

简介
参数估计(parameter estimation)是根据从总体中抽取的样本估计总体分布中包含的未知参数的方法。人们常常需要根据手中的数据,分析或推断数据反映的本质规律。即根据样本数据如何选择统计量去推断总体的分布或数字特征等。统计推断是数理统计研究的核心问题。所谓统计推断是指根据样本对总体分布或分布的数字特征等作出合理的推断。它是统计推断的一种基本形式,是数理统计学的一个重要分支,分为点估计和区间估计两部分。1
在已知系统模型结构时,用系统的输入和输出数据计算系统模型参数的过程。18世纪末德国数学家C.F.高斯首先提出参数估计的方法,他用最小二乘法计算天体运行的轨道。20世纪60年代,随着电子计算机的普及,参数估计有了飞速的发展。参数估计有多种方法,有矩估计、极大似然法、一致最小方差无偏估计、最小风险估计、同变估计、最小二乘法、贝叶斯估计、极大验后法、最小风险法和极小化极大熵法等。最基本的方法是最小二乘法和极大似然法。
标准特点(1)无偏性
无偏性是指估计量抽样分布的数学期望等于总体参数的真值。无偏性的含义是,估计量是一随机变量,对于样本的每一次实现,由估计量算出的估计值有时可能偏高,有时可能偏低,但这些估计值平均起来等于总体参数的真值。在平均意义下,无偏性表示没有系统误差。
(2)一致性
有效性是指估计量与总体参数的离散程度。如果两个估计量都是无偏的,那么离散程度较小的估计量相对而言是较为有效的。离散程度是用方差度量的,因此在无偏估计量中,方差愈小愈有效。
(3)有效性
一致性,又称相合性,是指随着样本容量的增大,估计量愈来愈接近总体参数的真值2。
性质当估计值的数学期望等于参数真值时,参数估计就是无偏估计。当估计值是数据的线性函数时,参数估计就是线性估计。当估计值的均方差最小时,参数估计为一致最小均方误差估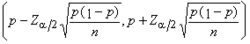 计。若线性估计又是一致最小均方误差估计,则称为最优线性无偏估计。如果无偏估计值的方差达到克拉默-尧不等式的下界,则称为有效估计值。若 ,则称 为一致性估计值。在一定条件下,最小二乘估计是最优线性无偏估计,它的估计值是有效估计,而且是一致性估计。极大似然估计在一定条件下渐近有效,而且是一致的。
计。若线性估计又是一致最小均方误差估计,则称为最优线性无偏估计。如果无偏估计值的方差达到克拉默-尧不等式的下界,则称为有效估计值。若 ,则称 为一致性估计值。在一定条件下,最小二乘估计是最优线性无偏估计,它的估计值是有效估计,而且是一致性估计。极大似然估计在一定条件下渐近有效,而且是一致的。
寻求最小二乘估计和极大似然估计的常用方法是将准则对参数θ求导数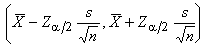 ,计算梯度,因而要使用最优化的方法:梯度法、变尺度法、单纯形搜索法、牛顿-拉夫森法等2。
,计算梯度,因而要使用最优化的方法:梯度法、变尺度法、单纯形搜索法、牛顿-拉夫森法等2。
参数估计的分类参数估计常用的有点估计(point estimation)、区间估计(interval estimation)和递推参数估计三种。
点估计点估计是依据样本估计总体分布中所含的未知参数或未知参数的函数。通常它们是总体的某个特征值,如数学期望、方差和相关系数等。点估计问题就是要构造一个只依赖于样本的量,作为未知参数或未知参数的函数的估计值。例如,设一批产品的废品率为θ。为估计θ,从这批产品中随机地抽出n个作检查,以X记其中的废品个数,用X/n估计θ,这就是一个点估计。
构造点估计常用的方法是:
①矩估计法。用样本矩估计总体矩,从而得到总体分布中参数的一种估计。它的思想实质是用样本的经验分布和样本矩去替换总体的分布和总体矩。矩估计法的优点是简单易行, 并不需要事先知道总体是什么分布。缺点是,当总体类型已知时,没有充分利用分布提供的信息。一般场合下,矩估计量不具有唯一性。
②最大似然估计法。于1912年由英国统计学家R.A.费希尔提出,利用样本分布密度构造似然函数来求出参数的最大似然估计。
③最小二乘法。主要用于线性统计模型中的参数估计问题。
④贝叶斯估计法。基于贝叶斯学派(见贝叶斯统计)的观点而提出的估计法。可以用来估计未知参数的估计量很多,于是产生了怎样选择一个优良估计量的问题。首先必须对优良性定出准则,这种准则是不唯一的,可以根据实际问题和理论研究的方便进行选择。优良性准则有两大类:一类是小样本准则,即在样本大小固定时的优良性准则;另一类是大样本准则,即在样本大小趋于无穷时的优良性准则。最重要的小样本优良性准则是无偏性及与此相关的一致最小方差无偏估计,其次有容许性准则,最小化最大准则,最优同变准则等。大样本优良性准则有相合性、最优渐近正态估计和渐近有效估计等2。
区间估计区间估计是依据抽取的样本,根据一定的正确度与精确度的要求,构造出适当的区间,作为总体分布的未知参数或参数的函数的真值所在范围的估计。例如人们常说的有百分之多少的把握保证某值在某个范围内,即是区间估计的最简单的应用。1934年统计学家 J.奈曼创立了一种严格的区间估计理论。求置信区间常用的三种方法:
①利用已知的抽样分布。例如,设x1,x2,…,xn为正态总体N(μ,σ2)中抽出的样本,要作μ的区间估计,则服从自由度为n-1的t分布。指定α>0,找这个分布的上α/2分位数tα/2(n-1),则有即由此得到 μ 的一个置信系数为 1-α 的置信区间。
②利用区间估计与假设检验的联系。设要作θ的置信系数为1-α 的区间估计,对于任意的θ0,考虑原假设为 H:θ=θ0,备择假设为 K:θ≠θ0。设有一水平为α 的检验,它当样本X属于集合A( θ0)时接受H。若集合{θ0∶X∈A(θ0)}是一个区间,则它就是θ的一个置信区间,其置信系数为1-α。就上例而言,对假设H:μ=μ0的检验常用t检验:当时接受μ=μ0,集合即为区间。这正是前面定出的μ的置信区间。若要求θ的置信下限(或上限),则取原假设为θ≤θ0(或θ≥θ0),备择假设为θ>;θ0(或θ
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国