

简介
千兆级计算是指一台计算机的峰值计算速度可以达到万亿次每秒。即一个PFLOPS(petaFLOPS)等于每秒一千兆(=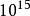 )次的浮点运算。千兆级计算实现的最大推动力高性能计算和超级计算的需求。例如石油勘探、天气预报等领域,还有社会上各种数据的不断增长(大数据)都要求计算机有较快的计算速度。千兆级计算的实现需要有关技术支撑,如计算机水冷系统,主要解决计算机散热问题。
)次的浮点运算。千兆级计算实现的最大推动力高性能计算和超级计算的需求。例如石油勘探、天气预报等领域,还有社会上各种数据的不断增长(大数据)都要求计算机有较快的计算速度。千兆级计算的实现需要有关技术支撑,如计算机水冷系统,主要解决计算机散热问题。
每秒浮点运算次数每秒浮点运算次数(每秒峰值速度)是每秒所执行的浮点运算次数(Floating-point operations per second;FLOPS)的简称,被用来估算电脑效能,尤其是在使用到大量浮点运算的科学计算领域中。因为FLOPS字尾的那个S代表秒,而不是复数,所以不能够省略。
浮点运算实际上包括了所有涉及浮点数的运算,在某类应用软件中常常出现,比较整数运算更用时间。现今大部分的处理器中都有浮点运算器。因此每秒浮点运算次数所量测的实际上就是浮点运算器的执行速度。而最常用来测量每秒浮点运算次数的基准程式(benchmark)之一,就是Linpack。
有关换算一个MFLOPS(megaFLOPS)等于每秒一佰万(=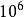 )次的浮点运算,
)次的浮点运算,
一个GFLOPS(gigaFLOPS)等于每秒拾亿(=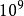 )次的浮点运算,
)次的浮点运算,
一个TFLOPS(teraFLOPS)等于每秒一兆(=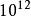 )次的浮点运算,
)次的浮点运算,
一个PFLOPS(petaFLOPS)等于每秒一千兆(=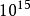 )次的浮点运算,
)次的浮点运算,
一个EFLOPS(exaFLOPS)等于每秒一佰京(= )次的浮点运算。
)次的浮点运算。
超级计算计算数学的重要概念:指超级计算机及有效应用的总称。而超级计算机或称巨型机(super computer)指能解决复杂计算的大型、非常快速、价格昂贵的计算机,通常这类机器还具有流水线部件和执行向量运算指令等功能。IDC(国际数据集团公司)关于超级计算与超级计算机之间差别的说法是:超级计算是用计算机去研究、设计产品及支持复杂的决策;而超级计算机则是解决上述问题的计算机.因此,超级计算不能混同于超级计算机,其内涵除了属于最领先的计算硬件系统外,还应包括着软件系统和测试工具、解决复杂计算的算法、应用软件与通用库等。1
高性能计算(High Performance Computing, HPC ),指高性能计算机连同有效应用。而高性能计算机指传统超高速计算机和多个CPU组成的并行计算机。
因此,可以说高性能计算蕴涵着超级计算而且比超级计算词义更为广泛。然而在实际使用上一般似乎不大区分这两个词。这里指出,人们可以相仿地表述并行计算,以及并行计算与并行计算机之间的差别。
值得强调的是,上述说法中把高性能(或超级)计算机和有效应用两件事摆在同样重要的位置。一方面,如果没有高性能计算机的迫切的非它不可的应用需求,发展高性能计算机就会没有依据和市场。美国政府1991年制定“高性能计算与通信(HPCC)”计划的核心正是确认和研究一组“重大挑战”应用课题,这类课题涉及气候与气象、污染、材料、分子与原子、流体、燃烧等难以一一列举,它们需要每秒万亿次的计算机,解决难度很大,日本政府也于1992年颁布“真实世界计算(RWC)"计划,旨在模仿人类凭直觉判断问题的方式,处理真实世界中那些模糊的、复杂的、不确定的信息,形成信息处理新风范,目标包括含100万个处理机的并行计算机和有100万个单元的神经网络系统。另一方面,即便有了高性能计算机和重大课题,也未必就能用好计算机有效解决课题。事实上多数高性能计算机好造不好用(或没用好)而匆匆被载人史册。因此,为发发展高性能计算,不能重硬(机器)轻软(应用),必须给应用投资,检验其水平最终也应看解决了哪些重大课题。
有关技术计算机水冷系统计算机水冷系统,是计算机常用的液体冷却系统。是指以高比热系数的液体(如:水)作媒介,以协助带走内部零件的热量。一套完整的计算机水冷系统,一般会有:导热金属接触面、
冷却液、耐高温软水管、直流水泵、水流控制电路、温度检测电路、水位报警电路、散热排。
而电子零件的工作热量是以金属接触面传导至冷却液,经PU水管把加热了的冷却液流至散热排处散热降温,水泵则在过程中不断对液体加压,使PU水管内液体不断流动,就形成以液体循环冷却的作用。
优点
循环冷却作用下温度波动小,被冷却零件控温效果明显,长时间使用稳定可靠;
使用直流(无刷)电泵时振动小,噪音低;
整体装配后外观华丽,静电吸附小。
缺点
水冷散热器所需的加工工艺较高,且装配后成品体积较大,占用了一定的空间;
因为系统结构繁复,且对配件质量有一定的要求,因而维保费用高;
配装工艺较高,要求操作人员有一定的专业知识;
组成配件较多,成本较高。
安装不当会令冷却液流出,造成主板短路。
非均匀访存模型非统一内存访问架构(Non-uniform memory access, NUMA)是一种为多处理器的电脑设计的内存,内存访问时间取决于内存相对于处理器的位置。在NUMA下,处理器访问它自己的本地内存的速度比非本地内存(内存位于另一个处理器,或者是处理器之间共享的内存)快一些。
非统一内存访问架构的特点是:被共享的内存物理上是分布式的,所有这些内存的集合就是全局地址空间。所以处理器访问这些内存的时间是不一样的,显然访问本地内存的速度要比访问全局共享内存或远程访问外地内存要快些。另外,NUMA中内存可能是分层的:本地内存,群内共享内存,全局共享内存。
NUMA架构在逻辑上遵循对称多处理(SMP)架构。它是在二十世纪九十年代被开发出来的,开发商包括Burruphs(后来的优利系统),Convex Computer(后来的惠普),意大利霍尼韦尔信息系统(HISI)(后来的Group Bull),Silicon Graphics公司(后来的硅谷图形),Sequent电脑系统(后来的IBM),通用数据(EMC),Digital(后来的Compaq,现惠普)。这些公司研发的技术后来在类Unix操作系统中大放异彩,并在一定程度上运用到了Windows NT中。
首个基于NUMA的Unix系统商业化实现是对称多处理XPS-100系列服务器,它是由VAST公司的Dan Gielen为HISI设计。这个架构的巨大成功使HISI成为了欧洲的顶级Unix厂商。
矢量处理器矢量处理器是专门设计的高度流水线作业的处理器。矢量处理器能够对整个矢量个矩阵上行高效率的操作,这类处理器非常适合于能从高度并行执行中受益的应用程序。

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国