直以来备受研究者的关注,但仍有一些困难还尚未解决。
中文文档图像版面内容是多样的,这就大大的加大了文档识别的难度。不能对版面中的每一个不同对象都采用同一个识别方法,为了实现文档中不同内容采取不同方式进行更加有效的处理,在文档识别系统中要加入可将原始文档图像中的不同内容进行分离的功能。
对于含有公式的中文文档而言,如何将汉字与公式字符分开是一直以来的难点,特别是对内嵌在汉字中的公式字符的定位是最为困难的,而且公式字符定位的好坏,可以直接影响到整个文档识别系统的识别率的高低。1
印刷英文识别印刷体英文识别,又称英文OCR,是文字识别领域的一个比较古老的分支。在本世纪初,国外就已经开始研究数字识别技术,并成功地应用于邮政编码的识别。
系统要求一个实用的印刷英文识别系统,至少应该是一个高性能的多字体、多字号的字符识别系统。高性能的字符识别系统首先对单字符具有极高的识别率,其次,它不但对质量好的文本图象有很高的识别率,而且还应有较强的鲁棒性,即使在文本图象质量较差(如文本中存在大量的噪声,笔画断裂严重或者多字符严重粘连等)的情况下仍能保持较高的识别率;对于多字体的要求,需要能够识别数百种常见字体,以及它们的各种变体包括黑体、斜体等;对于字号应有较广的适应范围,可以从小的( 号字一直到常见的文章大标题。前面两个问题的解决依赖于高性能的分类器设计和鲁棒的切分算法。后面两个问题,主要是通过对大量的不同字体不同字号的样本进行训练和归一化来解决。3
难点人们往往以为英文的类别(52个大小写字母、10个数字以及一些常用的符号)少,对印刷体英文的识别的难度就小。实际上,多字体印刷体英文的识别存在着如下几个难点:
字母宽度、大小不一,增加了切分的难度;
字符简单,包含的分类信息少,有些字符很相似,如“’1”、“I”、“l”、“|”等,较难区分;
字体千变万化,总的字体有上千种,常用的字体也有数百种,每一种字体还有黑体、斜体等的变化,而且不同字体间的差别很大,在字符的高度,宽度,笔画分布和笔画粗细等都有很大的变化;
常见字母组合在投影上为一整体,许多常见的字母组合象“fl’”、“fi ”、“ff”、等,实际上为不可分的整体,另有一些组合,象“fe”、“fo”等,特别在字体为斜体时,尽管字母之间互不粘连,但在投影上也是不可分的,虽然有些高级的切分技术象“绕切法”可以采用,却增加了不少的处理时间;
字母与字母的组合容易相互混淆,有些字母切分成两半后仍为合理的字母组合,像“m”变成“rn”;有些字母组合粘连在一起则可能成为合法的字母,象粘连的“cl ”变成“d ”。对于这些混淆,即使采用带回溯的切分方法或利用识别结果指导切分,都难以得到满意的结果;
英文字符本身结构简单,因此噪声影响明显,劣化文本图象的识别常常难度很大。3
系统的体系结构采用模块化的方法来进行系统的开发。为此,首先按照不同的功能和处理时间上的先后把系统分成主要的四大模块:预处理,行字切分,特征提取和分类器设计,后处理。实现的印刷体英文识别系统的构成框图见图。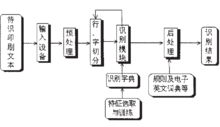
其工作过程大致如下:利用输入设备如扫描仪等,形成待识别印刷体英文文本的图象数据,对该数据进行预处理,主要是去除噪声及进行版面理解,接着将其中文本属性的图象块送入切分模块,进行行切分和字切分,切分后的结果便可以由识别模块进行识别,根据不同的识别方法,利用事先训练学习得到的识别字典进行模式分类,得到一个初步识别结果,这一结果还应经过识别后处理模块加以进一步纠错,例如可以利用一些简单的规则或采用查字典作拼法检查的方式等。在字符切分和识别模块之间,还有一个反馈的过程,利用识别结果的致信度来指导切分过程。3
行字切分行字切分是整个识别系统中极为重要的一个环节,因为正确的识别往往依赖于正确的切分。当切分错误时,很难得到正确的识别结果。如果行切分错误,常常会导致整行识别错误,严重影响系统的整体性能。在实际的文本中,由于断裂和粘连的存在,在字切分中也常常存在错切或者漏切,而降低系统的整体识别性能。现有的字符识别系统,对于单独的字符或者高质量的文本都能取得很高的识别率,但是对于严重粘连或者断裂的文本,识别率通常都很低,大部分的识别错误都是由于切分错误引起的。
在正常的扫描文本中,相邻两行之间都存在着空白行,因此可以采用对图象进行水平投影的方法来进行行切分,在投影值为" 的位置即为正确的切分位置。这种方法简单快捷,但是由于扫描操作不当,字符图象常常有一定程度的倾斜,再加上噪声的影响,以及一些字体造成的相邻行之间字符的粘连,使得水平投影不可分,用简单的投影难以得到正确的行切分。这时常用的是分段投影的方法,在短的分段内相邻文本行的投影依旧可分。
后处理要构建一个高性能的OCR 系统,有效的后处理是必不可少的。这是因为分类器在进行判决的时候往往孤立地对待一个个待识字符,而丢失了这些字符所处周围环境的一些重要的相关信息,这样的判决结果,尽管对于分类器具有较高的可信度,发生错误却是难免的。为了提高系统的性能,必须充分有效地利用上下文信息。常见的利用上下文信息的处理技术有:基于概率统计的方法、基于词典的方法以及混合方法等。基于概率统计的方法主要有马尔可夫方法和n元组方法两种。3
数学公式识别数学公式作为科技文献的重要组成部分,广泛存在于大量的科技文献中。这些公式对于在整篇文档中的地位往往非常重要,很多文档一旦失去了公式,将变得难于理解甚至毫无意义。目前,关于检索和重用包括数学公式在内的非文本的研究已经得到了广泛的关注,但是,现阶段的研究成果远远没有对于普通文本检索和重用成熟。数学公式一般由特殊符号、希腊字母、英文字符和数字组成,这些符号通常通过定义特定的格式输入计算机,输入复杂度远远大于普通的文本。如果依靠手工重新录入文档中的所有数学公式,将消耗大量的人力资源。如何实现文档中数学公式的高效率重复使用,一直是一个困扰着广大用户的问题。
目前,计算机在光学字符识别方面已经取得了很好的成绩,对普通文本的识别率已经达到了一个很高的水平.因此,研究者们设想,如果能利用计算机自动处理文档图像,从中提取出包含的公式,经过识别、分析、重组,最终转化成可编辑的通用格式(如LATEX格式的文本或Microsoft Word公式编辑器对象),将能够有效的扩展光学字符识别系统的应用范围。2

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国