

简介
和 积 算 法 (Sum-Product Algorithm) 作 为 一 种 通 用 的 消 息 传 递 算 法(Message Passing Algorithm),描述了因子图中顶点(变量节点和校验节点)处的信息计算公式,而在基于图的编译码系统中,我们首先需要理解的是顶点之间是如何通过边来传递信息。因子图是一种用于描述多变量函数的“二部图”(Bipartite Graph)。一般来说,在因子图中存在两类节点:变量节点和对应的函数节点,变量节点所代表的变量是函数节点的自变量。同类节点之间没有边直接相连。
置信传播,又名和-积信息传递,是一种在图模型上进行推断的消息传递算法,可用在贝叶斯网络和马尔科夫随机域中。置信传播由Pearl在1982年最早提出,1后来由早期在树上的建模推广至在polytree上的应用。
置信传播算法利用结点与结点之间相互传递信息而更新当前整个MRF(马尔科夫随机场)的标记状态,是基于MRF的一种近似计算。该算法是一种迭代的方法,可以解决概率图模型概率推断问题,而且所有信息的传播可以并行实现。经过多次迭代后,所有结点的信度不再发生变化,就称此时每一个结点的标记即为最优标记,MRF也达到了收敛状态。对于无环环路的MRF,BP算法可以收敛到其最优解。
BP算法的两个关键过程:(1)通过加权乘积计算所有的局部消息;(2)节点之间概率消息在随机场中的传递。2如果X = {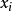 }是一组离散随机变量联合分布函数 p,单个变量X的边缘分布,只是p对所有其他变量的总和:
}是一组离散随机变量联合分布函数 p,单个变量X的边缘分布,只是p对所有其他变量的总和:
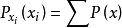 然而,这j计算量很快变得令人望而却步:如果有100个二进制变量,那么人们需要总结超过
然而,这j计算量很快变得令人望而却步:如果有100个二进制变量,那么人们需要总结超过
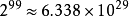
通过利用polytree结构,置信传播可以更有效地计算边缘。
贝叶斯网络与马尔科夫随机场贝叶斯网络贝叶斯网络(Bayesian network)是一种有效的不确定性知识表达和推理工具, 在数据挖掘等领域得到了较好的应用,又称信念网络(belief network)或是有向无环图模型(directed acyclic graphical model),是一种概率图型模型,借由有向无环图(directed acyclic graphs, or DAGs)中得知一组随机变量{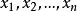 }及其n组条件概率分配(conditional probability distributions, or CPDs)的性质。一般而言,贝叶斯网络的有向无环图中的节点表示随机变量,它们可以是可观察到的变量,抑或是隐变量、未知参数等。连接两个节点的箭头代表此两个随机变量是具有因果关系或是非条件独立的;而两个节点间若没有箭头相互连接一起的情况就称其随机变量彼此间为条件独立。若两个节点间以一个单箭头连接在一起,表示其中一个节点是“因(parents)”,另一个是“果(descendants or children)”,两节点就会产生一个条件概率值。比方说,我们以表示第i个节点,而的“因”以表示,的“果”表示。
}及其n组条件概率分配(conditional probability distributions, or CPDs)的性质。一般而言,贝叶斯网络的有向无环图中的节点表示随机变量,它们可以是可观察到的变量,抑或是隐变量、未知参数等。连接两个节点的箭头代表此两个随机变量是具有因果关系或是非条件独立的;而两个节点间若没有箭头相互连接一起的情况就称其随机变量彼此间为条件独立。若两个节点间以一个单箭头连接在一起,表示其中一个节点是“因(parents)”,另一个是“果(descendants or children)”,两节点就会产生一个条件概率值。比方说,我们以表示第i个节点,而的“因”以表示,的“果”表示。
贝叶斯网络(Bayesian Network)定了一个独立的结构:一个节点的概率仅依赖于它的父节点。贝叶斯网络适用于稀疏模型,即大部分节点之间不存在任何直接的依赖关系。联合概率(Joint Probability),表示所有节点共同发生的概率,将所有条件概率相乘。缘概率(Marginal Probability):即某个事件发生的概率,而与其它事件无关。边缘概率是这样计算的:在联合概率中,把最终结果中不需要的那些事件合并成其事件的全概率而消失(在两个离散随机变量的条件下,对于其中任一行或任一列求和,得到的概率就是边缘概率)。
马尔可夫随机场马尔可夫网络,(马尔可夫随机场、无向图模型)是关于一组有马尔可夫性质随机变量 X的全联合概率分布模型。3
马尔可夫网络类似贝叶斯网络用于表示依赖关系。但是,一方面它可以表示贝叶斯网络无法表示的一些依赖关系,如循环依赖;另一方面,它不能表示贝叶斯网络能够表示的某些关系,如推导关系。马尔可夫网络的原型是易辛模型,最初是用来说明该模型的基本假设。
BP的变形算法基于图模型的 Beyond-BP 译码算法BP算法是一种基于树型结构提出的渐进边缘概率计算方法,它要求不同节点之间传递的外信息相互独立。但是对于有限长LDPC码而言,与其对应的Tanner 图中必然会有环形结构的出现,这样当外信息在环形结构上经过多次传递后,它们之间将必然产生联系,从而会导致错误信息的传递与叠加,进而导致 BP 算法的译码失败。而错误信息累加现象在存在较多短环时,会表现得更加明显。综上所述, BP 译码算法的译码性能较 ML 算法相比存在差距,且该差距将随着 LDPC 码码长的降低而增大。因此,为了降低 BP 算法所带来的负面作用,一方面可以借助于码型构造算法来减少短环出现的数量;另一方面则可以借助于加权 BP 算法来抑制错误信息的叠加。
基于环形结构的加权BP算法有些学者首先就置信信息累加现象进行了研究,并提出了一种树型加权 BP(Tree ReWeighted BP, TRW-BP)算法,来加强 BP 译码算法的纠错能力。此算法的核心思想是通过计算 Tanner 图上成对节点间的边在扩展树上出现的概率(Edge Appearance Probabilities,EAPs),并将运算结果作为加权值作用于 LLR 值的更新操作中。但 EAPs 的计算实质上是一个多维优化问题,本身具有相当高的计算复杂度。因此为避免 EAPs的计算, 归一化加权 BP(Uniformly ReWeighted BP,URW-BP)算法被学者们所提出。
具有快收敛特性的 Beyond-BP 算法传统的LDPC码BP译码算法是分为两步进行:首先进行全部变量点外信息的更新,然后再进行全部校验点外信息的更新。而这种两步译码更新方法也被称为扩散更新策略。研究表明,迭代过程中节点的更新策略的改变将能有效地提高译码算法的收敛特性。比如提出的便于硬件实现的分层 BP(Layer BP, LBP)译码算法。实验结果表明,LBP 算法收敛速度是传统 BP算法的两倍。与 BP算法一样,LBP 算法中节点的更新顺序是固定的,但研究进一步指出,如果动态安排节点的更新顺序,更能够进一步地提高译码算法的收敛速度。基于残余量的 BP(Residual BP, RBP)算法正是此类算法的代表。4
循环置信传播这里,我们考虑带有环的图中的近似推断的一个简单方法,它直接依赖于之前对树的精确推 断的讨论。主要思想就是简单地应用加-乘算法,即使不保证能够产生好的结果。这种方法被称为循环置信传播(loopy belief propagation)(Frey and MacKay,1998)。这种方法是可行的,因为加和-乘积算法的信息传递规则完全是局部的。然而,由于现在图中存在环,因此信息会绕着图流动多次。对于某些模型,算法会收敛,而对于其他模型则不会。
为了应用这种方法,我们需要定义一个信息传递时间表(message passing schedule)。让我们假设在任意给定的链接以及任意给定的方向上,每次传递一条信息。从一个结点发送的每条信息替换了之前发送的任何沿着同一链接的同一方向的信息,并且本身是一个函数,这个函数只与算法的前一步的结点接收到的最近的信息有关。
我们已经看到,只有当结点从所有其他的链接接收到所有其他的信息之后,它才会沿着一条链接发送信息。由于图中存在环,因此这就产生了如何初始化信息传递算法的问题。为了解决这个问题,我们假设由单位函数给出的初始信息已经在所有方向上通过了每个链接。这样,每 个结点都处在了发送信息的位置上。
现在有许多可能的方法来组织信息传递时间表。例如,洪水时间表(flooding schedule)在每一步同时向两个方向沿着每条链接同时传递信息,而每次只传递一个信息的时间表被称为连 续时间表(serial schedule)。
根据Kschischnang et al.(2001),对于结点(变量结点或因子结点) aa 和结点 bb ,如果 aa 自从上次向 bb 发送信息后,从任何其他的链接接收到了任何信息,那么我们说结点 aa 在到结点 bb 的链接上有一个信息挂起(pending)。因此,当一个结点接收到了它的一个链接发送的信息,就在所有其他的链接上产生了挂起的信息。只有挂起的信息需要被传送,因为其他的信息仅仅复制了同样链接上的前一条信息。对于具有树结构的图来说,任何只发送挂起信息的时间表最后会终止于一条在任意方向上沿着任意链接发送过的信息。此时,没有挂起信息,并且每个变量接收到的信息给出了精确的边缘概率分布。然而,在具有环的图中,算法永远不会终结,因为总可能存在挂起信息,虽然在实际应用中发现,对于大部分应用,它都会在一个合理的时间内收敛。一旦算法收敛,或者如果未观测到收敛时算法停止,那么(近似)局部边缘概率分布可以使用每条链接上的每个变量结点或因子结点最近接收到的输入信息的乘积进行计算。 +
在一些应用中,循环置信传播算法会给出很差的结果,而在其他应用中,它被证明非常有效。特别地,对特定类型的误差修正编码的最好的解码算法等价于循环置信传播算法(Gallager, 1963; Berrou et al., 1993; McEliece et al., 1998; MacKay and Neal, 1999; Frey, 1998)。
应用针对 SIF特征点匹配错误问题:提出一种置信传播与特征点形状特征相结合去除 SIFT 特征点匹配错误的算法. 该算法分为 4 步:1) 根据每个特征点的尺度信息、主方向信息以及匹配邻居特征点信息确定每个特征点邻域窗口的大小和方向,并计算每个特征点在邻域窗口内匹配邻居构成的形状特征;
2) 连接每个特征点与其最近的 3个邻居特征点,构成置信传播网的基本框架;
3)利用每对待确定特征点对的特征描述符之间的距离与其形状特征之间的距离生成置信传播网的证据函数,用每对待确定特征点对与其邻居之间的空间关系生成置信传播网的相容函数;
4) 迭代计算每个特征点的置信度以及传递给邻居的消息,至整个网络收敛,过最后得到的置信度确定初始匹配特征点对是否为误配。用真实拍摄的图像和牛津几何视觉组数据库中的图像进行仿真实验,与 RANSAC 算法、GTM 算法以及 BP_SIFT 算法进行了比较, 仿真结果表明, 在召回率、准确率、丢失率和效率上都不错。5

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国