

介绍
我国社会信息化的发展速度一直维持在高水平,银行业作为领先的龙头行业,一直进行着大规模的信息技术工程建设。银行依托网络优势,按照公司治理架构和商业银行管理要求,不断丰富业务品种,不断拓宽营销渠道,不断完善服务功能,并提供更全面、更便捷的基础金融服务,成为一家资本充足、内控严密、营运安全、功能齐全、竞争力强的现代银行。同时,为了提高邮政储蓄银行的服务质量,推进邮政储蓄银行体制改革,实现生产管理的自动化和信息化,很有必要开发设计一个客户信息管理系统。
在实际开发过程中,不免遇到一些问题。比如如何处理大量数据的查询。在整个开发过程中,用到了几种方法,加快了大量数据的查询处理速度,在此进行一些探讨。
传统银行数据处理传统的交易处理是一种串行处理。例如" 客户从上取款"银行主机系统的处理流程如图所示,
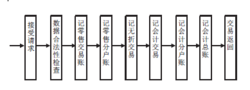
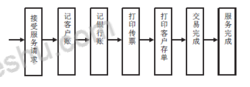
显然, 这样一个联机交易要占用较多的系统资源。数据大集中后,并发的业务请求很多,交易流程越短,就意味着占用系统资源越少,对提高整个系统的性能越有好处。随着银行信息化进程中,银行业的经营理念从以账户和产品为中心向以客户为中心转变,银行业务系统的设计也应该树立以客户为中心的思想。 长期以来,银行有一条原则是先记账后付款,银行需要较长的时间来记账,包括记客户账和银行账,还要打印银行所需要的各种传票。这种服务流程如图所示,
要更好地服务客户,缩短客户的等待时间,就必须改变银行的服务流程。 银行受理客户的服务请求,应该只处理与客户密切相关的事,银行的内部账。银行的内部传票可以在完成客户服务后再予以处理简化的服务流程如图所示: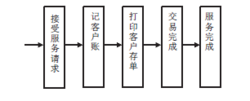
数据大集中后,相同信息集中存放,每一类信息的数量比数据集中前都大为增加,从而使数据的分类处理成为必然。 过去,一个程序往往可以用来完成几个甚至十几个数据库表的操作。 现在我们完全可以把分类的数据用不同的程序来处理,使每个程序做单一的事情。 如,可以写一个程序根据零售交易更新客户分户账,用另外一个程序写无折交易表。 会计交易、会计分户账、会计总账都用不同的程序来处理。
银行数据大集中后,对数据进行深层次的加工、处理,是银行信息系统要做的重要工作。 运用多级流水线技术,必将大大提高银行处理海量数据的效率。银行的数据要经过3 个加工阶段:联机的数据加工阶段,日终批量的数据加工阶段和数据的深加工阶段(运用数据仓库技术) 。 而客户通过银行应用系统做业务,产生基础数据的阶段,可称之为数据采集阶段。 我们可以把数据加工的3个阶段,分别交给3个以流水线方式工作的数据处理厂来完成。
数据大集中后,银行信息系统的设计是个庞大的系统工程。首先在架构上要有全新的思路,满足银行经营、管理、决策信息化的要求,同时还要面向未来银行业务虚拟化的趋势,在具体实现上采用先进的技术。
优化技术创建联合索引通常数据表只有一个索引,就是主键。但有时候做数据查询时,不单单使用主键作为查询条件,而可能用到多个字段作为条件。而对于信息系统,有些数据表又是无时无刻在做着查询操作,所以,可以对常用的查询建立联合索引以加快查询速度。
例如SQL语句:select * from tablewhere userid1="a" and userid2="b"。此类语句反复执行就可以为userid1字段和userid2字段建立联合索引了。
使用PreparedStatement语句系统运行过程中,面不了要对数据表进行反复的读取,所以数据链接这一环节也是非常重要。以往的数据连接都是使用Statement语句,但由于PreparedStatement对象已预编译过,所以其执行速度要快于Statement对象。因此,多次执行的SQL语句经常创建为PreparedStatement对象,以提高效率。
SQL语句优化合理的编写SQL语句能避免资源的浪费,提高执行效率。开发中要注意的问题有下列几点:
1.应当简化或避免对大型表进行重复的排序。
2.消除对大型表行数据的顺序存取。
3.避免困难的正规表达式。
4.可以多用临时表来空间换时间。
使用分页技术分页技术通常用于海量数据处理中。即把一张大表分割成几张小表。首先利用索引(或联合索引)将满足条件的记录的主键列插入到一个临时表,然后从该临时表中获取满足条件的记录总数,再从临时表中获取第N页的主键值集合,根据主键值集合从目标表中取出对应的记录以构成所要的页,最后释放临时表。
对海量数据进行分区操作对海量数据进行分区操作十分必要,分区和分页又有所不同。例如可以根据信息系统中客户的行业进行分类,然后进行分区,将不同的数据存于不同的文件组下,而不同的文件组存于不同的磁盘分区下,这样将数据分散开,减小磁盘I/O,减小了系统负荷,而且还可以将日志,索引等放于不同的分区下。
分批处理海量数据处理难因为数据量大,那么解决海量数据处理难的问题其中一个技巧是减少数据量。可以对海量数据分批处理,然后处理后的数据再进行合并操作,这样逐个击破,有利于小数据量的处理,不至于面对大数据量带来的问题,不过这种方法也要因时因势进行,如果不允许拆分数据,还需要另想办法。不过一般的数据按天、按月、按年等存储的,都可以采用先分后合的方法,对数据进行分开处理。
使用数据采样某些情况下,对大量的数据可以用数据挖掘,一般的方法就是采用数据抽样。但这种方法需要考虑全面,在保证数据的完整性的前提下来设计一个合理的抽样方法,可以大大提高数据处理的速度和成功率,并且也要把误差控制在一定的范围内。
考虑使用TXT文档系统对于读取数据库的速度和读取txt文档的速度是不同的,读写txt文档的速度要快很多。比如日志文件通常包含了海量的信息,而且日志文件也不断得进行着读写操作,更重要的是,很多应用程序或者系统的日志文件都是txt文档。所以在开发信息系统过程中,为了解决反复读取数据库所带来时间上的问题,在条件允许的情况下,可以使用txt文档做一些中转处理。
数据查询各种方法的使用,是要根据具体情况而定:可以提供的硬件环境如何;数据量有多大;使用哪些数据库工具和开发工具等等。1

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国