

k平均聚类发明于1956年,是一个聚类算法,把n的对象根据他们的属性分为k个分割,k 简介
k-平均算法(英文:k-means clustering)源于信号处理中的一种向量量化方法,现在则更多地作为一种聚类分析方法流行于数据挖掘领域。k-平均聚类的目的是:把{\displaystyle n}个点(可以是样本的一次观察或一个实例)划分到k个聚类中,使得每个点都属于离他最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准。这个问题将归结为一个把数据空间划分为Voronoi cells的问题。
这个问题在计算上是NP困难的,不过存在高效的启发式算法。一般情况下,都使用效率比较高的启发式算法,它们能够快速收敛于一个局部最优解。这些算法通常类似于通过迭代优化方法处理高斯混合分布的最大期望算法(EM算法)。而且,它们都使用聚类中心来为数据建模;然而k-平均聚类倾向于在可比较的空间范围内寻找聚类,期望-最大化技术却允许聚类有不同的形状。
k-平均聚类与k-近邻之间没有任何关系(后者是另一流行的机器学习技术)。1
算法描述已知观测集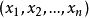 ,其中每个观测都是一个{\displaystyle d}-维实向量,k-平均聚类要把这n个观测划分到k个集合中(k≤n),使得组内平方和(WCSS within-cluster sum of squares)最小。换句话说,它的目标是找到使得下式满足的聚类
,其中每个观测都是一个{\displaystyle d}-维实向量,k-平均聚类要把这n个观测划分到k个集合中(k≤n),使得组内平方和(WCSS within-cluster sum of squares)最小。换句话说,它的目标是找到使得下式满足的聚类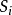 ,
,
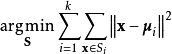 其中
其中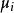 是
是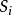 中所有点的均值。1
中所有点的均值。1
历史源流虽然其思想能够追溯到1957年的Hugo Steinhaus,术语“k-均值”于1967年才被James MacQueen首次使用。标准算法则是在1957年被Stuart Lloyd作为一种脉冲码调制的技术所提出,但直到1982年才被贝尔实验室公开出版。在1965年,E.W.Forgy发表了本质上相同的方法,所以这一算法有时被称为Lloyd-Forgy方法。更高效的版本则被Hartigan and Wong提出(1975/1979)。1
本词条内容贡献者为:
胡启洲 - 副教授 - 南京理工大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国