

简介
基本的模糊控制系统如图 1 所示,其中虚线框内为模糊控制器部分,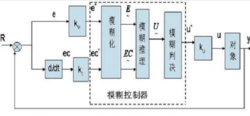 模糊控制器的输入信号要经过模糊化、模糊推理及模糊判决才得到输出控制信号。在模糊控制器的设计中,模糊化的目的是为后续的模糊推理运算做准备,所以在选择模糊化方法时,除了要考虑到各模糊化方法的特点外,还应考虑到与所采用模糊推理方法的匹配问题。下面介绍的模糊化方法中的精确输入量,假设均为经过量化后的在模糊集合论域上取值的精确量。
模糊控制器的输入信号要经过模糊化、模糊推理及模糊判决才得到输出控制信号。在模糊控制器的设计中,模糊化的目的是为后续的模糊推理运算做准备,所以在选择模糊化方法时,除了要考虑到各模糊化方法的特点外,还应考虑到与所采用模糊推理方法的匹配问题。下面介绍的模糊化方法中的精确输入量,假设均为经过量化后的在模糊集合论域上取值的精确量。
分档模糊集法分档模糊集法将模糊集合论域上的精确量分成若干档,每一档对应 一个模糊集合。
一个模糊集合。
例如当模糊语言值的隶属函数用表格形式表示时,如图2所示,模糊集合论域为离散整数域N={-6,-5,-4,-3,-2,-1,0,+1,+2,+3,+4,+5,+6} ,将该论域上的 13 个离散元素分成七档,每一档对应一个语言值。表中的七个语言值为 {PB, PM, PS, O, NS, NM, NB} 。
具体分档时,按隶属度最大的原则来进行,找出论域 N 上的元素 n* 与最大隶属度对应的语言值,该语言值所代表的模糊集合就是精确量 n* 的模糊化结果。例如图2中精确量 +6 模糊化为 PB;+5 对 PB的隶属度PB(+5) 为 0.8 ,对 PM的隶属度 PM(+5)为 0.7 ,PB(+5)> PM(+5) ,所以, +5 模糊化为 PB。这样 +5 和+6 归为一档,模糊化结果为模糊集合 PB。再如 n*=-3 时,因为NS()=NM()=0.7 ,所以 -3 的模糊化结果是 NS或者 NM。
当模糊语言值的隶属函数采用图形形式表示、论域为连续域时,也可做如上类似转换。
输入点隶属度取1法当模糊集合论域为离散整数域 N,其上的语言值的赋值表为表 1 时,若输入精确量 n*(n* ∈N ) 对各语言值有隶属度为 1 的情况,则模糊化处理与分档模糊集法相同。例如 n*=+6 时,它对 PB的隶属度为 1,则模糊化结果为 A*=PB,即:
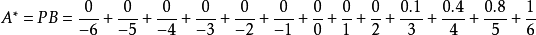
若输入精确量对各语言值没有隶属度为 1 的情况,则将该精确量 n* 处的隶属度取为 1,相邻两个整数点处的隶属度取为 0.5 。如 n*=+5 时,模糊化结果为:
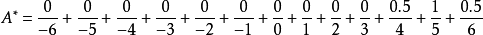
当模糊集合论域为连续域 X 时,精确输入量 X*(X* ∈X)模糊化后的模糊集合可取常用的等腰三角形。
隶属函数,如图 3所示,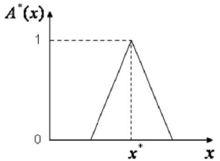
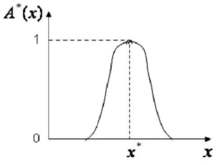 在 x* 处的隶属度值为 1。当测量数据存在随机噪声时, 常采用这种方法。这时等腰三角形的顶点与该随机数的均值相对应,三角形的底边宽度是该随机数的标准差的两倍。当然三角形隶属函数并不是唯一的选择,还可选用钟形 ( 如图4所示 ) 等其它隶属函数。
在 x* 处的隶属度值为 1。当测量数据存在随机噪声时, 常采用这种方法。这时等腰三角形的顶点与该随机数的均值相对应,三角形的底边宽度是该随机数的标准差的两倍。当然三角形隶属函数并不是唯一的选择,还可选用钟形 ( 如图4所示 ) 等其它隶属函数。
单点形模糊集合法将模糊集合论域 X 上的精确量 x* 模糊化为单点形模糊集合。单点形模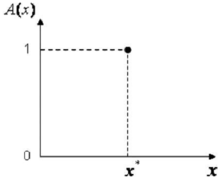 糊集合是指该模糊集合的隶属度只在 x* 处为 1,而在除 x* 以外的其余各点处都为 0 。
糊集合是指该模糊集合的隶属度只在 x* 处为 1,而在除 x* 以外的其余各点处都为 0 。
设 A 为 x* 模糊化后对应的模糊集合, x∈X,则:
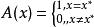
其隶属函数图形如图 5 所示。
这种模糊化方法从概念上看,已把一个精确量转换成了模糊量,但是在本质上该模糊量并没有具备模糊性,表达的仍然是确定性的信息。不过在模糊控制应用中,这种方法由于使人感到自然和易于实现而得到了广泛应用。当测量数据准确时,常常采用此法。
隶属度值法隶属度值法是将精确输入量对各语言值的隶属度值作为模糊化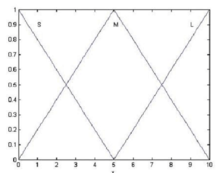 结果。因语言值的隶属函数可用离散域上的表格形式表示 ( 如图2),也可用连续域上的解析表达式表示,所以这种模糊化方法相当于一个对应的查表或是函数计算过程。
结果。因语言值的隶属函数可用离散域上的表格形式表示 ( 如图2),也可用连续域上的解析表达式表示,所以这种模糊化方法相当于一个对应的查表或是函数计算过程。
例如在图2 中,精确量 -2 对 NS的隶属度值为 1,对 NM的隶属度值为 0.2 ,而对其它语言值的隶属度为 0,求出这些隶属度值即完成了对精确输入量的模糊化。
对于连续域情况,假设某语音变量的语言值 {S, M, L} 采用如下三角形隶属函数:
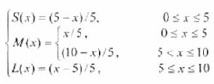
隶属函数图形如图6所示。当输入精确量为 x*=6 时,M(x*)=0.8 ,L(x*)=0.2 。则用这两个隶属度值作为 x* 的模糊化结果,进行下一步的模糊推理。
隶属度值模糊化方法主要和 Mamdani 直接模糊推理法或强度转移模糊推理法配套使用, 它的模糊化结果是精确的数值而不是模糊集合,这正是上述两种模糊推理法的推理前提要求。1

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国