

背景
近年来,互联网的普及大大促进了信息检索技术的发展和应用,正如上文提到的一批搜索引擎产品已经产生,为用户提供了很好的快速信息获取和网络信息导航工具,目前最著名的搜索引擎包括Google、AltaVista等,国内百度的中文搜索引擎也取得了很好的成绩。
目前搜索引擎面临两个主要挑战:一是检索的质量仍然需要提高。常常检索的是大量的无用的结果,真正有用的结果却被淹没在其中不容易发现。搜索引擎的索引和以前相比已经有了极大的增长,一般检索时都会返回大量的结果。但是人们查看和选择结果的能力与耐心没有得到相应的提高,通常还是只会注意最前面的部分。因此,搜索引擎的“精度”,尤其是检索结果排在前面的部分对于用户的有用性。是非常重要的,有时候相对于查全率来说显得更加突出。
基本概念在文献检索中,模糊匹配是指无论词的位置怎样,只要出现该词即可。精确匹配是指只有整个字段与检索词相同才匹配。精确匹配是指将输入的检索词当固定词组进行检索,而模糊匹配则会自动拆分检索词为单元概念,并进行逻辑与运算。
精确匹配检索设计精确匹配模型在“布尔模型”、“向量空间模型”和“概率模型”基础之上,下面是一种信息检索精确匹配模型。采用国标汉字字符集GBK/2:GB2312中包含的6763个汉字作为文档特征项1。
①文档特征项可以表示为向量形式: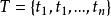 ,其中n=6763,
,其中n=6763,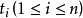 代表国标汉字字符集GBK/2:GB2312中包含的6763个汉字中的某个特定汉字。汉字编码是用双字节形式,编码分为9个区,高字节分别为:B0~B7,B8~BF,C0~C7,C8~CF,D0~D7,D8~DF,E0~E7,E8~EF,F0~F7;相应的低字节编码均为:A1~FE。
代表国标汉字字符集GBK/2:GB2312中包含的6763个汉字中的某个特定汉字。汉字编码是用双字节形式,编码分为9个区,高字节分别为:B0~B7,B8~BF,C0~C7,C8~CF,D0~D7,D8~DF,E0~E7,E8~EF,F0~F7;相应的低字节编码均为:A1~FE。
②假设被检索文档为D。其向量表示形式为: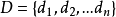 其中n=6763,
其中n=6763,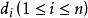 。在集合{0,1}中取值。如果特征分项
。在集合{0,1}中取值。如果特征分项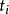 在文档D中出现,即 ∈D,则相应
在文档D中出现,即 ∈D,则相应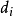 =1;如果特征分项 在文档D中没有出现,即 不属于D,则相应 =0。
=1;如果特征分项 在文档D中没有出现,即 不属于D,则相应 =0。
⑧用户查询可表示为Q,其向量形式为: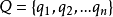 。这里的m值理论上不受限制,但从实际出发考虑m应该小于等于n,为了方便两个向量的运算,在此取m=n(差项用数字0填补)。同样
。这里的m值理论上不受限制,但从实际出发考虑m应该小于等于n,为了方便两个向量的运算,在此取m=n(差项用数字0填补)。同样 在集合(0,1}中取值。如果特征分项 在文档Q中出现,即 ∈Q,则相应 =1;如果特征分项 在文档Q中没有出现,即 不属于Q,则相应 =0。
在集合(0,1}中取值。如果特征分项 在文档Q中出现,即 ∈Q,则相应 =1;如果特征分项 在文档Q中没有出现,即 不属于Q,则相应 =0。
④将向量D、Q做数量积运算,设向量D、Q的数量积为R。
i)如果R=0,则说明用户检索条件在被检索的文档中不存在。
ii)如果R≠0,下面继续判断。计算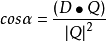 。
。
ii)如果0

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国