

相关度(Relevancy)是指两个事物间存在相互联系的百分比。在信息检索领域,相关度理论一直是研究的焦点和热点。Mizzaro综合了前人对相关度的不同定义和分类,提出了四维度的相关度研究框架:Information Need,Components,Time,Information Resource,它认为任何一种相关度是上述四维空间的某个点。相关度加权是指事物之间存在的相互关系加以权重。例如在信息检索中对某个词在整个信息中的影响加以权重。相关度加权有着广泛的应用,如信息检索,数据挖掘、人工智能等领域。
相关度相关度(Relevancy)是指两个事物间存在相互联系的百分比。关于相关度的正式研究开始于二十世纪,研究后来被称为文献计量学。在20世纪30年代和40年代,斯科特布拉德福德(SC Bradford)使用“相关度”一词来表征与一个主题有关的文章。在20世纪50年代,第一批信息检索系统出现,研究人员指出不相关的文章在检索出现是一个重要的问题。1958年,卑诗省维克里奇(B. C. Vickery)在国际科学信息会议的一次演讲中提出了相关度的清楚概念。1
在信息检索领域,相关度理论一直是研究的焦点和热点。Mizzaro综合了前人对相关度的不同定义和分类,提出了四维度的相关度研究框架:InformationNeed,Components,Time,Information Resource,它认为任何一种相关度是上述四维空间的某个点。而Steve Draper对四维度的相关度框架提出了质疑和讨论,认为信息需求是没有先后的,而且IR系统需要的是确定的单一的相关度判定结果,多维度的相关度表示和判定反而不利于IR服务。Borlund对相关度概念作出总结,并认为情境相关是未来相关度发展的主流趋势。HjorlandNl批评了系统和用户相关的观点,强调和维护了Saracevic提出的主题知识相关(the Subject Knowledge View),并从社会学的观点出发理解和阐释相关度。2
应用基于查询词出现的相关度改进
对检索效果的改进,一直是信息检索领域重要的研究内容。所谓的查询词出现信息,指的是查询中的某个词是否在文档中出现。在一个查询中,一个查询词是否在文档中出现,会影响该文档的相关性,这个性质已经在已有的检索模型中得到应用。从另外一个角度,通过查询词出现信息计算相应的权值,将该权值应用到已有的检索模型基础上。对于权值的计算,这里采用了两种改进方法,即系数加权方法和线性加权方法。
一个查询可能有多个查询词,其中的每个查询词是否在文档中出现,会影响相关度。在BM25 模型或者其他模型的打分过程中,都已经考虑了文档中的词频:在一篇文档中,查询词的词频越高,对相关度的贡献越高;如果查询词没有出现(词频为 0),会适当降低相关度。然而本文对于查询词出现的贡献,则是从另一个角度考虑。让我们考虑如下的情形:对于一个查询 t1 t2 t3,通过 BM25 模型的打分,两篇文档的分数一样高(或者很接近)。但是第一篇文档只出现了 t1 和 t2,而第二篇文档 t1 t2 t3 都出现,那么我们直观上感觉第二篇文档更好一些。基于这样的启发式方法,我们定义了一个词出现的影响权重 weightocc,对于这个权重,尝试了两种加权方法,对相关度分数进行改进。
系数加权
在这个方法中,我们将词出现的权重作为系数,乘到原始分数上面,得到改进后的分数,如下所述
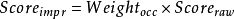
线性加权
在线性加权方法中,词出现的权重和原始分数线性加权,得到最终的改进分数。是可调节的参数。
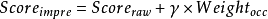
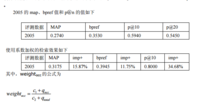 这里通过引入词出现权重,对检索相关度的改进。通过调整参数,在GOV2数据2005年的评测集上取得了比较好的检索效果。如图3
这里通过引入词出现权重,对检索相关度的改进。通过调整参数,在GOV2数据2005年的评测集上取得了比较好的检索效果。如图3

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国