

错误检测系统是保障信息系统持续安全稳定运行的重要手段,将文本检测、语音检测、安全检测等错误检测技术被广泛应用到医疗、金融等行业的信息化建设当中,提升系统持续安全稳定运行的能力。
文本检测命名实体识别命名实体(Named Entity)是语料中关键的词汇单位,承载了文本中的绝大部分的主要信息。最初,命名实体被定义为文本中包含人名、地名以及机构名的实体,例如在句子“[国际奥委会]主席[巴赫]访问[中国]”中,“国际奥委会”是机构名,“巴赫”是人名,“中国”是地名,通过这些命名实体就能获取到句子的主要内容。随着搜索引擎、机器翻译、数据挖掘等技术的不断发展,对于命名实体也有了更加宽泛的定义。而在医学临床以及生物相关领域,许多专有名词也陆续被学者们定义为命名实体,例如蛋白质名、基因名、疾病名等。在当今的自然语言处理研究中,普遍将命名实体分为名词、数字和时间这三种类型。
命名实体识别(Named Entity Recognition,NER)就是指识别文本中被定义为命名实体的专有名词,并加以归类。即命名实体识别的过程分为两个步骤,一是确定实体在文本中的语料边际;二是确定该实体的类型。由于数字类实体和时间类实体通常以时间、日期、货币、百分比等形式出现,具有固定的组成模式,通过正则表达式进行匹配便可以简单识别。所以,命名实体识别的主要困难是对名词类实体的准确识别,尤其是特定领域的专有名词。
命名实体识别作为自然语言处理研究的一个基本任务,在各类语言的自由文本中均有着广泛的研究。其中英文命名实体识别起步较早,取得了较好的研究成果,而中文命名实体识别的研究仍处在不太成熟的阶段。究其原因,除了发展较晚之外,主要有以下几点:
中文不像英文中单词与单词之间自然存在着空格作为分隔符,中文可以单字成词也可以多字组词,较于英文而言,对于实体边际的确定难度十分高;
中文的语言特性更为灵活多变,缩略词的组成规律和表现形式十分繁杂,很难形成既定的规则,而命名实体往往以缩略词的形式存在;
相较于英文,中文缺少对于词征的显性标志,比如英文中的专有名词通常以首字母大写或者大写全拼表示,而中文并没有这种特征。
因此,由于中文的这些特性,中文命名实体识别在进行识别操作前,往往需要对文本进行分词预处理,从而辅助实体边际的确定。2
中文分词技术目前常用的中文自动分词技术按照分词的策略可以分为基于规则和基于统计两大类。而近几年,为了提高对于未登录词识别的性能,基于宇的中文分词技术也逐渐发展起来,所以如若按照分词的最小考量粒度来分类,中文自动分词技术还可以分为基于词和基于字两大类。
1. 基于规则和字典的匹配分词
该方法通过构词规则以及足够庞大的分词字典作为知识来源,按照既定的规则对中文字串进行匹配分词。如若在字典中匹配到了一个词汇,那么就将被匹配项作为一个词进行切割。显然,基于规则的分词方法是基于词为最小考量粒度的方法。以反向最短匹配法为例,该种方法从文本末尾开始逆向切割分词,并通过截取最小长度来匹配字典,如果匹配失败再将匹配长度加l,如此往复,直至匹配项与字典中词条吻合。如果待匹配长度已经超过字典的最长词条长度或者匹配索引已经到达了文本首字符处,仍未匹配到词条,那么就将此次匹配的尾字作为单字词收录。可以发现基于字典和规则的匹配方法,实现难度较低并且操作简单,只要保证字典的权威性和数据容量足够大,就能完成词语的切割。但这种机械切割的方式很容易造成错误,譬如如果文本中存在“中华人民共和国”这个词汇,那么按照反向最短匹配算法进行分词处理后,文本中的“中华人民共和国”将被破坏为“中华”、“人名”、“共和国”3个零散的词语。而想要将诸如此类的构词形态纳入规则中去考虑,是十分繁琐的。
2. 基于统计学习的机器分词
基于统计学习的方法根据其是否使用事先编制的词典,可以分为基于字和基于词两种方法。基于字的分词方法,实际上是一种构词方法,即把分词过程看作是把句子中的每一个单字组成词的过程。主要思路是通过对训练语料进行字标注,统计得到各个字的标注特性组合的频次以及紧密程度,以此反映字与字之间能否成词的可信度。这类方法经常会误识别一些共现频度高、但不是词的常用字组,因此对常用词的识别精度较差,但是对于未登录词的识别性能却显著优于其他方法。2
语音检测错误检测系统在语音检测技术上的运用主要用于计算机辅助语言学习(Computer Assistant Language Learning,CALL)中的发音错误检测。现在的发音错误检测方法的研究主要有两大类。一类是基于语音学知识以及区分性特征的方法,另一类是基于统计语音识别框架的发音检错方法,在这两类方法中,基于统计语音识别框架的检测方法处于主流位置。3
音素发音质量HMM统计模型可以用来表示每个音素的标准发音,对数后验概率(Log-Posterior Probability,LPP)用于测试音素的发音质量。由于说话人特性的不同和信道的变化会导致输入信号的频谱不匹配,而该参数受频谱变化的影响较小,能更加集中的反映发音质量。
在实际的应用中,由于声学得分的动态范围非常大,会导致LPP值仅仅分布在几个很窄的范围内。因此,需要把声学得分做比例化处理,从而使得分具有可操作性。通过引入一个合适的比例化因子a,使得后验概率在0和1之间的分布更加均匀,经过比例化的LPP值在本文中称为比例化对数后验概率(Scaled Log-Posterior Probability,SLPP)。在一个基于HMM的语音识别器中,给定某个音素的观察矢量O和它对应的标注qi,该音素的SLPP值可计算如下:
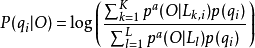
其中L是维特比(Viterbi)解码产生的网格(Lattice)中的路径总数,K是其中含有音素qi的路径总数,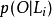 是网格中第l条路径的似然比,
是网格中第l条路径的似然比,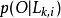 是网格中包含有qi的第k条路径的似然比,
是网格中包含有qi的第k条路径的似然比,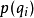 是音素qi的先验概率。3
是音素qi的先验概率。3
为了检测普通话的字发音错误,首先要获得每个音素的SLPP值。然后,每个字的得分就可以用其音素的SLPP值来做加权平均。由于普通话每个字一般都由声母和韵母组成,则字的发音质量得分可用下式表示:
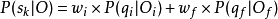
其中叫wi和wf是声母qi和韵母qf的权重。3
WEB错误检测WEB系统自动化错误检测系统改变了传统WEB功能菜单落后的人工巡检方式,,提高系统巡检工作效率,避免出现漏巡漏检的情况,促进运维资源优化分配;同时实现功能菜单巡检结果报表分析,为系统性能分析提供数据支持。
其实现步骤如下:
基础环境变量自定义,变量包括应用系统及数据库服务两个方面。应用系统方面主要有访问地址、端口、用户登录帐号、用户密码(密文);数据库服务方面主要有数据库地址、帐号、密码、查询功能菜单名与功能菜单URL的SQL语句(数据库相关变量只需在选择直连数据库方式获取功能菜单信息时配置,另一种获取功能菜单信息的方式是通过CSV配置文件);
创建数据库连接。第三方开源工具内置了JDBC驱动,只需要根据变量信息添加连接字符串即可完成数据库连接配置,正常执行数据库查询语句;
创建JDBC Request查询功能菜单。通过JDBC数据库连接,执行事先定义好的数据库SQL语句,查询被检测信息系统的所有功能菜单,查询结果包括菜单名称以及与之对应URL;
创建HTTP请求采样器。采样器将记录用户登录行为,获取访问过程中使用的会话ID、密码(密文),为后续系统菜单的检测工作提供必要的登陆信息;
创建HTTP请求采样器。采样器负责模拟用户访问菜单的行为,根据所有功能菜单的uRL逐一发起请求进行页面访问,然后记录每个功能菜单的访问结果,分析每一次URL访问是否正常;
创建断言规则。Jmeter将HTTP请求采样器的结果与断言规则进行比对,针对页面的返回值进行断言,通过检测的页面显示正常,没有通过检测则为异常,正常的结果代码显示为200,异常的结果代码有500、404、403等;
创建“察看结果树”。结果树主要方便阅读分析,可快速浏览检测过程中错误页面与正确页面的响应情况,展现各功能菜单的详细访问路径和请求信息。1
PBL方法入侵容忍系统(Intrusion Tolerance System,ITS)是第3代安全技术——信息生存技术中的核心内容,它是一种参考生物免疫原理的抵抗入侵的终极技术,作为应用系统的最后一道安全防线,即使在威胁性的环境下也要确保系统能动态安全退化,提供全部或降级的服务。错误检测(Error Detection ,ED)是保障ITS无边界退化的重要环节,其目标在于限制错误、避免蔓延以及确保在发现错误后能及时触发错误恢复机制和故障处理机制。
PBL正是一种面向容侵系统的并行错误检测方法。
相关定义定义1. 贝叶斯网格(Bayesian Network)是一种将贝叶斯概率和有向无环图的网络拓扑结构有机结合的表示模型,描述了元组数据项及元组和元组之间的相互依赖关系。和一个贝叶斯网络结构相同的无向无环图称为该贝叶斯网络的网架。
PBL方法中,一个贝叶斯网络可表示为(G, p),其中G-(V, E)是有向无环图,V是G的节点集,表示可描述容侵系统错误状态的系统事件集合,E是G的边,表示V中节点之间的概率联系。
定义2. 节点x1, x2∈V,x1和x2的条件互信息可表示为

其中S⊂V,若I(x1, x2))小于某一指定的阈值ξ,则称x1和x2条件独立。4
数据集初始化PBL方法从3个方面建立错误检测的模式数据库:
因系统软硬件原因导致的错误,诸如非法地址、强制性指令、数据类型不匹配、事件延迟等;
因外界入侵引起的系统错误;
相同的系统缺陷经不同复制可能引起不同的错误;
故而有必要对不同的拷贝对照检查,建立相应错误模式。
首先将训练数据转换到时序数据库,然后按时序顺序依次计算两个元组之间的互信息,并由大到小排序,最后依据不产生环路的原则按顺序依次添加边,直到添加n-1条边为止;然后将贝叶斯网络从根节点开始向下延伸,将复杂的贝叶斯网络拆分成若干个只有一个根节点的有向无环的图,以简化模式数据库。4
错误检测框架PBL并行错误检测框架如图1所示。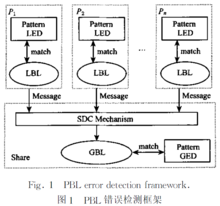 其基本思想是:
其基本思想是:
1. 设有处理器P1, P2, ..., Pn,各处理器在本地采集系统数据,再在这些数据集上通过LBL(local Bayesian learning)引擎构建本地贝叶斯网络(local Bayesian networks ,LBN);
2. 在每个处理器上,生成的LBN 和本地错误模式库(local error database ,LED)匹配,如果匹配则表示是本地系统错误;不匹配也不能表明没有错误发生,因为有可能是全局错误,故需将LBN 传送到全局共享区(Share )中做进一步判断;
3. Share 通过SDC(share data collection )机制选择性接受P1,P2,...,Pn传送来的数据,形成Share数据集;
4. 在Share 数据集上通过GBL(global Bayesian learni ng )引擎构建全局贝叶斯网络(global Bayesiannet Works ,GBN);
5.生成的GBN 和全局的错误模式库(global error database ,GED)匹配,如果匹配则表示是全局系统错误,不匹配则表示没有错误发生。4

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国