

定义
相似性度量,即综合评定两个事物之间相近程度的一种度量。两个事物越接近,它们的相似性度量也就越大,而两个事物越疏远,它们的相似性度量也就越小。相似性度量的给法种类繁多,一般根据实际问题进行选用。常用的相似性度是有:相关系数(衡量变量之间接近程度),相似系数(衡量样品之间接近程度),若样品给出的是定性数据,这时衡量样品之间接近程度,可用样本的匹配系数、一致度等。1
用数量化方法对事物进行分类,就必须用数量化方法描述事物间的相似程度。一个事物常常需要用多个变量来刻画,如对一群用p个变量描述的样本点进行分类,则每个样本点可看做是p维空间的一个点,很自然的想到用距离来度量样本点间的相似程度。2
基础知识距离设Ω是所有样本点的集合,距离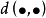 是Ω×Ω→
是Ω×Ω→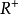 的一个函数,满足条件:
的一个函数,满足条件:
(1)正定性: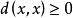 ,x,y
,x,y Ω;d(x,x)=0,当且仅当x=0;
Ω;d(x,x)=0,当且仅当x=0;
(2)对称性:d(x,y)=d(y,x),x,yΩ;
(3)三角不等式: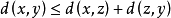 ,x,y,zΩ。2
,x,y,zΩ。2
相关系数设变量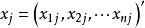
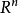 ,j=1,2,
,j=1,2,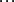 ,p,则可以用两变量
,p,则可以用两变量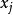 和
和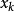 的样本相关系数
的样本相关系数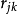 作为它们的相似性度量。变量之间的相关系数组成的矩阵称为相关系数矩阵,且相关系数矩阵是一个实对称矩阵,通常用上三角矩阵或下三角矩阵来表示。2
作为它们的相似性度量。变量之间的相关系数组成的矩阵称为相关系数矩阵,且相关系数矩阵是一个实对称矩阵,通常用上三角矩阵或下三角矩阵来表示。2
角度相似性度量目前为止都是在用距离来度量样本之间的相似程度,实际上在某些情况下可以采用角度相似性度量。
如果认为两个样本之间的相似程度只与它们之间的夹角有关,而与矢量的长度无关,那么就可以使用矢量夹角的余弦来度量相似性。有:s(x,y)=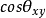 =
=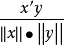 。
。
(1)当x与y重合时,夹角为0,相似度最大:s(x,y)=1;
(2)当x与y方向相反时,夹角为π,相似度最小:s(x,y)=-1;3
聚类分析中的相似性度量聚类通常按照对象间的相似性进行分组,因此如何描述对象间相似性是聚类的重要问题。数据的类型不同,相似性的含义也不同。例如,对数值型数据而言,两个对象的相似度是指它们在欧氏空间中的互相邻近的程度;而对分类型数据来说,两个对象的相似度是与它们取值相同的属性的个数有关。
聚类分析按照样本点之间的亲疏远近程度进行分类。为了使类分得合理,必须描述样本之间的亲疏远近程度。刻画聚类样本点之间的亲疏远近程度主要有以下两类函数:
(1)相似系数函数:两个样本点愈相似,则相似系数值愈接近1;样本点愈不相似,则相似系数值愈 接近0。这样就可以使用相似系数值来刻画样本点性质的相似性。
(2)距离函数:可以把每个样本点看作高维空间中的一个点,进而使用某种距离来表示样本点之间的相似性,距离较近的样本点性质较相似,距离较远的样本点则差异较大。
需要由领域专家确定采用哪些指标特征变量来精确刻画样本的性质,以及如何定义样本之间的相似性测度。

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国