

预备知识随机现象
在自然界和人类社会中存在着两类现象。
第一类,在一定条件下某种现象必定发生或必定不会发生,这类现象称为确定性现象。例如,自由落体在经过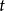 秒钟后,落下的距离
秒钟后,落下的距离 必定是
必定是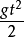 ;在标准大气压下,水到摄氏600沸腾.第一种是必然会发生的,称为必然事件,记作
;在标准大气压下,水到摄氏600沸腾.第一种是必然会发生的,称为必然事件,记作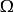 ;第二种是必然不会发生的,称为不可能事件,记作
;第二种是必然不会发生的,称为不可能事件,记作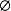 。1
。1
另一类,在一定条件下,某种现象可能发生也可能不发生,称这类现象为随机现象。例如,杭州明年正月初一下雪;播种1000颗种子,有850颗发芽;发射一枚炮弹,弹着点与目标之问的距离为150米。1
对随机现象,在基本相同的条件下,重复进行试验或观察,可能出现各种不同的结果;试验共有哪些结果事前是知道的,但每次试验出现哪一种结果却是无法预见的、这种试验称为随机试验(random experiment)。每次试验不能预测其结果,这反映随机试验结果的出现具有偶然性;但如果进行大量重复试验,所出现结果又具有某种规律性一统计规律性。例如,各次发射炮弹,弹着点与目标之间的距离可能各不相同,但如果射手技术较好,多次发射中距离近的必定是多数。1
随机试验的可能结果称为随机事件(random event),简称事件。一次试验中,某事件 A 可能发生,也可能不发生,发生的可能性有大有小。这一可能性大小的数量指标就是我们所要研究的事件的概率。1
概率的统计定义在相同条件下重复做N次试验,各次试验互不影响。考察事件A出现的次数(频数)n,称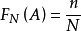 为在N 次试验中出现的频率(frequency)。频率一般与试验次数 N 有关,并且在 N 固定时,做若干组 N 次试验,各组频率一般也不相同;但当 N 很大时,频率却呈现某种稳定性,即
为在N 次试验中出现的频率(frequency)。频率一般与试验次数 N 有关,并且在 N 固定时,做若干组 N 次试验,各组频率一般也不相同;但当 N 很大时,频率却呈现某种稳定性,即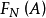 在某常数附近摆动,且当 N 无限增大时,频率会“趋向”这个常数。这种规律称为随机现象的统计规律。很自然地,频率所稳定到的那个常数可以表示事件 A 在一次试验中发生的可能性的大小,称作概率(probability),记为
在某常数附近摆动,且当 N 无限增大时,频率会“趋向”这个常数。这种规律称为随机现象的统计规律。很自然地,频率所稳定到的那个常数可以表示事件 A 在一次试验中发生的可能性的大小,称作概率(probability),记为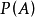 ,概率的这种定义称为统计定义。
,概率的这种定义称为统计定义。
虽然我们并不能由概率的统计定义确切地定出一个事件的概率,但是它提供了一种估计概率的方法,频率与概率的关系就像物体长度的测量值与该长度之间的关系。物体的长度是客观存在的,是该物体的固有属性。测量值是它的某种程度的近似值。同样,随机事件发生的可能性大小概率是随机事件的客观属性,多次随机试验所得的频率则是它的某种程度的近似值。1
必须注意,应用概率的统计定义时,各次试验是在基本相同的条件下独立进行的,而且次数要足够多。1
定义随机试验的每一个基本结果称为样本点(sample point),通常记作 ω 。样本点的全体称为样本空间(sample space),通常记作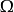 。1
。1
样本点和样本空问是概率论中的两个基本概念。随着对所讨论问题的兴趣不同,同一随机试验可以有不同的样本空间。讨论问题前必须先确定样本空间。1
**例1:**口袋中装有10个球:3个红球,3个白球和4个黑球。
任取1球,样本空间可以取为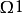 ={取得一个红球,取得一个白球,取得一个黑球}。
={取得一个红球,取得一个白球,取得一个黑球}。
若把球编号,红球编为1~3号,白球和黑球分别为4~6和7~10号;则每取一球,必定是且只能是这些球号中的一个,故也可取样本空间为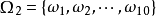 ,其中
,其中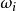 ={取得第
={取得第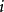 号球),
号球), 。
。
如果每次共取两个球.则每个样本点可以用所取得的两个球号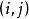 来表示,样本空间可以是{(1,2),(1,3),….(1,10),(2,3),…,(2,10),...,(9,10)},共有
来表示,样本空间可以是{(1,2),(1,3),….(1,10),(2,3),…,(2,10),...,(9,10)},共有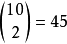 个样本点,这是二维的样本空间。1
个样本点,这是二维的样本空间。1
**例2:**考察单位时间内落在地球上某一区域的宇宙射线数,这可能是0,也可能是1,是2,…,很难确定一个上界。于是可以取样本空间为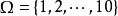 。它包含无限多个样本点,但可按一定的顺序排列起来(称为无限可列个)。1
。它包含无限多个样本点,但可按一定的顺序排列起来(称为无限可列个)。1
**例3:**抛掷一枚骰子,虽然无法预知其结果如何,但总不外乎“出现1点”,“出现2点”,...,“出现6点”这六个基本的可能结果之一,其样本空间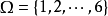 ,其中的1,2,3,4,5,6,就是六个样本点。2
,其中的1,2,3,4,5,6,就是六个样本点。2
样本点计算统计学家必须考虑和试图解决的一个问题是,进行一次试验时与某些事件的发生相关韵可能元素,这些问题属于概率的研究范围。在许多情况下,通过对样本空间中的点计数,就可以解决概率问题,而不需要实际列出每一个元素。这种计数的基本原理通常称为乘法规则。
乘法规则如果完成一个操作有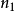 种方法,对于这些方法,完成第二个操作有
种方法,对于这些方法,完成第二个操作有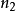 种方法,则完成这两个操作共有
种方法,则完成这两个操作共有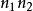 种方法。3
种方法。3
广义乘法规则如果完成一个操作有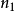 种方法,对其中每一种方法的第二个操作有
种方法,对其中每一种方法的第二个操作有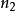 种方法,对前两步操作的每一种方法的第三个操作有
种方法,对前两步操作的每一种方法的第三个操作有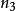 种方法,依次类推,则按顺序完成 k 步操作有
种方法,依次类推,则按顺序完成 k 步操作有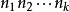 种方法。3
种方法。3
样本点排序对单个随机变量进行处理,主要目的是使生成的各个变量的样本点值能服从已知的概率分布函数。然而,各个随机变量之间还有给定的相关关系,这种相关关系由随机变量向量的相关系数矩阵来控制。为了使组合后的随机变量样本点序列能服从这种相关关系,需要专门研究样本点的排序算法。由于随机变量向量采用Nataf分布,在原变量空间或等效标准正态空间进行分析效果是相同的。这里采用在等效标准正态变量空间上进行分析,相关关系由等效相关系数矩阵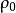 控制,样本点排序的迭代方法详细分析过程叙述如下。4
控制,样本点排序的迭代方法详细分析过程叙述如下。4
准备工作设有N维随机变量向量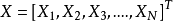 ,它们的边际概率分布函数为
,它们的边际概率分布函数为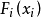 ,相关系数矩阵为
,相关系数矩阵为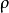 ,等效相关系数矩阵为
,等效相关系数矩阵为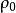 ,要求生成服从上述分布的N个样本点。
,要求生成服从上述分布的N个样本点。
首先对每个变量生成样本点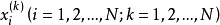 ,接着用一个整数矩阵
,接着用一个整数矩阵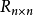 来记录所有样本点的排序信息。
来记录所有样本点的排序信息。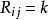 表示
表示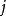 变量在第
变量在第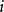 次抽样的取值在该变量的所有抽样点中排序为
次抽样的取值在该变量的所有抽样点中排序为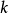 , 取值范围为1,2,…,N。在开始迭代之前将矩阵
, 取值范围为1,2,…,N。在开始迭代之前将矩阵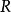 任意赋初值。例如有三个随机变量
任意赋初值。例如有三个随机变量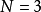 ,要求生成的样本点数量为
,要求生成的样本点数量为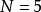 ,则 矩阵初始化后的一种可能形式为:
,则 矩阵初始化后的一种可能形式为:
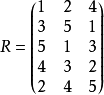 矩阵 提供的信息包含随机向量的抽样策略。共有个
矩阵 提供的信息包含随机向量的抽样策略。共有个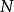 行向量,每个行向量代表随机变量向量的一次样本实现。4
行向量,每个行向量代表随机变量向量的一次样本实现。4
迭代运算(1)根据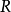 矩阵的信息生成随机变量向量样本集,通过统计分析可得到它的初始协方差矩阵
矩阵的信息生成随机变量向量样本集,通过统计分析可得到它的初始协方差矩阵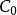 ;
;
(2)将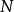 个样本点向量转换到等效标准正态变量空间,得到相应标准正态变量向量
个样本点向量转换到等效标准正态变量空间,得到相应标准正态变量向量 的样本点集
的样本点集
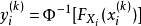
为简化分析,其中各个样本点的概率分布函数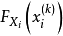 实际上可以近似地从该点的序号得出:
实际上可以近似地从该点的序号得出:
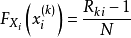
(3)对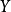 进行统计分析,得到相应的相关系数矩阵
进行统计分析,得到相应的相关系数矩阵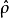 ,将
,将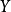 进行矩阵变换:
进行矩阵变换:
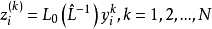
式中,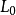 和
和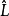 分别为
分别为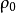 和
和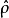 的Cholesky分解下三角矩阵,
的Cholesky分解下三角矩阵,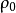 为目标等效相关系数矩阵。
为目标等效相关系数矩阵。
(4)根据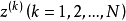 的大小顺序来更新
的大小顺序来更新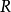 矩阵,并由
矩阵,并由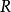 矩阵重新对随机变量向量
矩阵重新对随机变量向量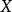 的
的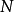 个样本进行排序。对所得到的样本进行统计分析,得到相应的协方差矩阵
个样本进行排序。对所得到的样本进行统计分析,得到相应的协方差矩阵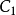 。
。
(5)将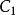 中的各元素和
中的各元素和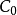 进行对比,如果两矩阵所有元素的差的绝对值都小于容许值,则认为迭代收敛,退出迭代,否则
进行对比,如果两矩阵所有元素的差的绝对值都小于容许值,则认为迭代收敛,退出迭代,否则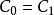 并回到步骤(2)继续迭代.
并回到步骤(2)继续迭代.
各个变量的样本点生成过程为确定性的,即每次抽样过程得到的样本集都是不变的。与此不同的是,样本排序的结果往往是随机的。4
算法的收敛性分析由样本点集统计出的随机变量相关系数是一个统计量,它只能接近原概率模型的真实值,而不能时刻等于真实值。传统的用随机模拟法生成的样本所对应的系数是一个具有概率背景的统计量,能以概率论证明:相关系数的统计量作为一种特殊的随机变量,当样本点数量逐渐增大时,其样本实现等于真实值的概率将趋近于1。与传统随机模拟法不同的是,Latin hypercube法是从算法角度确保相关系数统计量的合理性。但是,它是否也具备传统抽样方法的性质呢?为了说明这一点,下面分析一个实际例子。
设随机变量向量服从独立标准正态分布,即实际 相关系数矩阵应为单位矩阵,非主对角元素为0。采用前面说明的算法生成样本,并计算协方差矩阵统计量。由于目标协方差矩阵中非主对角元素应为零,所以将协方差统计量矩阵中非对角元素中的最大值,作为绝对误差值。当随机变量数目分别为
相关系数矩阵应为单位矩阵,非主对角元素为0。采用前面说明的算法生成样本,并计算协方差矩阵统计量。由于目标协方差矩阵中非主对角元素应为零,所以将协方差统计量矩阵中非对角元素中的最大值,作为绝对误差值。当随机变量数目分别为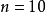 及
及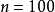 时,误差值随样本数目大小的变化规律计算结果见右图。由图所示的分析结果可知,此处采用的迭代算法同样具备收敛性质,即相关系数统计量和真实值的误差随样本量的增大而降低;从图中的结果还可发现,Latinhypercube法的相关系数统计量误差和随机变量数量无关。4
时,误差值随样本数目大小的变化规律计算结果见右图。由图所示的分析结果可知,此处采用的迭代算法同样具备收敛性质,即相关系数统计量和真实值的误差随样本量的增大而降低;从图中的结果还可发现,Latinhypercube法的相关系数统计量误差和随机变量数量无关。4

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国