

随着Internet的蓬勃发展,网络业务量的不断增长,人们对网络的服务质量 (QOS) 的要求越来越高。现有的Internet采用的是传统的“尽力而为”的服务机制,这种机制的优势是设计简单,但是存在一个主要的问题就是会产生拥塞崩溃现象,使得链路利用率大大下降。所以因特网必须提供拥塞控制机制。而传统的TCP端到端的拥塞控制并不能避免拥塞的发生。所以网络本身的节点就必须自主地参与到拥塞控制中。依靠网络结点主动感知缓冲区的占有率来管理缓存。从而有效地避免拥塞的发生。队列管理是指在网络发生拥塞时。通过丢包来管理队列长度。调节缓冲区的占有率。对队列长度进行管理将直接影响到网络结点的拥塞控制能力和网络的QOS。而目前队列管理机制主要有两大类:被动队列调度机制 (PQM)与主动队列调度机制(AQM)。 PQM在因特网上得到了广泛的应用,但是存在两个重要的问题:死锁和满队列。由于因特网的数据具有突发性,在满队列的状态下导致了 “TCP全局同步”现象,导致了整个链路的利用率在下降。为此IETF又提出了AQM,AQM方法是根据队列长度的变化对队列满行提前丢包,从而预先告之网络拥塞,使得发送节点在链路缓存溢出前作出反映,有效减少和避免拥塞的发生。 1
AQM 研究现状自1998年IETF的RFC2309建议路由器使用AQM机制之后,AQM 成为计算机网络领域的热点之一。在各种文献中共提出了几十种算法,主要有以下几种算法:RED 算法及其变种算法;基于控制理论的主动队列管理机制等。
队尾丢弃算法(Tail Drop)队尾丢弃算法(Tail Drop)又称FIFO即先进先出,是一种被动的队列管理机制, 也是当前网络上采用的重要的队列管理方法。其基本的思想就是当网络结点缓存队列长度达到最大值时,通过丢弃分组来指示拥塞,先到达路由器的分组首先被传输。
数据包到达路由器后,需要在不同的输出端口缓冲区中进行排队;这样当网络发生拥塞的时候,所有新到达又来不及处理的数据包都会保存在缓冲区中,当系统空闲时再来处理这些保存起来的数据包。由于网络结点的缓存有限,如果分组到达时缓存已满,那么网络就丢弃该分组。一旦发生丢包,发送端立即被告知网络发生拥塞,从而调 整发送速率。这种队列管理机制目前仍然是因特网上使用最为广泛的分组排队、丢弃的方式。但是它将网络发生拥塞的责任全部都推给了网络边缘。所以TCP假设网络中的节点( 如路由器)对拥塞起不了任何作用,而由协议本身独立承担检测和响应拥塞的全部责任。这种方式最大的优点是实现很简单;缺点是容易造成队列死锁,进而导致TCP全局同步:当缓冲区被填满后,所有新到达的数据包都会被丢弃,所有发送方会同时降低发送速率;当拥塞消除后,所有发送方又会同时增大发送速率,这样就导致了所有发送方发送速率同步化。同时缓冲区很容易被填满, 无法容纳突发的数据流,降低了网络的利用率。
主动队列管理算法的分类针对现有的 AQM 算法,从它们的设计原理出发,可以归为如下3类:
基于(平均)队列长度的 AQMs这类基于队列长度的 AQM 算法在较轻网络负载下能稳定队列长度在某个范围内,但在特定的网络环境中依然会造成多个TCP的同步,造成队列震荡、吞吐量降低和时延抖动加剧。RED、ARED、CHOKe和 PI都属于这一类算法。
基于网络负载的 AQMs这类算法通过测量业务流量的输入速率或根据分组的丢失情况及链路使用历史情况来衡量拥塞的程度。这类基于速率的 AQM 算法提高了算法的响应时间,获得了较高的吞吐量,但由于没有对队列长度的显示控制,使得算法不能有效地稳定队列长度,导致时延增大。BLUE]和AVQ属于这一 类算法。 2
同时基于队列长度和网络负载的 AQMs这类算法的稳定性获得了很大的提高,稳定队列长度和端到端时延的能力也较强,但算法的瞬时响应性能以及在实际网络环境中的稳定性还有待加强。REM属于这一类算法。2
理想 AQM 算法的品质因为RED在稳定性和公平性方面存在问题,目前大多数的AQM 研究格外重视这两方面的问题,但一个真正可 以实践的路由器队列管理算法需要同时满足多方面的要求,技术指标固然重要,但其他因素也需要给予一定的考虑。综合各个方面,一个理想的 AQM 算法需要同时具备以下品质。3
有效性AQM 的技术目标可以概括为:在较高的链路利用率和较低的分组排队延时之间取得一个恰如其分的平衡。较小的队列长度允许路由器有条件在不丢弃分组的前提下最大限度的吸纳突发性业务流。在正常情形下,分组经历的 排队时延也会小许多,这对实时性的交互式应用尤为重要。当然,片面追求小队长,空队列概率加大,导致链路利用率降低也是不期望的。最有效的方法是无论网络状态如何,负载如何变化,始终将队列保持在一个较小的恒定值附近。从控制理论的角度分析,AQM的技术目标是需要实现一个调节系统,因此在评价算法有效性时,收敛时间自然是一个不可忽视的指标。连接的不断建立与拆除使得网络状态瞬息万变,算法必须具有很好的响应性才能充分适应快速变化的网络环境。3
鲁棒性AQM算法的鲁棒性包括两个方面。一是稳定性,即AQM算法自身必须稳定,不能像RED和 AVQ那样可能导致队列振荡。二是抗扰性。AQM 算法应该有能力抵抗非响应性业务(如UDP)和短时间突发业务(如HTPP或Telnet) 等扰动或噪声的干扰。3
可扩展性Internet 的快速发展表现在许多方面:用户数急剧增加,带宽迅猛提升,局域网和广域网规模不断扩大,
理想的AQM 算法必须在各个维度上具有可扩展性。不仅能工作在平均往返时延(RTT, Round Trip Time)为几十毫秒的LAN 或WAN 中, 而且要能稳定工作于有数百毫秒, 甚至秒数量级RTT的WAN 环境下; 既可以支持带宽为数兆比特的专用线路,也可以支持吉比特的光通路;在用户较少的接入网与连接密集的核心网中都可以有效工作,不会因为需要维护单个流的状态信息而影响算法的性能和实现的复杂度。3
为了提高网络性能,Internet 工程任务组(IETF)推荐在路由器中使用活动队列管理算法 RED,该算法的基本思想是通过监控路由器输出端口队列的平均长度来探测拥塞,一旦发现接近拥塞,就随机地选择连接来通知拥塞,使它们在队列溢出导致丢包之前减小发送窗口,降低数据发送速度,从而缓解网络拥塞。算法具体描述如下:数据包到达路由器后,需要在不同的输出端口缓冲区中进行排队,每一个输出端口维护一个队列;当有新的数据包到达时,采用指数加权滑动平均的方法计算 平均队列长度avg(这个平均是指对时间的平均),并把 avg 与 两个预先设定的门限(最小门限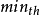 和最大门限
和最大门限 )相比较,若平均队列长度 avg 小于
)相比较,若平均队列长度 avg 小于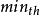 则不丢弃分组;若 avg 大于或等于
则不丢弃分组;若 avg 大于或等于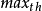 则丢弃所有分组;若 avg大于或等于
则丢弃所有分组;若 avg大于或等于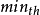 而小于
而小于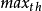 ,则根据平均队列长度 avg 计算概率
,则根据平均队列长度 avg 计算概率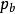 ,以概率
,以概率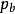 丢弃 到达的分组。4
丢弃 到达的分组。4
与上面队尾丢弃算法相比,RED 算法在拥塞发生之前通知发送方调整速率,能够有效地降低丢包率;RED 随机通知发送方而不是通知所有发送方,能够有效地消除全局同步;另 外,RED 还可以通过保持较短的队列长度来容纳突发的数据流。4
虽然 RED 能够有效避免拥塞,但是该算法仍然存在以下主要缺陷:
公平性问题
对于不响应拥塞通知的连接,RED 算法无法有效处理,因此这样的连接经常会挤占大量的网络带宽,导致了各种连接不公平地共享带宽。
参数设置问题
RED 算法对参数设置很敏感, 两个阈值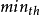 、
、 和最大丢包概率
和最大丢包概率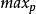 的细微变化经常会对网络性能造成很大影响,如何根据具体业务环境选择最合适的参数是RED存在的一个重要问题。另外,一组参数可能会获得 较高的吞吐量,但是可能也会造成较高的丢包率和较长的时间延迟。如何配置参数,使得算法在吞吐量、时间延迟和丢包率等各方面均获得较好的性能也有待解决。
的细微变化经常会对网络性能造成很大影响,如何根据具体业务环境选择最合适的参数是RED存在的一个重要问题。另外,一组参数可能会获得 较高的吞吐量,但是可能也会造成较高的丢包率和较长的时间延迟。如何配置参数,使得算法在吞吐量、时间延迟和丢包率等各方面均获得较好的性能也有待解决。
网络性能问题
RED 算法控制的平均队列长度经常会随着连接数目的增加而不断增大,造成传输时延抖动,引起网络性能不稳定。 4
针对 RED 静态参数配置的局限性,Wu-chang Feng等提出了自配置 RED、Sally Floyd 提出了自适应 RED(ARED)。James A采用线性系统理论分析了RED 模型,指出 RED 在网络条件大范围变化的情况下,不能稳定队列长度的原因在于没有提出明确的控制目标-目标队列长度,提出了动态RED(DRED)算法,根据队列长度与目标值的误差调节丢弃率, 从而将队列长度控制在目标值附近。 此外,许多学者对 RED 在设计时没有考虑到的细节问题进行了补充。例如,RED 在计算报文丢弃概率时没有考虑报文大小对流的吞吐量和丢弃率的影响,导致 RED 对 MTU比较大的连接丢弃率较高。如果用报文长度与MTU的比值对 RED 的丢弃概率进行调节,能够保证不同流之间在吞吐量和 丢弃率方面的“公平性” 。 虽然 RED 是为了改善尽力服务网络的拥塞控制而提出来的, 但是 RED 及其改进算法还被广泛应用于区分服务体系结构中。David D. Clark 等人提出了区分服务体系结构中的 RED 改进算法 RIO(RED with In and Out),在网络边缘将报文标记为in或 out,对两类流量采用不同的 RED 参数和丢弃概率,以区分它们的优先级。 5
FREDFRED(Flow Random Early Drop)是最早提出来的基于RED的近似公平分配算法。其基本的思想是通过考察某个流的当前队列缓存占用量来决定该流的分组被丢弃的概率。所谓流的当前队列缓存占用量是指在当前的队列缓存中属于某个流的分组的个数。FRED最大的特点是通过在路由器维持活动流的状态信息。即维持活动流的当前队列缓存占用量来获得一定的公平性。即针对不同的流计算不同的丢弃概率。相对于RED来说,在FRED中通过维持活动流的状态信息,在发生拥塞时,一方面保护一些“小”流在发生轻度拥塞时,它们的分组也不会被丢弃;另一方面,限制某些流占用过多的带宽"。但是当不同的流的队列缓存占用量介于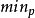 和
和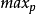 之间时,对于这些不同流的分组的丢弃概率的计算与RED中是一样的。这体现出一些随意性和不公平性。2
之间时,对于这些不同流的分组的丢弃概率的计算与RED中是一样的。这体现出一些随意性和不公平性。2
另外FRED最大的问题在于它要求在路由器维持活动流的状态信息。这需要占用路由器的大量缓存空间和处理时间。随着通过路由器的流的数目的增多,会给路由器带来沉重的负担。 因此FRED算法的可扩展性较差。2
基于控制理论的主动队列管理机制通常 RED 的改进方法在增强 RED 性能的同时,增加了算法的复杂度。不论是对 RED 参数设置的研究还是在 RED 基础上的改进最终都不能得到令人满意的效果,学术界开始摆脱 RED 结构框架的束缚,寻找新的简单、鲁棒的AQM 控制器。 随着对TCP协议运行机制认识的深入和计算机网络建模技术的发展,将控制理论应用于主动队列管理机制的设计成为可能,并且已经成为目前研究的热点。2000 年,Vishal Misra 等建立了 TCP 与队列变化的非线性微分方程模型。2001 年, C.V.hollot 采用小信号线性化方法将该模型线性化,并且导出了线性模型的传递函数,在此基础上分析了 RED 的参数设置并设计了比例积分(PI)控制器。基于控制理论设计主动队列管理机制具有许多优越性: 5
(1)设计方法更加科学,参数配置变得容易。控制理论是在系统数学模型的基础上建立起来的完善的理论体系,可以根据系统的稳态和动态性能要求选择合适的控制器,根据系统的稳定性、准确性、快速性、鲁棒性等要求决定控制器的参数。
(2)算法的性能对网络条件的敏感性降低,在控制器的设 计阶段就已经将系统的稳态精度、响应速度、稳定裕度、抗干扰能力等作为设计目标。
(3)大部分基于控制理论设计的 AQM 机制的复杂程度与 RED 相当,实现简单,适用于高速网络。特别是从经典控制理论推导出的控制器,其报文丢弃概率通常是瞬时队列长度的线性函数。
(4)具有明确的控制目标,消除了队列长度与负载的耦合,减小了队列振荡。 5
应用控制理论设计主动队列管理机制是目前学术界研究的热点。许多常用的控制方法被应用到 AQM 设计中来,例 如比例控制器(P)、比例积分控制器(PI)、比例积分微分控制器(PID)、比例微分控制器(PD)等。此外,许多先进控制理论也被用于 AQM 机制的设计,例如鲁棒控制、模糊控制、基于状态反馈的现代控制、神经网络控制等,这些控制器的性能有待进一步的分析和证明。5

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国