

简介目的
数据已成为信息时代的重要资源,数据被采集后在企业之间或企业内部的信息系统中共享,数据量的增加导致高效的基于计算机的分析方法的出现,如智能数据分析,它是指运用统计学、模式识别、机器学习、数据抽象等数据分析工具从数据中发现知识的分析方法。
智能数据分析的目的是直接或间接地提高工作效率,在实际使用中充当智能化助手的角色,使工作人员在恰当的时间拥有恰当的信息, 帮助他们在有限的时间内作出正确的决定。信息系统中积累的大量数据,其原始数据的价值很小,只有通过智能化分析方法抽取其中的精华,才能转变为信息"金矿",为人类造福。1
历史智能数据分析方法研究已经有数十年的历史,研究人员将人工神经网络、贝叶斯网络、决策树、遗传算法,基于范例的推理法、归纳逻辑编程法等智能数据分析方法应用到具体工作中。先后取得了很大的突破!解决了许多疑难问题。1
类型智能数据分析方法主要为两种类型,一是数据抽象(Data Abstraction ),主要涉及数据的智能化解释,以及如何将这种解释以可视化或符号化的形式表示出来;二是数据挖掘(Date Mining),主要涉及从数据中分析和抽取知识,目的是为了支持业务管理或预测趋势。1
常见方法比较当前世界依然迎来了大数据时代, 随着多媒体等多种技效。术的应用, 社会中的相关领域时刻都涌现大量的数据,增加了大数据背景下的智能数据分析技术了技术处理以及分析的难度。通常情况下大数据具有复杂性,而且还具有数量大、分布式的特点, 这样就必须要采取新的技术方法对数据进行处理, 因此智能分析技术在数据的处理数据中具有非常重要的意义。2
决策树虽然在大数据时代传统的智能数据分析法已经不能适应当前的需求, 但是依然有一定的相似性, 相关理论和技术依然可以沿用, 几种常见数据分析法: 第一种方法是决策树。这种数据分析方法需要基于信息论基础上, 这种方法实现的输出结果容易理解,精确度较高, 效率也较快, 但是它不能用来对复杂的数据进行处理与分析。2
决策树(Decision Tree)是在已知各种情况发生概率的基础上, 通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险, 判断其可行性的决策分析方法,是直观运用概率分析的一种图解法,它是建立在信息论基础之上对数据进行分类的一种方法。首先通过一批已知的训练数据建立一棵决策树, 然后采用建好的决策树对数据进行预测。决策树的建立过程是数据规则的生成过程,因此,这种方法实现了数据规则的可视化, 其输出结果容易理解, 精确度较好, 效率较高, 缺点是难于处理关系复杂的数据。常用的方法有分类及回归树法、双方自动交互探测法等。其中分类树主要用于数据记录的标记和归类,回归树主要用于估计目标变量的数值3。
关联规则第二种方法是关联规则。这种方法主要是用于事物数据库中,通常带有大量的数据,当今使用这种方法来削减搜索空间。4
关联规则分析发现大量数据中项集之间有价值的关联或相关联系, 就是要建立形如X → Y 的蕴涵式, 其中X 和Y 分别称为关联规则的先导(antecedent) 和后继(consequent)。关联规则一般应用在事物数据库中, 其中每个事物都由一个记录集合组成。这种事物数据库通常都包括极为庞大的数据,因此,当前的关联规则发现技巧正努力根据基于一定考虑的记录支持度来削减搜索空间。关联规则的常见算法有Apriori算法、基于划分的算法、FP-树频集算法等。5
粗糙集第三种方法是粗糙集。够更好的支持大数据这种数据分析方法能够对数据进行主观评价, 只要通过观测数据, 就可以清除冗余的信息。4
粗糙集智能数据分析是粗糙集理论中的主要应用技术之一, 是一种基于规则的数据分析的方法。其思想主要来自统计学和机器学习, 但并不是这两种工具随意的应用,它以粗糙集理论为基础,以数据表所表示的信息系统为载体, 通过分析给定数据集的性质、粗糙分类、决策规则的确定性以及覆盖度因子等过程,从中获取隐含的、潜在有用的知识。
用粗糙集理论进行数据分析主要有以下优势: 它无需提供对知识或数据的主观评价, 仅根据观测数据就能达到删除冗余信息;非常适合并行计算、提供结果的直接解释。5
模糊数学分析第四种方法是模糊数学分析。这种数据分析方法能够对实际问题进行模糊的分析, 与其他的分析方法相比, 能够取得更为客观的效果。4
用模糊(Fuzzy sets)数学理论来进行智能数据分析。现实世界中客观事物之间通常具有某种不确定性。越复杂的系统其精确性越低,也就意味着模糊性越强。在数据分析过程中, 利用模糊集方法对实际问题进行模糊评判、模糊决策、模糊预测、模糊模式识别和模糊聚类分析, 这样能够取得更好更客观的效果。
模糊分析方法不足主要表现在: 用户驱动, 用户参与过多; 处理变量单一,不能处理定性变量和复杂数据, 如非线性数据和多媒体数据; 发现的事实或规则是以查询为主要目的,对预测和决策影响不大,而且过分依赖主观的经验。4
人工神经网络第五种方法是人工神经网络。这种数据分析方法具有自学习功能, 在此基础上还具有联想存储的功能。4
人工神经网络是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。该模型由大量的节点(或称神经元)之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数(activationfunction)。每两个节点间的连接都代表一个对于通过该连接信号的加权值, 称之为权重,这相当于人工神经网络的记忆。网络的输出则依网络的连接方式, 权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近, 也可能是对一种逻辑策略的表达。
典型的神经网络模型主要分三大类,即前馈式神经网络模型, 反馈式神经网络模型,自组织映射方法模型。人工神经网络具有非线性、非局限性、非常定性、非凸性等特点, 它的优点有三个方面: 第一,具有自学习功能。第二, 具有联想存储功能。第三,具有高速寻找优化解的能力。5
混沌分型理论第六种方法是混沌和分形理论。这两种理论主要是用来对自然社会中存在的现象进行解释, 一般用来进行智能认知研究, 还能应用于自动控制等众多领域中。4
混沌(Chaos)和分形(Fractal)理论是非线性科学中的两个重要概念, 研究非线性系统内部的确定性与随机性之间的关系。混沌描述的是非线性动力系统具有的一种不稳定且轨迹局限于有限区域但永不重复的运动, 分形解释的是那些表面看上去杂乱无章、变幻莫测而实质上潜在有某种内在规律性的对象,因此,二者可以用来解释自然界以及社会科学中存在的许多普遍现象。其理论方法可以作为智能认知研究、图形图像处理、自动控制以及经济管理等诸多领域应用的基础。5
自然计算分析第七种方法是自然计算分析方法。这种数据分析方法根据不同生物层面的模拟与仿真, 通常可以分为以下三种不同类型的分析方法: 一是群体智能算法, 二是免疫算术方法, 三是DNA算法。群体智能主要是对集体行为进行研究,免疫算法具有多样性, 经典的主要有反向、克隆选择等,DNA 算法主要使属于随机化搜索方法, 它可以进行全局寻优,在实际的运用中一般都能获取优化的搜索空间,在此基础上还能自动调整搜索方向,在整个过程中都不需要确定的规则,当前DNA算法普遍应用于多种行业中, 并取得了不错的成效。4
自然计算分析方法自然计算是指受自然界中生物体的启发,模拟或仿真实现发生在自然界中、易作为计算过程解释的动态过程。针对不同生层面的模拟与仿真,有群体智能算法、免疫算法、D N A 算法等。
群体智能(Swarm Intelligence,SI)是一种模仿自然界动物昆虫觅食筑巢行为的新兴演化计算技术, 研究的是由若干简单个体组成的分散系统的集体行为, 每个个体与其他个体以及环境都有相互作用。目前主要的SI算法有粒子群优化算法(ParticleSwarm Optimization,PSO),蚁群算法(AntColony Optimization,ACO),文化算法(Culture Algorithm),人工鱼群算法(Artificial Fish Swarm Optimization,AFSO)以及觅食算法(Foraging Algorithm),其中PSO和ACO受到了人们广泛的关注。人工免疫系统(Artificial ImmuneSystem,AIS)是从脊椎动物免疫系统中获取灵感构建的计算系统。人工免疫(亦称计算机免疫)学借鉴生物免疫的思想,以典型的多样性、适应性、自治性、动态覆盖性、动态平衡性等特性, 求解某些特定复杂问题具有较好的效果。
经典免疫算法有反向选择、克隆选择、免疫网络、危险理论等。
遗传算法(Genetic Algorithm)是一类借鉴生物界的进化规律(适者生存,优胜劣汰遗传机制)演化而来的随机化搜索方法。它是由美国的J.Holland教授1975年首先提出, 其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法, 能自动获取和指导优化的搜索空间,自适应地调整搜索方向,不需要确定的规则。遗传算法的这些性质,已被人们广泛地应用于组合优化、机器学习、信号处理、自适应控制和人工生命等领域。5
大数据下的IDA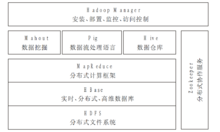 大数据由于其独特的特性决定了对其进行智能分析的技术必须有新的发展的进步, 才能胜任在如此庞大的数据中进行智能分析。有学者指出大数据的智能分析技术有望成为人工智能的解决之道, 目前有很多企业和科研人员提出了很多新的智能分析技术方案。如惠普推出基于HAVEn大数据分析平台、Teradata天睿公司推出的Teradata Aster大数据探索平台(TeradataAster Discovery Platform)以及IBM公司和Intel公司都推出了他们各自的大数据分析方案。这些方案都涉及Hadoop这个大数据分析平台。
大数据由于其独特的特性决定了对其进行智能分析的技术必须有新的发展的进步, 才能胜任在如此庞大的数据中进行智能分析。有学者指出大数据的智能分析技术有望成为人工智能的解决之道, 目前有很多企业和科研人员提出了很多新的智能分析技术方案。如惠普推出基于HAVEn大数据分析平台、Teradata天睿公司推出的Teradata Aster大数据探索平台(TeradataAster Discovery Platform)以及IBM公司和Intel公司都推出了他们各自的大数据分析方案。这些方案都涉及Hadoop这个大数据分析平台。
Hadoop是Appach基金会支持的一个开源系统, 包括两部分, 一是分布文件系统、二是分布计算系统。Hadoop在HBase上还提供了一个数据仓库/数据挖掘软件Hivi。面向机器学习,还提供了一个机器学习软件包Mahout,从而满足大数据管理和分析的要求。5
一方面, 大数据分析相比传统的数据分析,具有数据量大、查询分析复杂等特点, 因而需要有新的大数据分析方法和理论的出现。一方面人们发现现有的单一智能数据分析方法已经不能全面、高效地胜任数据分析的工作,由此一种趋势是交叉融合多种智能数据分析技术的方法和技术应运而生。如模糊数学和其他理论融合形成了模糊人工神经网络、模糊遗传算法、模糊进化算法、模糊计算学习理论;演化计算和其他理论融合渗透形成了模糊演化算法、演化人工神经网络等。另一方面大数据的智能分析技术的发展还有赖于新型的数据存储和组织技术以及新的高效率的计算方法的支持。数据存储和组织技术应该采用的更好的分布式的数据存储策略, 并尽量提高数据的吞吐效率、降低故障率。如谷歌公司的GFS和Hadoop项目的HDFS是两个最知名的分布式文件系统, 他们都采用比较新颖的策略。高效率的计算方法有分布式运算、数据流技术、新硬件技术等。6

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国