

流数据是指由数千个数据源持续生成的数据,通常也同时以数据记录的形式发送,规模较小(约几千字节)。流数据包括多种数据,例如客户使用您的移动或 Web 应用程序生成的日志文件、网购数据、游戏内玩家活动、社交网站信息、金融交易大厅或地理空间服务,以及来自数据中心内所连接设备或仪器的遥测数据。
此类数据需要按记录或根据滑动时间窗口按顺序进行递增式处理,可用于多种分析,包括关联、聚合、筛选和取样。借助此类分析得出的信息,公司得以深入了解其业务和客户活动的方方面面,例如服务使用情况(用于计量/计费)、服务器活动、网站点击量以及设备、人员和实物的地理位置,从而迅速对新情况做出响应。例如,公司可以持续分析社交媒体流,从而跟踪公众对其品牌和产品的看法的变化,并在必要时及时做出反应。1
流数据优势及特点对于持续生成动态新数据的大多数场景,采用流数据处理是有利的。这种处理方法适用于大多数行业和大数据使用案例。通常情况下,各公司一开始都是从简单的应用程序开始,例如收集系统日志以及进行滚动计算最小值-最大值等初级处理。然后,这些应用程序逐渐发展为需要完成更加复杂的近实时处理。最初,应用程序可能通过处理数据流生成简单的报告,然后再执行一些简单的响应操作,例如在关键指标超出一定阀值时发出警报。最终,这些应用程序会执行形式更加复杂的数据分析,如应用机器学习算法,还会从数据中提取更深入的信息。经过一段时间后,开始应用复杂的流事件处理算法,如利用时间窗口衰减算法查找最近的热门电影,进一步丰富了信息内容。1
流数据具有四个特点:
1)数据实时到达;
2)数据到达次序独立,不受应用系统所控制;
3)数据规模宏大且不能预知其最大值;
4)数据一经处理,除非特意保存,否则不能被再次取出处理,或者再次提取数据代价昂贵。
应用及示例流数据在网络监控、传感器网络、航空航天、气象测控和金融服务等应用领域广泛出现,通过对流数据研究可以进行卫星云图监测、股市走向分析、网络攻击判断等。2
流数据示例
1. 交通工具、工业设备和农业机械上的传感器将数据发送到流处理应用程序。该应用程序再监控性能,提前检测任何潜在缺陷,自动订购备用部件,从而防止设备停机。
2. 一家金融机构实时跟踪股市波动,计算风险价值,然后根据股票价格变动自动重新平衡投资组合。
3. 一家房地产网站跟踪客户移动设备中的一部分数据,然后根据其地理位置实时建议应走访的房产。
4. 一家太阳能发电公司必须维持可满足客户需求的发电量,否则就要支付罚金。该公司实施了一个流数据应用程序,用以监控电力系统中的所有电池板,并实时调度服务,从而最大限度缩短了每个电池板的低产能期,也因此减少了相关的罚款支出。
5. 一家媒体出版商对数十亿的在线内容点击流记录进行流处理,利用有关用户的人口统计信息汇总和丰富数据,并优化网站上的内容投放,从而实现关联性并为受众提供更佳的体验。
6. 一家网络游戏公司收集关于玩家与游戏间互动的流数据,并将这些数据提供给游戏平台,然后再对这些数据进行实时分析,并提供各种激励措施和动态体验来吸引玩家。
比较批处理与流处理在讨论流数据之前,有必要比较一下流处理和批处理。批处理可用于计算对不同数据集的任意查询。它一般用于计算从所含的所有数据得到的结果,并实现对大数据集的深入分析。例如,Amazon EMR 等基于MapReduce 的系统就是支持批处理任务的平台。相反,流处理则需要摄取一个数据序列,增量式更新指标、报告和汇总统计结果,以响应每个到达的数据记录。这种处理方法更适合实时监控和响应函数。
| 批处理 | 流处理 | |
| 数据范围 | 对数据集中的所有或大部分数据进行查询或处理。 | 对滚动时间窗口内的数据或仅对最近的数据记录进行查询或处理。 |
| 数据大小 | 大批量数据。 | 单条记录或包含几条记录的微批量数据。 |
| 性能 | 几分钟至几小时的延迟。 | 只需大约几秒或几毫秒的延迟。 |
| 分析 | 复杂分析。 | 简单的响应函数、聚合和滚动指标。 |
很多组织纷纷结合使用两种方法,从而构建一种混合模式,并同时维持实时处理层和批处理层。数据首先经由流数据平台(如 Amazon Kinesis)处理,以提取实时信息,然后保存到 S3 等存储中,数据可在此进行转换和加载,以用于各种批处理使用案例。1
流式大数据处理框架许多分布式计算系统都可以实时或接近实时地处理大数据流。这里将对三种Apache框架分别进行简单介绍,然后尝试快速、高度概述其异同。
Apache Storm
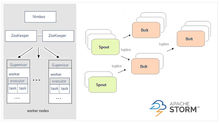 在Storm中,先要设计一个用于实时计算的图状结构,我们称之为拓扑(topology)。这个拓扑将会被提交给集群,由集群中的主控节点(master node)分发代码,将任务分配给工作节点(worker node)执行。一个拓扑中包括spout和bolt两种角色,其中spout发送消息,负责将数据流以tuple元组的形式发送出去;而bolt则负责转换这些数据流,在bolt中可以完成计算、过滤等操作,bolt自身也可以随机将数据发送给其他bolt。由spout发射出的tuple是不可变数组,对应着固定的键值对。
在Storm中,先要设计一个用于实时计算的图状结构,我们称之为拓扑(topology)。这个拓扑将会被提交给集群,由集群中的主控节点(master node)分发代码,将任务分配给工作节点(worker node)执行。一个拓扑中包括spout和bolt两种角色,其中spout发送消息,负责将数据流以tuple元组的形式发送出去;而bolt则负责转换这些数据流,在bolt中可以完成计算、过滤等操作,bolt自身也可以随机将数据发送给其他bolt。由spout发射出的tuple是不可变数组,对应着固定的键值对。
Apache Spark
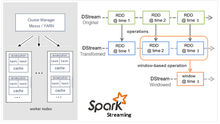 Spark Streaming是核心Spark API的一个扩展,它并不会像Storm那样一次一个地处理数据流,而是在处理前按时间间隔预先将其切分为一段一段的批处理作业。Spark针对持续性数据流的抽象称为DStream(DiscretizedStream),一个DStream是一个微批处理(micro-batching)的RDD(弹性分布式数据集);而RDD则是一种分布式数据集,能够以两种方式并行运作,分别是任意函数和滑动窗口数据的转换。
Spark Streaming是核心Spark API的一个扩展,它并不会像Storm那样一次一个地处理数据流,而是在处理前按时间间隔预先将其切分为一段一段的批处理作业。Spark针对持续性数据流的抽象称为DStream(DiscretizedStream),一个DStream是一个微批处理(micro-batching)的RDD(弹性分布式数据集);而RDD则是一种分布式数据集,能够以两种方式并行运作,分别是任意函数和滑动窗口数据的转换。
Apache Samza
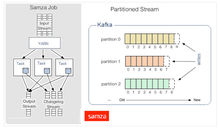 Samza处理数据流时,会分别按次处理每条收到的消息。Samza的流单位既不是元组,也不是Dstream,而是一条条消息。在Samza中,数据流被切分开来,每个部分都由一组只读消息的有序数列构成,而这些消息每条都有一个特定的ID(offset)。该系统还支持批处理,即逐次处理同一个数据流分区的多条消息。Samza的执行与数据流模块都是可插拔式的,尽管Samza的特色是依赖Hadoop的Yarn(另一种资源调度器)和Apache Kafka。
Samza处理数据流时,会分别按次处理每条收到的消息。Samza的流单位既不是元组,也不是Dstream,而是一条条消息。在Samza中,数据流被切分开来,每个部分都由一组只读消息的有序数列构成,而这些消息每条都有一个特定的ID(offset)。该系统还支持批处理,即逐次处理同一个数据流分区的多条消息。Samza的执行与数据流模块都是可插拔式的,尽管Samza的特色是依赖Hadoop的Yarn(另一种资源调度器)和Apache Kafka。
共同之处
以上三种实时计算系统都是开源的分布式系统,具有低延迟、可扩展和容错性诸多优点,它们的共同特色在于:允许你在运行数据流代码时,将任务分配到一系列具有容错能力的计算机上并行运行。此外,它们都提供了简单的API来简化底层实现的复杂程度。
三种框架的术语名词不同,但是其代表的概念十分相似:

对比图
下面表格总结了一些不同之处:
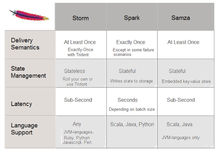
数据传递形式分为三大类:
最多一次(At-most-once):消息可能会丢失,这通常是最不理想的结果。
最少一次(At-least-once):消息可能会再次发送(没有丢失的情况,但是会产生冗余)。在许多用例中已经足够。
恰好一次(Exactly-once):每条消息都被发送过一次且仅仅一次(没有丢失,没有冗余)。这是最佳情况,尽管很难保证在所有用例中都实现。
另一个方面是状态管理:对状态的存储有不同的策略,Spark Streaming将数据写入分布式文件系统中(例如HDFS);Samza使用嵌入式键值存储;而在Storm中,或者将状态管理滚动至应用层面,或者使用更高层面的抽象Trident。3
流数据所面临的挑战
流数据处理需要两个层:存储层和处理层。存储层需要支持记录定序和高度一致性,以便以快速、便宜且可重复的方式读取和写入大型数据流。处理层负责处理存储层中的数据,基于该数据运行计算,然后通知存储层删除不再需要的数据。您还必须为存储层和处理层制定可扩展性、数据持久性和容错规划。因此,出现了可提供构建流数据应用程序所需的基础设施的多种平台。1

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国