

基本概念
决策树归纳学习与模糊决策树归纳学习分别是归纳学习与模糊归纳学习的一个重要分支,ID3是决策树学习算法的代表,模糊ID3和Min-U是模糊决策树学习算法的代表1。
模糊决策树算法是传统决策树算法的一个扩充和完善,使得决策树学习的应用范围扩大到了能处理不确定性。模糊决策树学习的归纳结果与传统的比较,由于合理地处理了不精确信息,从而有着更强的分类能力及稳健性,使得知识表示的方式更为自然。由于能生成不同水平和不同置信度的推理规则,故而提供了一种构造专家系统的有效途径,并可为决策者提供丰富的决策信息。
决策树设E是一组分类例子集合,A为一组描述例子特征(属性)的集合,T(E)是一个决策树归纳的停止准则,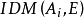 是一个评价函数,
是一个评价函数,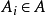 。决策树的描述过程如下:
。决策树的描述过程如下:
如果E满足停止准则T(E),
那么返回该树的叶结点,标记E中的最多数目的例子类别;
否则选择一个特征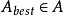 使得
使得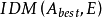 的值最大;
的值最大;
对特征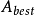 的每一个取值
的每一个取值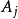 ,递归生成子树
,递归生成子树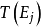 (其中
(其中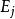 由E中特征 取值为
由E中特征 取值为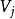 的例子组成)返回一个非叶结点, 标记分类特征为 ;
的例子组成)返回一个非叶结点, 标记分类特征为 ;
结束。
从决策树的描述发现,建立决策树的核心在于评价函数 和停止准则T(E)如何确定。
模糊决策树模糊决策树是决策树的一种推广。
设
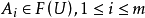
是给定的m族模糊子集,且满足
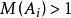
如果一个有向树满足:
(1)树中的每个结点属于F(U);
(2)对树中每一个非叶结点N,它的所有子结点将是F(U)的一个子集族,记为X,则存在i(1≤i≤m),使得
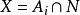
(3)每一叶结点对应一个或多个分类决策值。
则称其为一个模糊决策树,每一组模糊子集对应于一个属性。
模糊决策树系统结构以决策树作为学习机制构建以规则为中心的专家系统,具有易理解灵活、构造速度快等特点。采用模糊决策树方法为学习机制,利用模糊决策树抽取规则构造知识库,可以实现一个小型的通用专家系统2。如图所示:
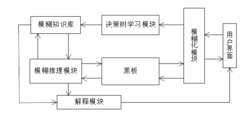
各模块构造方法如下:
(1)模糊化模块采用三角型模糊化方法将数据模糊化;
(2)决策树学习模块以Min-Ambiguity为启发式构建决策树;
(3)模糊推理模块采用max-min算子进行规则推理;
(4)知识库知识的表示采用规则表示法这种表示法有许多优点如模块性清晰性自然性等;
(5)解释模块采用图形化方法将结果表示为树型;
(6)黑板采用全局静态对象机制实现;
(7)用户界面采用图形化的人机界面使用户感到直观方便。
功能模糊决策系统具有以下功能:
(1)数据预处理转换为模糊数据;
(2)通过学习产生决策树;
(3)将决策树转化为规则集;
(4)利用规则进行分类决策。
决策树与模糊决策树的比较分析下面主要对决策树与模糊决策树的异同点进行比较。
(1)属性值及分类
在决策树中每一示例的属性值及分类都分别取互斥的属性值及分类中的一个,属性值及分类均是明确的,它们是示例空间上的集合,代表示例的属性及分类是否属于该属性值及要学习的概念。在模糊决策树中,属性值或分类反映了与人的思维、认识过程和理解中密切相关的不确定性(模糊性),所以将它们看成示例空间上的模糊集合,代表着示例的属性及分类隶属于该属性值及要学习的概念的程度。特别地情况,属性值为示例空间上的模糊数。模糊决策树的归纳学习与决策树归纳学习相比较,由于合理地处理了不确定信息、噪音数据等问题,从而有较强的分类能力及稳健性,使知识表示的方式更为自然,为决策者提供了丰富的决策信息。
(2)扩展结点
在决策树归纳学习中,因为属性值是互斥的,因此在对某一结点进行扩展(分枝)时,按扩展属性的属性值可将该结点上的例子集合S划分成v个不相交的子集合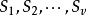 这些子集合满足
这些子集合满足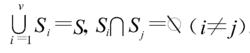
其中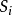 表示扩展属性的值
表示扩展属性的值 所对应的例子集合(i =1, 2, …v),v 是扩展属性的值的个数。在模糊决策树归纳学习中,因为属性值为示例空间上的模糊集合,根据模糊集合的特点,当对某一结点按其扩展属性所对应的属性值进行扩展(分枝)时, 构成S的一个模糊分割,即每一 为一模糊集合
所对应的例子集合(i =1, 2, …v),v 是扩展属性的值的个数。在模糊决策树归纳学习中,因为属性值为示例空间上的模糊集合,根据模糊集合的特点,当对某一结点按其扩展属性所对应的属性值进行扩展(分枝)时, 构成S的一个模糊分割,即每一 为一模糊集合
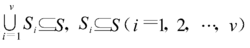
模糊决策树在知识的归纳过程中并入了认识上的不确定,使归纳出的知识在容许不精确或冲突的信息方面更稳健。
(3)匹配规则及推理
在决策树中,每一条从根到叶的路径对应一条规则,该规则的真实度为1,而且测试例子仅与一条规则相匹配,推理是基于清晰逻辑的;在模糊决策树中,每一条从根到叶的路径对应一条模糊规则,该规则的真实度小于等于1,而且测试例子可与多条模糊规则相匹配,并且带有一定的隶属度,推理是基于模糊逻辑的。由此可看出,模糊决策树与决策树相比较,模糊决策树更贴近于自然,更符合人类的思维。从决策的角度看,它提供的知识更为合理。
(4)叶结点及规则的真实度
在决策树中,叶结点仅包含一类的例子,相应的规则的真实度为1。在模糊决策树中,叶结点包含不止一类的例子,相应规则的真实度小于等于1,从而为构造模糊专家系统提供了更有效的途径。
(5)训练示例
对训练示例,决策树的测试精度为100%;而模糊决策树的测试精度非100%。
模糊ID3算法模糊ID3算法是决策树归纳学习算法ID3的一种推广。模糊ID3 算法亦采用分治策略,在决策树的递归构造过程中,在树的结点上利用属性的分割模糊熵作为扩展(分枝)属性的启发式函数,选择分割模糊熵最小的属性作为扩展属性,它具有分类速度快的优点,适合处理模糊数据,可应用于模糊专家系统等领域3。
步骤ID3算法模糊化后,主算法基本保持不变,但建树算法在样本数据提取、训练数据、生成决策树叶子结点数据都用模糊数据来表示。模糊ID3建树算法为:
(1)提取数据源的模糊样本,根据模糊数值计算各特征的互信息,得到精确数值;
(2)选择最大互信息特征A;
(3)将在A处取相同值例子分为相同样本子集,样本子集的类别结果为模糊的;
(4)对含有多个模糊样本子集递归调用建树算法;
(5)若子集仅含有限模糊类别的样例,对生成的决策树对应分枝作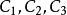 等标记,返回调用处。
等标记,返回调用处。
计算过程模糊ID3算法建树的计算过程为:
(1)计算信息熵H(U)。
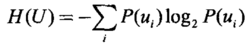
(2)计算条件熵H(U|V)。
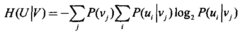
(3)计算互信息。
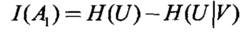
选择较大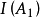 递归建立决策树。
递归建立决策树。

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国