

背景
随着计算机及其相关技术的发展,在最近几年出现了大量以数据流为信息承载模式的应用系统,这些数据流一般都具有实时性、连续性、顺序性以及数据量庞大等特点,使用传统的数据库管理系统已经不能满足数据流处理的要求。各种适应于不同应用的系统紧随其后不断涌现,目前主要的数据流管理系统(DSMS)项目有STREAM(Stanford),Aurora(Brandeis/Brown/MIT),Telegraph(Berkeley),Gigascope(AT&T), Niagara (OGI/Wisconsin ),Tribeca(Bellcore)。11
系统模型数据流管理系统所处理的数据流是一种实时连续的数据信息序列,而且在实际处理过程中,这种数据序列具有信息到达顺序不可控、单位时间数据到达量不均匀、数据量庞大等特点。这些特点要求DSMS 应当具有以下的功能:1
(1)在一定的时间内,对信息能够进行重组并处理;
(2)由于物理存储空间的限制和处理效率的要求,对数据流进行在线处理时,一般只扫描数据一遍;
(3)一般不采用阻塞方式处理数据流,以保证数据处理的效率;
(4)能对数据进行提炼,并采取随机和/或有选择地丢包等减负措施,保证在突发流量情况下系统的整体性能;
(5)对异常的数据有足够迅速(接近于实时)的反应能力。
图 1 描述了DSMS 的一般功能结构,用于支持长期运行,连续的、标准的、持久的查询。主要由3 部分组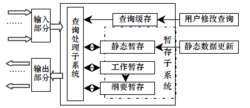 成:输入部分,处理部分和输出部分。输入部分主要对输入的数据流进行初步的过滤,并兼有应付突发流量的基本功能(譬如在系统没有足够资源处理突发数据流时进行负载脱落)。处理部分是整个系统的主干,由3 部分组成:(1)暂存子系统,数据分为3 部分暂存:静态暂存部分存储元数据(例如DSMS 各部分的物理位置等),允许用户自定义相关的设置;工作暂存部分存储当前处理的数据流,如果遇到突发流量而没有足够的物理存储空间, 可以对数据进行归纳, 将获得的纲要(Synposes)或摘要存储在纲要暂存中;(2)查询缓存,主要存储用户定义的查询条件,一般的DSMS 系统支持用户在线修改查询条件;(3)查询处理子系统,主要功能是从查询缓存中提取用户定义的查询,根据优化需求对其进行分组,并将其作用于从输入部分获得的数据流。查询处理子系统还具有自适应功能,能根据当前数据流量和查询条件调整系统查询策略。输出部分主要的功能是保证处理所得的结果(数据流或/和关系型数据项)能够平稳地输出,一般都包含临时存储的功能。
成:输入部分,处理部分和输出部分。输入部分主要对输入的数据流进行初步的过滤,并兼有应付突发流量的基本功能(譬如在系统没有足够资源处理突发数据流时进行负载脱落)。处理部分是整个系统的主干,由3 部分组成:(1)暂存子系统,数据分为3 部分暂存:静态暂存部分存储元数据(例如DSMS 各部分的物理位置等),允许用户自定义相关的设置;工作暂存部分存储当前处理的数据流,如果遇到突发流量而没有足够的物理存储空间, 可以对数据进行归纳, 将获得的纲要(Synposes)或摘要存储在纲要暂存中;(2)查询缓存,主要存储用户定义的查询条件,一般的DSMS 系统支持用户在线修改查询条件;(3)查询处理子系统,主要功能是从查询缓存中提取用户定义的查询,根据优化需求对其进行分组,并将其作用于从输入部分获得的数据流。查询处理子系统还具有自适应功能,能根据当前数据流量和查询条件调整系统查询策略。输出部分主要的功能是保证处理所得的结果(数据流或/和关系型数据项)能够平稳地输出,一般都包含临时存储的功能。
数据流预处理模型由于数据流只出现1 次并且具有一定顺序性的特点,一般在处理数据流时,DSMS 将数据流划分为若干数据单元,根据DSMS 处理这些数据单元所采用的不同模型将数据流单元分别存储到一系列顺序的元素列表。针对连续数据流的非阻塞方式处理,一般DSMS 实验系统都采用窗口技术。窗口是一种从不受限制的数据流转化为一系列可控的受限数据单元的机制。按现有数据流管理系统使用窗口技术处理数据流的方式,可将窗口机制分3 类。1
(1)采用基于顺序窗口机制的数据流都存在可以唯一标记流元素到达顺序的属性,现有系统一般都采用到达时间作为衡量标准。这些系统通过显性或隐性的方式以一定的时间间隔给到达的数据流单元打上时间戳(timestamps),根据时间戳从数据流中提取数据单元进行分析。C.Cranor, Y.Gao et al. [2]介绍的面向网络数据流监测的Gigascope 系统。L.Golab, M.T.Ozsu[1]把这种窗口机制称为基于物理分类的窗口机制。
(2)基于单元数量的机制将到达的数据流被看作由一系列元组(tuple)组成队列(例如在网络监测中将数据流中的每个包作为一个元组处理),应用数据流处理系统自定义的规则暂存到达的元组,并对其进行处理。Telegraph将到达的元组分类存储在数据状态模块(Data SteMs),与查询状态模块(Query SteMs)进行一系列相关操作获得结果并以数据流的形式输出。
(3)基于标记的机制:标记是确定连续流中一部分结束的记号,从而使系统可以将一条没有限制的流看成是若干受限流的组合。在具体应用中,标记被作为一个控制包嵌入到输入的数据流中,数据流操作单元通过读取标记获得操作和控制数据流的信息。使用标记技术的数据流处理项目主要包括Aurora,STREAM,Tribeca,Niagara,Hancock等。
在目前 DSMS 系统中,这几种窗口机制是一般都是结合使用的,已达到不同阶段采用相对更有效处理方式的目的,如STREAM 中就包含这3 种类型的窗口机制。
数据流查询语言在 DSMS 中,连续查询可以被分解为算子(operator)的集合,例如project,select,join 等,这些算子在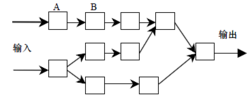 传统的DBMS 中也作了相关定义,其区别主要集中在DSMS 如何使算子能够在非阻塞的模式下运行,这个问题可以使用窗口技术解决,如图2。1
传统的DBMS 中也作了相关定义,其区别主要集中在DSMS 如何使算子能够在非阻塞的模式下运行,这个问题可以使用窗口技术解决,如图2。1
数据流查询操作的 整个过 程可以使用 单 向 无 环 图(DAG)来表示,其中每个点表示一个管道(pipelined)算子,有向的边表示连接两个算子的队列(例如,经过算子A处理的数据流通过缓冲写入队列AB 成为算子B 的输入流)。1
优化策略数据流处理过程中需要解决的问题很多,其中比较典型的有两个:突发流量不确定性和近乎实时处理的性能需求。需要采取必要的措施进行协调。1
进度安排进度安排是一种积极的优化策略,是影响系统的整体性能最关键的因素之一。在实施过程中,系统为达到各种性能指标的要求会发生冲突(例如较小的相应时间必然要求较大的内存),所以对实际系统而言,寻找各种指标的平衡至关重要。具体的DSMS 会根据数据流的特点和需达到的目的,以部分牺牲其它性能为代价,选取其中的一个或一部分性能作为主要衡量指标。1
负载脱落当突发流量超过系统的处理能力,如果不采取相应的措施,会导致整个系统的吞吐量和响应时间都恶化。负载脱落通过丢弃一定数量的数据,在部分牺牲准确性和完整性的条件下,保证系统的性能。负载脱落算法可以根据采用的处理方式分为以下两种:随机的负载脱落算法和基于语义的负载脱落算法。
随机负载脱落是指在发现数据输入超出系统处理能力时,通过按一定的比重随机丢弃部分元组保证系统的正常运行。基于语义的负载脱落,通过用户对流处理语义的理解,有选择地丢弃一部分元组,使元组损失对系统性能和输出结果的影响最小化。目前普遍采用的负载脱落算法一般是基于语义的。基于语义的负载脱落算法与系统的上下文有关,主要考虑的问题是:何时,何地以及如何进行。1
近似值计算当系统性能满足数据流处理的要求时,处理结果可以正常输出。但如果处理要求超出系统的处理能力时,如突发流量、处理数据流所需内存超出物理内存等,可能导致系统总体性能下降甚至出错。DSMS 采用计算近似值的方法,通过发现处理数据流的相似性,将其进行归类处理,在部分牺牲精确性的条件下获得处理时间的减少和存储空间上的节省。1
近似值计算是 DSMS 中重要的数据处理方式,所采用的算法根据具体方法的不同分为计数(Counting) 、哈希(Hashing)、抽样(Sampling)、概要(Sketches)、直方图(Histograms)和小波(Wavelets)等。1
未来研究方向虽然数据流管理系统在不同领域数据流处理中得到了广泛的应用,但是由于其在总体上尚处于起步阶段,而数据流处理本身需求有多种形式且复杂程度呈迅速上升趋势,因此数据流管理系统在许多方面有待提高,主要集中在以下:1
(1)数据流管理系统的统一接口问题
目前相关研究机构出于各自研究的需要,都自定义了一系列自己的DSMS 接口规范,而没有考虑不同DSMS 之间的互联和共享。由于所需处理问题的复杂化和各个研究机构之间协作的增加,和传统的DBMS 类似,定义统一访问接口势在必行。
(2)数据流处理优化策略
由于所需处理数据的量和数据处理的复杂程度增长的速度要远远超过硬件处理能力的增长速度,而且现有数据流处理优化策略还不能很好地满足相关要求,因此有必要进一步改进和发展流处理优化策略。首先针对进度安排,问题主要集中在响应时间和内存占用之间能否找到一个平衡点,并且平衡点是可变的,始终契合具体的应用需求;负载脱落算法主要考虑如何跟语义更紧密地结合,从而使其代价最小化;近似值计算目前主要发展方向是多种处理方法的结合使用,具体方法的选择应当较好地考虑其使用范围和具体应用。
(3)数据流管理系统如何在整体性能方面超过针对应用的专业工具
数据流管理系统相对于一般针对具体应用的专业工具主要的优点在于其适应能力和通用性,用户可以根据具体的需要通过定义不同的接口来获得不同的测试结果,但这是以牺牲一定的处理性能为代价的。如何通过技术的改进在整体性能方面超过一般专用的工具;或者通过为一般工具提供接口的方式和专用工具结合使用,以达到更高的处理能力和更好的处理效果,这是DSMS 发展所需解决的一个问题。
数据流管理系统在借鉴传统数据库的基础上提出了时间戳、窗口机制、连续查询、优化策略等方法,用于在线分析连续数据流。在现有DSMS 中这些技术得到了广泛的应用和发展,但是由于硬件性能增长速度要远远落后于数据流处理需求的增长速度,因此有必要在系统结构和优化算法等诸多方面促进DSMS 的发展。

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国