

集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning)。
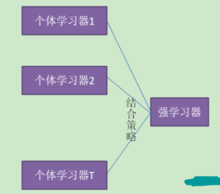
图1显示出集成学习的一般结构:先产生一组“个体学习器”,再用某种策略将它们结合起来。个体学习器通常由一个现有的学习算法从训练数据中产生,例如C4.5决策算法、BP神经网络算法等,此时集成中只包含同种类型的个体学习器,例如“决策树集成”中全是决策树,“神经网络集成”中全是神经网络,这样的集成是“同质”的。同质集成中的个体学习器亦称为“基学习器”。相应的学习算法称为“基学习算法”。集成也可包含不同类型的个体学习器,例如,同时包含决策树和神经网络,这样的集成称为“异质”的。异质集成中的个体学习器由不同的学习算法生成,这时就不再有基学习算法,常称为“组件学习器”或直接称为个体学习器。1
集成学习通过将多个学习器进行结合,常可获得比单一学习器更加显著的泛化性能。这对“弱学习器”尤为明显。因此集成学习的理论研究都是针对弱学习器进行的,而基学习器有时也被直接称为弱学习器。但需注意的是,虽然从理论上说使用弱学习器集成足以获得很好的性能,但在实践中出于种种考虑,例如希望使用较少的个体学习器,或是重用一些常见学习器的一些经验等,人们往往会使用比较强的学习器。
在一般经验中,如果把好坏不等的东西掺到一起,那么通常结果会是比最坏的要好些,比最好的要坏一些。集成学习把多个学习器结合起来,如何能得到比最好的单一学习器更好的性能呢?
分类器集成示例考虑一个简单的例子:在二分类任务中,假定三个分类器在三个测试样本的表现如图2,其中,√ 表示分类正确,× 表示分类错误,集成学习的结果通过投票法产生,即“少数服从多数”。在图2(a)中,每个分类器只有66.6%的精度,但集成学习却达到了100%;在图2(b)中,三个分类器没有差别,集成之后性能没有提高;在图2(c)中,每个分类器只有33.3%的精度,集成学习变得更糟。这个例子显示出,要想获得好的集成,个体学习器应“好而不同”,即个体学习器要有一定的“准确性”,即学习器不能太坏,并且要有“多样性”,即学习器间具有差异。

分析:
考虑二分类问题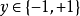 和真实函数 f ,假定基分类器的错误率为
和真实函数 f ,假定基分类器的错误率为 ,即对每个基分类器
,即对每个基分类器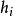 有:
有:
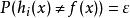 假设集成通过简单投票法结合T个基分类器,若有超过半数的基分类器正确,则集成分类就正确:
假设集成通过简单投票法结合T个基分类器,若有超过半数的基分类器正确,则集成分类就正确:
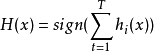
假设分类器的错误率相互独立,则由Hoeffding 不等式可知,集成的错误率为:
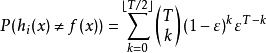
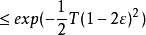 上式显示出,随着集成中个体分类器数目的增大,集成的错误率将指数级下降,最终趋向于零。
上式显示出,随着集成中个体分类器数目的增大,集成的错误率将指数级下降,最终趋向于零。
然而我们必须注意到,上面的分析中有一个关键性的假设:基学习器的误差相互独立。在现实任务中,个体学习器是为解决同一个问题训练出来的,它们显然不可能独立。事实上,个体学习器的“准确性”和“多样性”本身就存在着冲突。一般的,准确性很高之后,要增加多样性就必须牺牲准确性。
事实上,如何产生并结合“好而不同”的个体学习器,恰恰是集成学习研究的核心。
结合策略平均法对于数值类的回归预测问题,通常使用的结合策略是平均法,也就是说,对于若干和弱学习器的输出进行平均得到最终的预测输出。
最简单的平均是算术平均,也就是说最终预测是
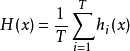
如果每个个体学习器有一个权重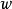 ,则最终预测是
,则最终预测是
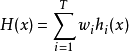 其中,其中
其中,其中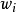 是个体学习器
是个体学习器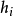 的权重,通常有
的权重,通常有
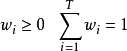
对于分类问题的预测,我们通常使用的是投票法。假设我们的预测类别是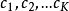 ,对于任意一个预测样本x,我们的T个弱学习器的预测结果分别是
,对于任意一个预测样本x,我们的T个弱学习器的预测结果分别是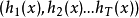 。
。
最简单的投票法是相对多数投票法,也就是我们常说的少数服从多数,也就是T个弱学习器的对样本x的预测结果中,数量最多的类别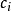 为最终的分类类别。如果不止一个类别获得最高票,则随机选择一个做最终类别。
为最终的分类类别。如果不止一个类别获得最高票,则随机选择一个做最终类别。
稍微复杂的投票法是绝对多数投票法,也就是我们常说的要票过半数。在相对多数投票法的基础上,不光要求获得最高票,还要求票过半数。否则会拒绝预测。
更加复杂的是加权投票法,和加权平均法一样,每个弱学习器的分类票数要乘以一个权重,最终将各个类别的加权票数求和,最大的值对应的类别为最终类别。
学习法对弱学习器的结果做平均或者投票,相对比较简单,但是可能学习误差较大,于是就有了学习法这种方法。对于学习法,代表方法是stacking,当使用stacking的结合策略时, 我们不是对弱学习器的结果做简单的逻辑处理,而是再加上一层学习器,也就是说,我们将训练集弱学习器的学习结果作为输入,将训练集的输出作为输出,重新训练一个学习器来得到最终结果。
在这种情况下,我们将弱学习器称为初级学习器,将用于结合的学习器称为次级学习器。对于测试集,我们首先用初级学习器预测一次,得到次级学习器的输入样本,再用次级学习器预测一次,得到最终的预测结果。
典型集成学习方法根据个体学习器的不同,目前集成学习方法大致可分为两大类:即个体学习器间存在强依赖关系,必须串行生成的序列化方法以及个体学习器间不存在强依赖关系、可同时生成的并行化方法;前者代表是Boosting,后者代表是Bagging和“随机森林”。

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国