

背景介绍
数据分类(Classification)在商业应用上具有重要意义,是数据挖掘中非常重要的一项研究内容。通常数据分类的做法是,基于样本数据先训练构建分类函数或者分类模型(也称为分类器),该分类器的具有将待分类数据项映射到某一特点类别的功能,数据分类和回归分析都可用于预测,预测是指从基于样本数据记录,根据分类准则自动给出对未知数据的推广描述,从而实现对未知数据进行预测1。
贝叶斯分类是统计学的分类方法,其分析方法的特点是使用概率来表示所有形式的不确定性,学习或推理都要用概率规则来实现。
贝叶斯分类的原理基于统计学的贝叶斯分类方法以贝叶斯理论为基础,通过求解后验概率分布,预测样本属于某一类别的概率。贝叶斯公式可写成如下形式:
**P(y|x)=P(x|y)*P(A)*P(y)/(P(x) (4-1)**其中,P(y I x)为后验概率分布,P(y)为先验分布,P(x)通常为常数。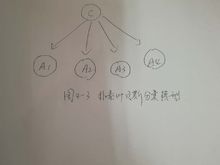
为了简化运算,朴素贝叶斯分类算法假定任意属性对类别的影响与其他属性对类别的影响无关,这种假定称为类条件独立朴素假定。图4-3展示了朴树贝叶斯分类中属性和类之间的关系,如图4-3所示,C表示待分类别,A1, ..., A4表示样本属性,箭头表示属性变量和类别变量之间的依存关系,从图中可以看出,在朴素贝叶斯分类模型中,样本属性Ai和Aj ( i不等于j)之间不存在相互依赖关系,他们仅与节点类C有关1。
已知样本数据x =(样本数据x共有n种属性,其中xi表示第i个属性Ai的值)属于任意类,(y∈ { c1,,...,ck})(总共k个类别,cj表示第j个类)的概率。给定一个未分类的数据样本X,应用朴素贝叶斯分类算法,预测样本数据X属于具有最高后验概率的类,未知样本X属于类别c;的条件是,当且仅当
P(ciIX)>P (cjIX),1≤j≤k, (4-2)
因此,将最大化后验概率P(ciIX)或者其对数形式称为最大后验假定,记为arg maxy P( y IX)。
根据全概率公式,对于任意类别ci。
在任意一次分类中取值均相等,也就是说,数据样本X产生的概率相同(P(X)定义为常数),因此,可以将后验概率P(yl X)表示成概率乘积正比关系式:
P(yIX)∝P(XIy)*P(y)
因此,求取arg maxyP( y IX)相当于求取arg maxyP(XIy);而arg maxyP(XIy)的计算要相对容易很多,所以,在实际应用中通常根据式(4-4 )来求解后验概率。
根据朴素贝叶斯分类算法的类条件独立假设,给定样本数据的类标号,各属性值xi之间相互条件独立,彼此不存在相互依赖关系。
也就是说,为对未知样本X分类,对每个类ci计算P(xl ci)P(ci);当且仅当P(Xlci)P(ci)>P(Xlcj)P(cj),1≤j≤m,j≠i (4-7)
定义样本X属于类别ci,即X被指派到P(X I ci)P(ci)最大的类ci1。
贝叶斯分类特点贝叶斯分类是统计学方法,它主要是基于贝叶斯定理。通过计算给定实例属于一个特定类的概率来对给定实例进行分类。贝叶斯分类具有以下特点:
(1)贝叶斯分类不把一个实例绝对的指派给某一种分类,而是通过计算得到实例属于某一分类的概率,具有最大概率的类就是该实例所属的分类;
(2)一般情况下在贝叶斯分类中所有属性都潜在的对分类结果发挥作用,能够使所有的属性都参与到分类中;
(3)贝叶斯分类实例的属性可以是离散的、连续的,也可以是混合的。
贝叶斯方法因其在理论上给出了最小化误差的最优解决方法而被广泛应用于分类问题。在贝叶斯方法的基础上,提出了贝叶斯网络((Bayesian Network, BN)方法。朴素贝叶斯分类就是假定一个属性对于给定分类的影响独立于其他属性。这一假定被称作条件独立,对实力属性的这种假设大大简化了分类所需的计算量。大量的研究结果表明,虽然BN算法对属性结点之间的连接结构进行了限制,但是朴素贝叶斯的分类器的分类性能优于标准的贝叶斯网络分类器2。

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国