

基本概念
向量处理器系统(Vector Processor System,VPS),是面向向量型并行计算,以流水线结构为主的并行处理计算机系统。 采用先行控制和重叠操作技术、运算流水线、交叉访问的并行存储器等并行处理结构,对提高运算速度有重要作用。但在实际运行时还不能充分发挥并行处理潜力。向量运算很适合于流水线计算机的结构特点。向量型并行计算与流水线结构相结合,能在很大程度上克服通常流水线计算机中指令处理量太大、存储访问不均匀、相关等待严重、流水不畅等缺点,并可充分发挥并行处理结构的潜力,显著提高运算速度。
向量运算是一种较简单的并行计算,适用面很广,机器实现比较容易,使用也比较方便,因此向量处理机(向量机)获得了迅速发展。TI ASC(1972年)和CDC STAR-100 (1973年)是世界上第一批向量巨型计算机(巨型机)。到1982年底,世界上约有60台巨型机,其中大多数是向量机。中国于1983年研制成功的每秒千万次的757机和亿次的“银河”机也都是向量机。
向量机适用于线性规划、傅里叶变换、滤波计算以及矩阵、线性代数、偏微分方程、积分等数学问题的求解,主要解决气象研究与天气预报、航空航天飞行器设计、原子能与核反应研究、地球物理研究、地震分析、大型工程设计,以及社会和经济现象大规模模拟等领域的大型计算问题。
向量运算在普通计算机中,机器指令的基本操作对象是标量,而向量机除了有标量处理功能外还具有功能齐全的向量运算指令系统。
对一个向量的各分量执行同一运算,或对同样维数的两个向量的对应分量执行同一运算,或一个向量的各分量都与同一标量执行同一运算,均可产生一个新的向量,这些是基本的向量运算。此外,尚可在一个向量的各分量间执行某种运算,如连加、连乘或连续比较等操作,使之综合成一个标量。为了提高向量处理能力,基本型向量运算在执行中可以有某种灵活性,如在位向量控制下使某些分量不执行操作 ,或增加其他特殊向量操作,如两个维数不等的单调上升整数向量的逻辑合并、向量的压缩和还原。
向量处理器系统基本结构一个向量处理器通常由一个普通的流水化的标量单元加上一个向量单元组成。在这个向量单元里的所有功能部件都有几个时钟周期的延迟。这使得能够使用较短的时钟周期,并且与复杂的需要深度流水化来避免数据 hazard的向量运算兼容。大多数的向量处理器所允许的向量运算包括浮点运算,整型运算或者逻辑运算。这里我们重点关注浮点运算。实际上商用的向量处理器里面都同时包含了乱序的标量单元(NEC SX/5)和VLIW的标量单元(Fujitsu VPP5000)。
向量处理器主要有两种类型:向量-寄存器(vector-register)处理器和内存-内存(memory-memory)处理器。在vector-register类的处理器中,所有的向量操作,除了load和store都是在向量寄存器(vector register)里面进行的。这类的处理器就和我们在标量处理器里面谈过的load-store体系结构相对应。在80 年代后期发布的几乎所有向量计算机都采用了这个结构,这其中包括Cray Research的处理器(Cray-1,Cray-2,X-MP,YMP,C90,T90,SV1 和 X1),日本的超级计算机(从NEC SX/2 到 SX/8,Fujitsu VP200到VPP5000,以及Hitachi S820 和 S-8300)以及迷你超级计算机(从 Convex C-1 到 C-4)。在 memory-memory 类的向量处理器中,所有的向量运算都是从内存到内存的。第一个向量处理器就是这种类型,CDC 系列的亦是如此。
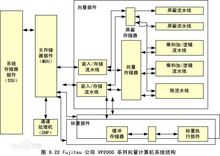
下图是Fujitsu VP2000系列系统结构图:
向量体系结构的优势向量超级计算机的市场已经非常小了,但是向量超级计算机所使用的向量指令体系结构(Vector Instruction Set Architecture VISA)和它的向量指令集是依然很有优势的。随着集成度的提高,我们很快将达到“延时极限”,而向量指令系统结构提供了提高性能的一种途径。
VISA相对于标量以及VLISW ISA的优势可以从三个方面来归纳。其一:语义优势,也就是说用VISA来书写程序能更简洁更有效。其二:向量指令可以更容易实现并行化的编码,利于高度并行化的实现。其三:向量指令工整而且它有利于并行化,这使得向量指令有利于提高设计处理器技术,比如深度流水线的设计,资源重复的实现,以及缩短时钟周期。以下几点充分地体现了向量指令集的优势:
(1)向量程序精简,所需操作步数少
向量指令和标量指令最大的差别在于一条向量指令包含了很多操作。因此,执行一个给定的任务,向量指令比标量指令组成的程序要少得多。而且标量程序要计算地址,循环变量和分支地址,而这些都是隐含在向量指令里的。执行代码量的减少带来了很多有益的结果,首先,指令数量减少使得主存和处理器之间的数据交换量也随着减少;其次,向量操作中分支指令的执行被隐含起来,这样也就减少了大部分由于分支预测失误带来的延时;再次,仅需一个很简单的控制单元,在每个周期取一条指令译码执行,可以得到很高的运算效率。所以,向量指令集在执行的时候只需要很简单的控制器,避免了在运行的时候花费过多的时钟周期。
(2)存储系统的性能高,利用充分
以向量的方式来访问内存有很多好处。首先:处理机所需的每个数据项都是真正所要用到的数据,而不是由Cache来支持的所谓的预取。其次:访存的信息直接由硬件来传输,这些信息能够通过很多方法来提高存储系统的性能。当遇到存储器延时,对内存操作的向量指令能够把一段长的延时划分为很多小的时间段。一些研究已经表明在向量处理器上使用类似于超标量流水线的技术,即使是上百个周期的主存延时,也不会造成太大的性能损失。
(3)向量处理器具有低功耗和高实时性的特征
针对未来的应用系统,低功耗和高实时性会成为计算机设计中一个很重要的因素。而在这方面,向量体系结构的系统具有相当的优势。
向量指令具有“局部计算”的特性,也就是说,当一条向量指令开始执行,只有对应的功能单元和寄存器内联总线需要加电。取指部件,取指缓冲寄存器等其它大功耗部件可以处于休眠状态,直到当前向量指令执行完成才恢复状态重新工作。使用了向量ISA的系统可以方便地工作于低功耗状态。例如,某运算需要两条向量指令并行执行,或同一条指令需要执行两次,仅需要最少的功能部件和总线部件工作,而不象超标量处理机那样重复取相同的循环指令来执行,从而可以很方便的减小功耗。针对实时应用程序,向量计算机可以被设计为具有高度可预测、高度自主决策的系统。提高实时性能时,令设计者头疼的Cache失效和分支预测的问题将不再需要考虑,向量体系结构高度结构化的特征使得向量体系结构简单、可决策化,具有高实时性的潜力1。
应用向量机一般配有向量汇编和向量高级语言,供用户编制能发挥具体向量机速度潜力的向量程序。只有研制和采用向量型并行算法,使程序中包含的向量 运算越多、向量越长,运算速度才会越高。面向各种应用领域的向量程序库的建立,能方便用户使用和提高向量机的解题效率。向量识别程序是编译程序中新开发的一部分,用于编译时自动识别采用通常串行算法的源程序中的向量运算成分,并编译成相应的向量运算目标程序,以提高向量机计算大量现存非向量程序的计算速度。向量识别技术还有待进一步发展和完善,以提高识别水平。
向量处理机的发展方向是多向量机系统或细胞结构向量机。实现前者须在软件和算法上取得进展,解决如任务划分和分派等许多难题;后者则须采用适当的互连网络,用硬件自动解决因用户将分散的主存当作集中式的共存使用而带来的矛盾,才能构成虚共存的细胞结构向量机。它既具有阵列机在结构上易于扩大并行台数以提高速度的优点,又有向量机使用方便的优点。

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国