

背景
维数灾难最早是由理查德·贝尔曼(Richard E. Bellman)在考虑优化问题时提出来的1,它用来描述当(数学)空间维度增加时,分析和组织高维空间(通常有成百上千维)中的数据,因体积指数增加而遇到各种问题场景。
该名词涉及数字分析、抽样、组合、机器学习、数据挖掘和数据库等诸多领域。 在这些领域中,该名词代表的共同特点是:当维度增加时,空间的体积增加得很快,使得可用的数据变得稀疏。稀疏性对于任何要求有统计学意义的方法而言都是一个问题,为了获得在统计学上正确并且有可靠的结果,用来支撑这一结果所需要的数据量通常随着维数的提高而呈指数级增长。而且,在组织和搜索数据时也有赖于检测对象区域,这些区域中的对象通过相似度属性而形成分组。然而在高维空间中,所有的数据都很稀疏,从很多角度看都不相似,因而平常使用的数据组织策略变得极其低效。
“维数灾难”通常是用来作为不要处理高维数据的无力借口。然而,学术界一直都对其有兴趣,而且在继续研究。另一方面,也由于本征维度的存在,其概念是指任意低维数据空间可简单地通过增加空余或随机维将其转换至更高维空间中,相反地,许多高维空间中的数据集也可降维至低维空间数据,而不必丢失重要信息。当前的研究也表明除非其中存在太多不相关的维度,带有维数灾难特色的数据集依然可以处理,因为相关维度实际上可使得许多问题(如聚类分析)变得更加容易2。
涉及领域组合学在一些问题中,每个变量都可取一系列离散值中的一个,或者可能值的范围被划分为有限个可能性。把这些变量放在一起,则必须考虑很多种值的组合方式,这后果就是常说的组合爆炸。即使在最简单的二元变量例子中,可能产生的组合总数就已经是在维数上呈现指数级的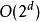 。一般而言,每个额外的维度都需要成倍地增加尝试所有组合方式的影响3。
。一般而言,每个额外的维度都需要成倍地增加尝试所有组合方式的影响3。
采样当在数学空间上额外增加一个维度时,其体积会呈指数级的增长。如,点间距离不超过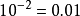 ,
,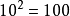 个均匀间距的样本点足够采样到一个单元区间(“一个维度的立方体”);一个10维单元超立方体的等价采样,其相邻两点间的距离为
个均匀间距的样本点足够采样到一个单元区间(“一个维度的立方体”);一个10维单元超立方体的等价采样,其相邻两点间的距离为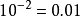 ,则需要
,则需要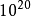 个样本点。一般而言,点距为
个样本点。一般而言,点距为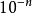 的10维超立方体所需要的样本点数量,是1维超立方体这样的单元区间的
的10维超立方体所需要的样本点数量,是1维超立方体这样的单元区间的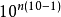 倍。
倍。
在上面的n=2的例子中:当样本距离为0.01时,10维超立方体所需要的样本点数量会比单元区间多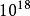 倍。这一影响就是上面所述组合学问题中的组合结果3。
倍。这一影响就是上面所述组合学问题中的组合结果3。
机器学习在机器学习问题中,需要在高维特征空间(每个特征都能够取一系列可能值)的有限数据样本中学习一种“自然状态”(可能是无穷分布),要求有相当数量的训练数据含有一些样本组合。给定固定数量的训练样本,其预测能力随着维度的增加而减小3。
贝叶斯统计在贝叶斯统计中维数灾难通常是一个难点,因为其后验分布通常都包含着许多参数4。
然而,这一问题在基于模拟的贝叶斯推理(尤其是适应于很多实践问题的马尔科夫蒙特卡洛方法)出现后得到极大地克服。当然,基于模拟的方法收敛很慢,因此这也并不是解决高维问题的灵丹妙药。
距离函数一种用来描述高维欧几里德空间的巨型性的方法是将超球体中半径 和维数
和维数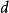 的比例,和超立方体中边长
的比例,和超立方体中边长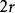 和等值维数的比例相比较。 这样一个球体的体积计算如下:
和等值维数的比例相比较。 这样一个球体的体积计算如下:
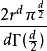
立方体的体积计算如下:
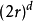
随着空间维度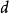 的增加,相对于超立方体的体积来说,超球体的体积就变得微不足道了。这一点可以从当 趋于无穷时比较前面的比例清楚地看出
的增加,相对于超立方体的体积来说,超球体的体积就变得微不足道了。这一点可以从当 趋于无穷时比较前面的比例清楚地看出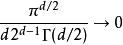
在某种意义上,几乎所有的高维空间都远离其中心。给定一个单一分布,由于其最小值和最大值与最小值相比收敛于0,即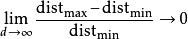 。因此,其最小值和最大值的距离变得不可辨别。
。因此,其最小值和最大值的距离变得不可辨别。
这通常被引证为距离函数在高维环境下失去其意义的例子5。
最近邻查询最近邻查询是区别于点的定位查询和范围查询的另一查询类型,人们的研究兴趣尤其是在高维空间,比如一些视频、图像、形状等数据。目前已有很多的最近邻查询方法被不断提出来,但是在高维情况下(比如 20 维),这些方法查询性能还不如对整个数据集合进行顺序检索性能好,甚至在10维就开始急剧恶化,人们称这种现象为维数灾难。6
可以证明,7当维数趋于极限值时,查询点到数据集中所有点的距离都相等,此时最近邻已经没有意义,也称为最近邻查询的不稳定性。
动态规划动态规划问题的维数即指的是各阶段上状态变量的维数。当状态变量的维数增加时,动态规划问题的计算量会呈指数倍增长,限制了人们用动态规划研究问题和解决问题的能力。
解决动态规划中的维数灾难的思想:降维,即通过一些特殊技巧或算法把一个高维的动态规划问题逐步分解为一些低维的动态规划问题,以此来减轻维数灾难。
模式识别根据模式识别理论,低维空间线性不可分的模式通过非线性映射到高维特征空间则可能实现线性可分,但是如果直接采用这种技术在高维空间进行分类或回归,则存在确定非线性映射函数的形式和参数、特征空间维数等问题,而最大的障碍则是在高维特征空间运算时存在的“维数灾难”。即维数越高,计算量越大。
解决方法:采用核函数技术可以有效地解决“维数灾难”。
现有的降维方法降维是通过将数据点映射到更低维的空间上以寻求数据的紧凑表示的一种技术,这种低维空间的紧凑表示将
有利于对数据的进一步处理。根据如何从原始特征中得到新的特征, 降维可分为特征选择和特征抽取两种。前者寻找原始特 征的一个子集来表达数据,后者则是寻找数据的新的低维特征,而这些新的特征不仅仅局限于原始特征的子集。8
基于特征抽取的降维方法基于低维投影的降维:主要包括主成分分析( Principal Component Analysis, PCA) 方法和投影寻踪 ( Projection Pursuit,PP) 方法
基于神经网络的降维:主要包括自动编码网络、自组织映射网络和生成建模
基于数据间相似度的降维:主要包括多维尺度、随机邻居嵌入、Isomap、局部线性嵌入和拉普拉斯特征映射
基于分形的降维8
基于特征选择的降维方法主要分为三大类:一类属于“过滤”的(filter)方法,另一类属于“包裹”的方法,还有通过范数进行特征选择的方法9。

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国