

随机干扰可以指自动控制系统中的一种干扰,也可以指计量经济模型中的随机干扰项。
在自动控制系统中,存在着时隐时现, 忽大忽小,其变化规律不能用某一确定函数关系描述的干扰,这种干扰称随机干扰(random jamming ;stochastic disturbance)。如在雷达跟踪系统中,由于被搜索目标的运动 规律以及大量的干扰信号 (如空中电波干扰、飞机本身摆动),跟踪系统受到的干扰不能用确定的时间函数来描述,就具有随机性1。
随机干扰项,又称“随机误差项”、“随机扰动项”、“随机误差”、“随机项”、“误差项”、 “扰动项”等,指不包含在模型中的解释变量和其他一些随机因素对被解释变量的总影响项。随机干扰项一般包括:1)模型中省略的对被解释变量不重要的影响因素 (解释变量);2)解释变量和被解释变量的观测误差;3)经济系统中无法控制、不易度量的随机因素。模型数学形式的误差,如用线性模型近似非线性经济关系,不属于随机误差。将随机误差项引入模型,是经济计量学与数理经济学的根本区别2。
自动控制中的随机干扰干扰在自动控制中干扰又称扰动(disturbance)。被控对象及自动控制系统各个环节都存在着干扰。引起被调量变化的除调节量外的所有变量,以及影响各部件输出量变化的因素都可视作干扰。如电源电压的振幅和频率的变化,环境温度、湿度、气压的变化以及负载的变化等,都是每个系统普遍存在的干扰量。有效的自动调节与控制系统应具有补偿和克服内外干扰变化的能力,使被调量与给定值的偏差尽可能地减小,使被控量按一定的规律变化,从而使被控对象处于最优工作状态。
随机干扰在实验对象和自动控制系统中均存在着时隐时现、忽大忽小,其变化规律不能用某一函数关系描述的随机干扰(random disturbance)。这种干扰信号是一个随机量。例如:在雷达跟踪系统中,由于被搜索目标的运动规律以及大量的干扰信号(如空中电波干扰、飞机本身摆动等)是不能用确定的时间函数描述的,所以具有随机性,在生产过程中,由于原材料成分变化、环境条件变化以及设备内部条件的变化(如触媒老化),形成了大量随机干扰。因此,系统的分析与综合必须考虑存在随机干扰输入作用的情况3。
计量经济模型中随机干扰基本介绍经济计量模型由具体的方程式所组成的随机的经济数学模型。方程式为: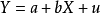 ,式中
,式中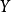 代表某种商品的需求量,
代表某种商品的需求量,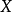 代表居民个人可支配收入。
代表居民个人可支配收入。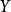 和
和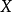 称为“经济变量”,即用以描述经济活动或经济现象的数量特征和数值变化的量。在式中,变量Y称为“被解释变量”,其数值的变化是因为模型中其他变量(X)的变化而引起的;变量X称为“解释变量”,其数值的变化不依赖于模型中其他变量的变化,而是自己独立进行的。式中
称为“经济变量”,即用以描述经济活动或经济现象的数量特征和数值变化的量。在式中,变量Y称为“被解释变量”,其数值的变化是因为模型中其他变量(X)的变化而引起的;变量X称为“解释变量”,其数值的变化不依赖于模型中其他变量的变化,而是自己独立进行的。式中 和
和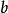 称为“参数”,它们是表示模型中变量之间数量关系的常系数。参数将各种变量连接在模型中,具体表明解释变量对被解释变量的影响程度。式中
称为“参数”,它们是表示模型中变量之间数量关系的常系数。参数将各种变量连接在模型中,具体表明解释变量对被解释变量的影响程度。式中 称为“随机干扰项”,也称“随机误差项”、“随机扰动项”,表明各种随机因素对模型的影响,反映了未纳入模型中的其他各种因素的影响。经济计量模型就是由有关的变量、相应的参数、随机扰动项组成的数学表达式,借以反映经济变量之间的因果相关关系。
称为“随机干扰项”,也称“随机误差项”、“随机扰动项”,表明各种随机因素对模型的影响,反映了未纳入模型中的其他各种因素的影响。经济计量模型就是由有关的变量、相应的参数、随机扰动项组成的数学表达式,借以反映经济变量之间的因果相关关系。
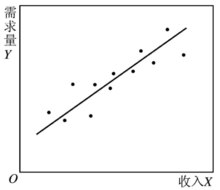
如果我们搜集到了变量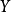 和变量
和变量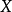 的历史统计数据(实际值),就可以用一定的方法计算出上述模型的参数a和b。对模型参数的计算称为“参数估计”。常用的估计模型参数的方法是“最小二乘法”。这种方法可使最终由模型计算出来的被解释变量的估计值与其实际值之差的平方和为最小,也就是可使最终由模型计算出来的被解释变量的估计值更接近其实际值。图中给出了解释变量X在不同水平上相对应的被解释变量Y的若干实际值的数据点。图中的直线就是由参数估计后的模型计算出来的被解释变量Y随解释变量X变化的估计值所连成的直线。这条直线拟合了原来的实际值,也就是说,将被解释变量原来的实际值在平均的意义上回归到一条估计值的直线上。这种将变量之间的因果相关关系定量地描述出来的分析方法称为“回归分析”。为回归分析而设定的经济计量模型称为“回归模型”。判断回归模型的估计值与被解释变量实际值的回归拟合程度的指标称为“判定系数”或“可决系数”。判定系数介于0和1之间,越接近于1,表明回归模型的拟合程度越好。变量和参数均以线性的形式来表达的回归模型称为“线性回归模型”。只含有一个解释变量的线性回归模型称为“一元线性回归模型”或“简单线性回归模型”。在一个方程式中含有一个以上的解释变量的线性回归模型称为“多元线性回归模型”。在多元线性回归模型中,各个解释变量之间不能存在线性相关关系。如果一个解释变量与其他解释变量之间存在着线性相关关系,则称该模型具有“多重共线性”。这将影响对模型参数估计的准确性。因此在建立多元线性回归模型时,在解释变量的选取上要避免出现多重共线性问题。只用一个方程式来描述经济关系中一个被解释变量变化的模型称为“单方程模型”。利用两个或两个以上方程式来描述经济关系中多个被解释变量变化的模型称为“多方程模型”。在解释变量中含有当期的内生变量的多方程模型称为“联立方程模型”。在联立方程模型中,变量分为两类:一类是作为被解释变量的内生变量,即其数值是在所设定的经济系统的模型内决定的。内生变量是对模型进行求解所要获得的结果。另一类是作为解释变量的前定变量,即其数值在模型求解之前已事先给定。前定变量包括外生变量和内生变量的滞后变量。外生变量是其数值在所设定的经济系统的模型之外来决定的变量,滞后变量是某个变量的时间滞后量。在上述模型中,假如变量X不取当期值而取其前期值,因居民个人可支配收入的前期值对当期的商品需求量有滞后的影响,则居民个人可支配收入的前期值称为“滞后变量”。在经济模型中,外生变量又可分为政策变量和非政策变量。政策变量又称“可控外生变量”,是指可由决策者控制的外生变量;非政策变量又称“非可控外生变量”,是指决策者难以控制或不能控制的外生变量4。
的历史统计数据(实际值),就可以用一定的方法计算出上述模型的参数a和b。对模型参数的计算称为“参数估计”。常用的估计模型参数的方法是“最小二乘法”。这种方法可使最终由模型计算出来的被解释变量的估计值与其实际值之差的平方和为最小,也就是可使最终由模型计算出来的被解释变量的估计值更接近其实际值。图中给出了解释变量X在不同水平上相对应的被解释变量Y的若干实际值的数据点。图中的直线就是由参数估计后的模型计算出来的被解释变量Y随解释变量X变化的估计值所连成的直线。这条直线拟合了原来的实际值,也就是说,将被解释变量原来的实际值在平均的意义上回归到一条估计值的直线上。这种将变量之间的因果相关关系定量地描述出来的分析方法称为“回归分析”。为回归分析而设定的经济计量模型称为“回归模型”。判断回归模型的估计值与被解释变量实际值的回归拟合程度的指标称为“判定系数”或“可决系数”。判定系数介于0和1之间,越接近于1,表明回归模型的拟合程度越好。变量和参数均以线性的形式来表达的回归模型称为“线性回归模型”。只含有一个解释变量的线性回归模型称为“一元线性回归模型”或“简单线性回归模型”。在一个方程式中含有一个以上的解释变量的线性回归模型称为“多元线性回归模型”。在多元线性回归模型中,各个解释变量之间不能存在线性相关关系。如果一个解释变量与其他解释变量之间存在着线性相关关系,则称该模型具有“多重共线性”。这将影响对模型参数估计的准确性。因此在建立多元线性回归模型时,在解释变量的选取上要避免出现多重共线性问题。只用一个方程式来描述经济关系中一个被解释变量变化的模型称为“单方程模型”。利用两个或两个以上方程式来描述经济关系中多个被解释变量变化的模型称为“多方程模型”。在解释变量中含有当期的内生变量的多方程模型称为“联立方程模型”。在联立方程模型中,变量分为两类:一类是作为被解释变量的内生变量,即其数值是在所设定的经济系统的模型内决定的。内生变量是对模型进行求解所要获得的结果。另一类是作为解释变量的前定变量,即其数值在模型求解之前已事先给定。前定变量包括外生变量和内生变量的滞后变量。外生变量是其数值在所设定的经济系统的模型之外来决定的变量,滞后变量是某个变量的时间滞后量。在上述模型中,假如变量X不取当期值而取其前期值,因居民个人可支配收入的前期值对当期的商品需求量有滞后的影响,则居民个人可支配收入的前期值称为“滞后变量”。在经济模型中,外生变量又可分为政策变量和非政策变量。政策变量又称“可控外生变量”,是指可由决策者控制的外生变量;非政策变量又称“非可控外生变量”,是指决策者难以控制或不能控制的外生变量4。
随机干扰存在的原因在经济活动中,有多种原因会引起误差。在经济计量模型的行为方程和技术方程中,随机误差项所体现的误差,主要包括以下若干方面5:
变量误差
即由于模型所包含的变量不完全所引起的误差。实际的经济系统要同时受众多因素的影响,在建立模型时,最理想的作法是将所有影响因素无一遗漏地反映到模型中去。但这在实际上既不可能,又无必要。因为,要将所有因素不分主次地包罗到模型中去,势必将使模型臃肿、庞杂,失去其抽象、概括的能力,况且由于条件的限制,实际上也准以完全把握所有的影响因素。因此,通常的作法就是从简化出发,强调抓主要矛盾,力求使模型在尽可能反映实际经济运行情况的前提下,包含尽可能少的经济变量,把某些暂时尚未认识到或无法观察计量到以及认为影响力极小的经济变黾予以忽略。这种忽略就必然产生一定的误差,即变量误差。 ·
模型误差
模型误差,又称拟合误差,这是由于模型选择不当造成的误差。这里有两种情况:一是对单一方程计量模型而言,一般是依据样本数据散点分布趋势,选择与其逼近的拟合方程。无论这种拟合如何逼近,终究都是一种近似,这必然存在拟合误差,二是对联立方程模型而言,尽管可以靠扩大模型的规模,用尽可能多的方程去描述复杂的经济系统,但模型规模总是有限制的,必须省略一些方程,这又会造成误差。这些来源于模型的数学表达式是否得当,方程个数是否适度等引起的误差,统称为模型误差。
样本误差
就是由于样品数据不准、不全而造成的计量误差。这种误差来源于两个方面:一是所谓测量误差,即在获取变量数据的过程中, 由于数据观察者的主观条件或客观因素造成的测量失真,或因收集、处理、加工原始数据的方法不同,使样本数据不能完全真实地反映其真值;二是所谓归并误差,即某些反映总量的样本数据是由若干个分量加总得到的,其中包括不同时间,不同空间或同一时点上的不同来源数据的加总归并,在此过程中,同样会使原始数据产生扭曲变形,造成样本误差。
其他****原因造成的误差
除上述误差外,还有其他意想不到的偶然因素造成的误差。在计量过程中,还会有计量方法的选择而造成的估算误差等等。
所有上述这些有形的和无形的,能定量表示的和不能定量表示的误差,都统统归于随机误差项之中,成为其生成的直接原因3。
对随机干扰项u的若干假设为了对包含有随机误差项u的行为方程或技术方程进行参数估计,就应该首先具备计量方程中内生变量、外生变量和随机项。的观测数据。但实际上, u是既看不见,又摸不着的多因素的综合体,其数值是观察不到的。因此,为了推测其数值分布规律,同时也为了简化计量工作,在经济计量过程中就对u作出了若干假设,赋予某些统计特性,这不仅简化了计量工作,而且为后面参数估计中的某些推导证明提供出一些理论前提。关于对u的假定,几乎在所有经济计量学的著述中都有阐述,虽表达方式不尽相同,但基本内容是一致的。这里以一元线性计量模型为例,从两个方面分述如下。
与u有关的假定
这主要是对线性计量模型: 中的自变量z所作的假定,就是假定z是取值固定的随机变量。
中的自变量z所作的假定,就是假定z是取值固定的随机变量。
u自身的假定
这是对随机项u本身所作的假定,主要的是:
假定1u是服从正态分布的随机变量。就是说当u是在多种随机因素共同作用之下时, u在任意时期的取值都服从正态的概率分布。由于前已假定在一元线性计量模型中, 自变量z址非随机变量,而因变量y却是与u一样是服从正态分布的,因此,可用图1来直观的表示出来它们之间的关系。由图看出,对于一元线性计量模型来说,当外生变量z取固定值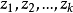 时, 由于随机误差u的取值概率P(u)是服从正态分布的,因而使内生变量y也是以正态分布概率取值为
时, 由于随机误差u的取值概率P(u)是服从正态分布的,因而使内生变量y也是以正态分布概率取值为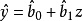 。这种把u视为具有正态分布概率的假定是极重要的统计特性之一。
。这种把u视为具有正态分布概率的假定是极重要的统计特性之一。

假定2u是以零为期望值的随机变量。用数学符号表达就是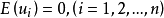 。对此假定的直观解释,就是对外生变量z的每一个固定值,u可以按某种概率取不同的值,但若同时考虑u的取值,则从平均意义上讲,彼此之间有互相抵消的作用,使其平均值呈现以零为中心点,作幅度有限的正负波动。
。对此假定的直观解释,就是对外生变量z的每一个固定值,u可以按某种概率取不同的值,但若同时考虑u的取值,则从平均意义上讲,彼此之间有互相抵消的作用,使其平均值呈现以零为中心点,作幅度有限的正负波动。
假定3u的同方差性假定。即假定对应于各次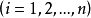 观察值的
观察值的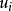 ,其方差是一个常数。用数学符号表达就是
,其方差是一个常数。用数学符号表达就是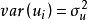 =常数。这一假定的直观表示就是在图1中,对应于
=常数。这一假定的直观表示就是在图1中,对应于 的取值,
的取值,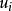 的正态分布曲线其形状相同。显然,该假定是认为经济过程是平稳的随机过程,它隐含着各次观察值,它们无论是时间序列数据,还是横断面资料,所显现出来的彼此是相互独立的,互不影响的,用数学符号表达就是
的正态分布曲线其形状相同。显然,该假定是认为经济过程是平稳的随机过程,它隐含着各次观察值,它们无论是时间序列数据,还是横断面资料,所显现出来的彼此是相互独立的,互不影响的,用数学符号表达就是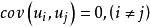 。一般在时间序列资料中,该假定是指前后期的
。一般在时间序列资料中,该假定是指前后期的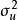 不随时间而变化,保持前后期相等,故称之为方差齐一性。将上述综合表示出来,一般可采用如下形式:
不随时间而变化,保持前后期相等,故称之为方差齐一性。将上述综合表示出来,一般可采用如下形式:
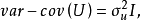 式中:
式中: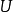 ——各次观察数据随机误差的列向量,即
——各次观察数据随机误差的列向量,即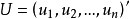 ;
;
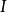 ——单位向量矩阵,其阶数为打X刀阶,即也可表示成:
——单位向量矩阵,其阶数为打X刀阶,即也可表示成:
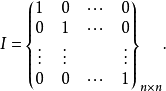 也可以表示成:
也可以表示成:
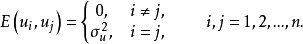
综合以上三种假设,就可对u的分布特性表述为:它是以零为期望值,以为方差的正态分布随机变量。用数学符号表达就是:
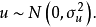
假定4u与各解释变数即自变量无关。用数学符号表示就是:
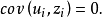
在上述所有假定都成立的条件下,该假定是不难证明其存在性的。这是因为:
已知 且
且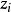 为取固定值的变量,所以
为取固定值的变量,所以
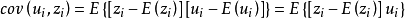
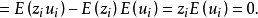
这一假定在计量分析过程中也是时常用到的统计特性之一。
至于说上述这些假设是否成立,能否符合实际情况,还需再作具体分析5。
本词条内容贡献者为:
尚华娟 - 副教授 - 上海财经大学

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国