

简介
地下储层本身是确定的, 在每一个位置点都具有确定的性质和特征。但是地下储层又是很复杂的, 它是许多复杂地质过程如沉积作用、成岩作用和构造作用等综合作用的结果, 具有复杂的储层建筑格架的空间配置及其储层参数的空间变化。在进行储层描述过程中, 由于能够得到的资料总是不完备的, 所以人们很难在某一尺度下真实确定储层的特征或性质, 特别是连续性较差且非均质性严重的河流相或冲积扇储层。也就是说, 对地下储层的认识存在一定范围内的不确定性, 需要通过“ 猜测”“ 判断” 才能确定储层性质, 这就是储层建模的随机性。
随机建模认为储层井点间地质参数的分布及其变化有一定的随机性, 总会存在一些不确定因素。所以随机建模就是由已知信息为基础, 以随机函数为理论, 应用随机模拟方法对井点间的地质特征属性参数的分布及其变化给出多种可能的、等概率的预测结果, 提供给地质人员选择。
为什么用“ 随机” 的方法来描述“ 确定性” 的油藏各种参数呢, 其原因包括:
①开发井距多数在百米级以上, 井点控制的储层数据还是太少;
②采集到的资料存在一定的误差, 如测井解释地质属性, 靠岩心分析资料进行标定, 岩心柱塞体积只占油层体积的极小部分, 更何况取心井又占井孔的极少部分, 测井渗透率解释的误差经常可达百分之几十以上;
③油藏一些地质属性在很大程度上存在随机性, 如渗透率及泥质夹层的分布;
④人们对地下油藏的认识的不完善性, 有些参数只能通过预测加以“ 确定”。
总之, 随机性是客观存在的, 通过间接方法对井间储层属性作出的预测都带有不确定性。随机建模方法认为油藏或储层, 虽然各项属性均为的非均质分布, 但是有一定的地质成因控制, 存在一定的地质统计特征。用这一地质统计特征去表征储层非均质性的总体面貌, 可以在一定时间、一定条件下为油田评价提供合理的地质模型。由于随机模拟方法,可以得到多个可能的实现, 供地质人员进行选择: 乐观的、悲观的和最可能的估计, 减少油田开发决策的风险。1
随机模拟随机模拟的基本思路是从一个随机函数Z(u)中抽取多个可能的实现, 即人工合成反映Z(u)空间分布的可供选择的、等概率的实现,
在所建地质模型中对已有控制点资料不作任何修改, 完全忠实于原有控制点的资料, 如果使采样点的模拟值与实测值相同, 称为条件模拟。对控制点资料在建模中作修改的方法, 称非条件模拟。在随机函数中可以同时模拟几个变量, 其中一个简单替代方法是模拟最重要的或自相关性最好的变量, 然后通过它们的相关关系来模拟其他相关的变量。在油藏描述中, 可以先模拟给定岩相的孔隙度分布, 因为孔隙度在空间的变化幅度较小、自相关性好, 在给定孔隙度的条件下, 再模拟渗透率的分布。这种变量相关关系可直接从样品的渗透率和孔隙度的交绘图中得到。应用同样的方法, 可再模拟其他变量的分布。随机模拟的算法比较多, 几种常用的方法: 布尔法、序贯模拟和模拟退火法。
1 . 布尔模拟
布尔模拟算法是随机建模技术中最简单的一种方法。布尔模拟是一个“ 逐步逼近过程”, 认为在结构模拟中应从具有成因意义的目标创建, 不应一个个节点来模拟。依据相关的概率定律按照空间几何物体分布统计规律, 计算出这些物体的空间分布, 并按一定的先验关系, 确定物体中心点在空间的几何形状、大小和属性。
布尔模拟目前主要用于非条件模拟, 用来建立离散型模型, 适用于建立砂体格架模型或隔( 夹) 层分布模型, 如砂体格架平面、剖面或者三维空间分布模型。以泊松点过程为基础的模拟算法适合模拟砂岩背景上存在小尺度泥岩隔层这类现象; 以吉布斯点过程为基础的模拟算法适合模拟河道砂岩带内各河道砂体相互镶嵌的现象, 如模拟河道或河流—三角洲河道及相关的沉积相带。
该模拟算法的优点在于: 容易理解, 建模参数只需要单位体积目标平均个数和大小及方向分布函数; 另外, 该算法速度快。但是也有缺点: 井点数据对模拟结果的限制作用小, 可能会导致人为地低估砂体连续性; 目标形状是高度简化后的结果, 往往与实际情况相差较远。
近年来, 为了使布尔方法适合于多井情况( 条件数据较多) , 许多学者对布尔方法做了种种改进, 以忠实于条件数据。
2 . 序贯模拟
序贯模拟总体思路是沿着随机路径序贯地求取各节点的累积条件分布函数( CCDF) ,并从CCDF 中提取模拟值。其中, 用于求取CCDF 的条件数据不仅包括原始的样品点, 还包括已模拟好的点。这一模拟算法的主要目的是充分利用更多的条件数据来恢复变量的空间相关性。
随机函数Z( u) 的序贯模拟过程可分为以下几点:
① 随机地选择一个待模拟的网格节点;
② 估计该节点的累积条件分布函数CCDF;
③ 随机地从CCDF 中提取一个分位数作为该节点的模拟值;
④ 将该新模拟值加到条件数据组中;
⑤ 重复①—④ 点, 直到所有节点都被
模拟到为止, 从而得到一个模拟实现Z( 1) ( u) 。序贯模拟方法可用于高斯随机模拟和指示随机模拟, 其差别主要在CCDF 的求取方法不同。在序贯高斯模拟方法中, 所有的CCDF 将假设为高斯分布, 各模拟节点其均值和方差由正态分布, 否则用正态得分转换变为正态分布。而在序贯指示模拟中, CCDF 是直接由指示克里金方程组确定。
序贯模拟的优点:
①可模拟复杂的非均质模型, 如沉积相的分布方向及各种非均质性的比率, 该方法能保证每个指示变量使用一个变差函数;
②通过状态类型的频率和变差函数, 使模拟结果中包含地质趋势、指示变量之间交互作用;
③输入参数即指示频率及变差函数可由非规则的稀疏采样数据得到;
④可直接用点数据及非精确或模糊信息条件限制模拟结果。
序贯模拟的缺点:
①由于使用的指示变差函数不一致, 加上区域性概率是近似值, 模拟实现的变差函数不可能与原来使用的变差函数完全一致, 所以模拟结果可能会有些偏差;
②当对多个参数进行模拟时, 参数指示化和统计推断复杂时, 则指示间交互相关分析, 更复杂;
③计算速度不太快。
3 . 模拟退火模拟
模拟退火模拟算法是一种灵活、适应性强的优化算法, 该算法已成功的用于解决许多最优化的问题。近年来, 模拟退火模拟算法已广泛用于油气储层表征, 显示出其独到的优势。主要表现在两个方面: 首先是综合利用各种来源信息能力强, 这些信息包括岩心、测井、地震以及井间示踪剂试井等资料。第二, 模拟重现实验样品非均质性的效果好, 一般使模拟结果的参数分布( 直方图) 和变差函数( 或协方差) 与实验样品差异很小。其缺点是计算工作量大。
模拟退火模拟算法的基本原理是类比固体冷却退火方式(过程) 。高温下能达到所有可能的能量状态的分子随温度降低而重新排列, 达到最小能量状态; 冷却过快, 则系统在高能状态下达到规则排列, 即为淬火过程。
近年来, 为了减少计算工作量, 对该模拟算法进行改进, 新的算法层出不穷。主要有Metropalis 算法、热浴算法、协同模拟退火模拟算法和并行模拟退火算法等。1
分类根据研究现象的随机特征, 随机模型可分为两大类: 离散模型和边境模型。
1 . 离散模型
离散模型主要用于描述具有离散性质的地质特征, 如沉积相分布、砂体位置和大小、泥质隔( 夹) 层的分布和大小、裂缝和断层的分布、大小和方位等。离散模型的基本单元为基于目标物体的随机模型。即具有离散性质的地质特征, 如沉积相、流动单元等。这是一类以空间随机点过程的实现算法为基础的随机模拟技术, 最常用的是以泊松过程、吉布斯过程为基础的布尔算法。此外, 还有一些随机模拟算法亦可归入此类模型。
2 . 连续模型
连续模型主要用于描述连续变量的空间分布, 如孔隙度、渗透率、流体饱和度、地震层速度、油水界面等参数的空间分布。
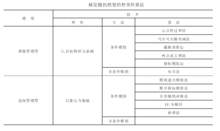 这类模型的基本单元为基于象元的随机模型(相当于网络化储层网格) , 既可用于连续性储层参数的模拟, 亦可用于离散地质体的模拟。该模拟算法包括模拟退火模拟、顺序指标模拟、分形随机模拟、马尔可夫随机域、转带法等。
这类模型的基本单元为基于象元的随机模型(相当于网络化储层网格) , 既可用于连续性储层参数的模拟, 亦可用于离散地质体的模拟。该模拟算法包括模拟退火模拟、顺序指标模拟、分形随机模拟、马尔可夫随机域、转带法等。
离散模型与连续模型的结合可以构成混合模型, 亦称二步模型, 即第一步用离散模型描述储层大范围的非均质性, 如沉积相、砂体结构或流动单元; 第二步应用连续模型描述各沉积相的砂体或流动单元内部的岩石物理参数的空间变化特征。
上述随机模型分类综合见右表。1
随机建模的步骤总体讲, 应当根据精细油藏描述的成果和要求, 选择合适的模拟方法, 建立需要精度的模型:
①基础油藏地质研究;
② 选择合适的模拟原形, 例如选择与地下对应的储层露头, 或者井距只有数十米的开发实验区, 作为模拟的原形;
③确定已知参数的统计规律,即从原形中提取储层参数, 并建立它们的变异函数、赫斯特指数等, 找出参数的约束条件(如沉积相对砂体厚度的约束等) ;
④ 选择合适的模拟方法, 目前多数选用的是条件模拟法;
⑤两步模拟: 先建立砂体厚度格架, 再模拟孔隙度等储层参数;
⑥间接建立渗透率模型, 渗透率是油藏地质模型中最重要的参数, 但是目前从沉积和地震等资料上还找不到直接建模的参数, 只能通过孔隙度等参数间接找出渗透率的模型;
⑦模拟结果的验证, 目前主要依靠地质家和油藏工程师的经验来验证;
⑧模型网格粗化, 理论上讲, 随机模拟可以得到任意尺度上的储层参数, 但是油藏地质模型的用户( 油藏工程师和油藏数值模拟工程师) 不需要网格尺度过小( 如1/ 4 井距) 的地质模型, 所以要粗化网格以适应于油藏流动网格的尺度。1

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国