

搜索引擎的基本工作原理包括如下三个过程:首先在互联网中发现、搜集网页信息;同时对信息进行提取和组织建立索引库;再由检索器根据用户输入的查询关键字,在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并将查询结果返回给用户。
工作原理搜索引擎为了以最快的速度得到搜索结果,它搜索的通常是预先整理好的网页索引数据库。搜索引擎,不能真正理解网页上的内容,它只能机械地匹配网页上的文字。真正意义上的搜索引擎,通常指的是收集了互联网上几千万到几十亿个网页并对网页中的每一个文字(即关键词)进行索引,建立索引数据库的全文搜索引擎。当用户查找某个关键词的时候,所有在页面内容中包含了该关键词的网页都将作为搜索结果被搜出来。在经过复杂的算法进行排序后,这些结果将按照与搜索关键词的相关度高低,依次排列。典型的搜索引擎三大模块组成:
(一)信息采集模块
信息采集器是一个可以浏览网页的程序,被形容为“网络爬虫”。它首先打开一个网页,然后把该网页的链接作为浏览的起始地址,把被链接的网页获取过来,抽取网页中出现的链接,并通过一定算法决定下一步要访问哪些链接。同时,信息采集器将已经访问过的URL存储到自己的网页列表并打上已搜索的标记。自动标引程序检查该网页并为他创建一条索引记录,然后将该记录加入到整个查询表中。信息收集器再以该网页到超链接为起点继续重复这一访问过程直至结束。一般搜索引擎的采集器在搜索过程中只取链长比(超链接数目与文档长度的比值)小于某一阀值的页面,数据采集于内容页面,不涉及目录页面。在采集文档的同时记录各文档的地址信息、修改时间、文档长度等状态信息,用于站点资源的监视和资料库的更新。在采集过程中还可以构造适当的启发策略,指导采集器的搜索路径和采集范围,减少文档采集的盲目性。
(二)查询表模块
查询表模块是一个全文索引数据库,他通过分析网页,排除HTML等语言的标记符号,将出现的所有字或词抽取出来,并记录每个字词出现的网址及相应位置(比如是出现在网页标题中,还是出现在简介或正文中),最后将这些数据存入查询表,成为直接提供给用户搜索的数据库。
(三)检索模块
检索模块是实现检索功能的程序,其作用是将用户输入的检索表达式拆分成具有检索意义的字或词,再访问查询表,通过一定的匹配算法获得相应的检索结果。返回的结果一般根据词频和网页链接中反映的信息建立统计模型,按相关度由高到低的顺序输出。1
工作机制搜索引擎的工作机制就是采用高效的蜘蛛程序,从指定URL开始顺着网页上的超链接,采用深度优先算法或广度优先算法对整个Internet进行遍历,将网页信息抓取到本地数据库。然后使用索引器对数据库中的重要信息单元,如标题,关键字及摘要等或者全文进行索引,以供查询导航。最后,检索器将用户通过浏览器提交的查询请求与索引数据库中的信息以某种检索技术进行匹配,再将检索结果按某种排序方法返回给用户。
工作流程(1)在互联中发现、搜集网页信息
搜索引擎首先负责数据采集,即按照一定的方式和要求对网络上的WWW站点进行搜集,并把所获得的信息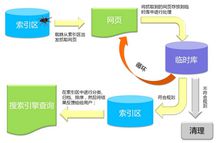 保存下来以备建立索引库和用户检索。但是收集网页只是搜索引擎的一部分工作,他们的其他服务器要做的还有进行计算/分配/储存用户习惯等等。
保存下来以备建立索引库和用户检索。但是收集网页只是搜索引擎的一部分工作,他们的其他服务器要做的还有进行计算/分配/储存用户习惯等等。
(2)对信息进行提取和组织建立索引库
首先是数据分析与标引,搜索引擎对已经收集到的资料给与按照网页中的字符特性予以分类,建立搜索原则,举例来说,对于"软件"这个词,它必须建立一个索引,当用户查找的时候,他知道到这里来调取资料。当然,对于网页语言,该字符的处理(大小写/中文的断字方式等等)等方面,各个搜索引擎都有自己的存档归类方式,这些方式往往影响着未来搜索结果。接下来是数据组织,搜索引擎负责形成规范的索引数据库或便于浏览的层次型分类目录结构,也就是计算网页等级,这个原则特别是在Google非常重要,一个接受很多链接的网页,搜索引擎必然在所有的网页当中将这些连接多的网页提升上来。
(3)在索引数据库中搜索排序
由检索器根据用户输入的查询关键字,在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并将查询结果返回给用户。搜索引擎负责帮助用户用一定的方式检索索引数据库,获取符合用户需要的WWW信息。搜索引擎还负责提取用户相关信息,利用这些信息来提高检索服务的质量,信息挖掘在个性化服务中起到关键作用。用户检索的过程是对前两个过程的检验,检验该搜索引擎能否给出最准确、最广泛的信息,检验该搜索引擎能否迅速地给出用户最想得到的信息。2
搜索引擎在搜索引擎分类部分我们提到过全文搜索引擎从网站提取信息建立网页数据库的概念。搜索引擎的自动信息搜集功能分两种。一种是定期搜索,即每隔一段时间(比如Google一般是28天),搜索引擎主动派出“蜘蛛”程序,对一定IP地址范围内的互联网站进行检索,一旦发现新的网站,它会自动提取网站的信息和网址加入自己的数据库。
另一种是提交网站搜索,即网站拥有者主动向搜索引擎提交网址,它在一定时间内(2天到数月不等)定向向你的网站派出“蜘蛛”程序,扫描你的网站并将有关信息存入数据库,以备用户查询。由于搜索引擎索引规则发生了很大变化,主动提交网址并不保证你的网站能进入搜索引擎数据库,因此目前最好的办法是多获得一些外部链接,让搜索引擎有更多机会找到你并自动将你的网站收录。
当用户以关键词查找信息时,搜索引擎会在数据库中进行搜寻,如果找到与用户要求内容相符的网站,便采用特殊的算法——通常根据网页中关键词的匹配程度,出现的位置、频次,链接质量等——计算出各网页的相关度及排名等级,然后根据关联度高低,按顺序将这些网页链接返回给用户。3
性能指标在通常情况下,我们可以从以下几个方面来衡量一个搜索引擎的性能:
查全率指搜索引擎提供的检索结果中相关文档数与网络中存在的相关文档数之比,他是搜索引擎对网络信息覆盖率的真实反映。
查准率是搜索引擎提供的检索结果与用户信息需求的匹配程度,也是检索结果中有效文档数与搜索引擎提供的全部文档数之比。
响应时间一般而言取决于2个因素,即与带宽有关的网络速度和搜索引擎本身的速度,只有在二者均获得可靠的技术支持的情况下,才能保证理想的检索速度。对搜索引擎来讲,查全率和查准率很难做到两全其美,影响搜索引擎的性能的主要是信息检索模型,包括文档和查询的表示方法、评价文档和用户查询相关性的匹配策略、查询结果的排序方法和用户进行相关度反馈的机制。
本词条内容贡献者为:
徐恒山 - 讲师 - 西北农林科技大学

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国