

并行数据库技术起源于20世纪70年代的数据库机(Database Machine)研究,研究的内容主要集中在关系代数操作的并行化和实现关系操作的专用硬件设计上,希望通过硬件实现关系数据库操作的某些功能,该研究以失败而告终。80年代后期,并行数据库技术的研究方向逐步转到了通用并行机方面,研究的重点是并行数据库的物理组织、操作算法、优化和调度策略。从90年代至今,随着处理器、存储、网络等相关基础技术的发展,并行数据库技术的研究上升到一个新的水平,研究的重点也转移到数据操作的时间并行性和空间并行性上。
PDB硬件结构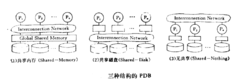 PDB的硬件结构一般分为三类:共享内存(Shared-Memory,简称SM)、共享磁盘(Shared-Disk,简称SD)、无共享(Shared-Nothing,简称SN),如图所示1。
PDB的硬件结构一般分为三类:共享内存(Shared-Memory,简称SM)、共享磁盘(Shared-Disk,简称SD)、无共享(Shared-Nothing,简称SN),如图所示1。
SM结构又可称为完全共享型(Share-Eveyrtihng),所有处理机存取一公共全局内存和所有磁盘,如IBM/370、VAX是其代表。
SD结构中每个处理机有自己的私有内存,但能访问所有磁盘,IBM的yS:plex和早期的VAx簇是其代表。
SN结构中所有磁盘和内存分散给各处理机,每个处理机只能直接访问其私有内存和磁盘,各自都是一个独立的整体,处理机间由一公共互连网络连接,Teradata的DBC/1012、Tandem的Nonstop SQL是典型代表。
对这三种结构,长期以来人们争论不休,直到近期才逐渐趋于一致,普遍认为PDB越来越趋向于Shared-Nothing的结构。这是因为在这样的系统结构下,可望在复杂DB的查询和联机执程处理上达到线性加速比(Speedup)和伸缩比(Scaleup)。所谓加速比是指一定规模的任务在小规模系统和大规模系统上运行的时间之比,即:
加速比 = 小规模系统上运行时间 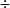 大规模系统上运行时间
大规模系统上运行时间
如果系统规模扩大了N倍,例如结点数增加了N倍后,加速比等于N,则称作线性加速比。伸缩比是任务在小规模系统上运行时间与扩大N倍的任务在扩大N倍的系统上运行时间之比,即:
伸缩比 = 小任务在小系统上运行时间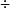 大任务在小系统上运行时间
大任务在小系统上运行时间
如果伸缩比等于1,则称作线性伸缩比。
实际上影响接近线性加速比和线性伸缩比的主要因素有三个:启动时间(这是启动所有结点进行并行操作所必需的时间)、冲突(当多个结点竞争资源时所必需的等待时间)、负载不均(由于一个任务分成多个子任务并行执行,任务的处理时间应该是最慢的那个子任务的处理时间)。对于启动时间与负载不均是三种结构的PDB所共同面临的,而对于冲突,因为SN结构的处理机间没有共享资源,因此没有冲突或冲突最小,系统规模的扩充与缩小只涉及结点的人网与出网,可伸缩性较好,从而容易适应不同应用的需要,这就是为什么今天较为成功的PDB都是SN结构的原因。
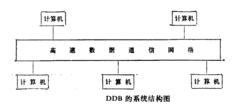 熟悉分布式数据库(DDB)的人们也许会觉得SN结构的PDB与DDB的硬件结构非常相似,因为DDB的硬件结构也是由网络连接若干台计算机而组成(见图)。的确,物理上它们是十分相似的。但逻辑上PDB系统中的N个结点并不平等。其中只有一个结点与用户接口,接受用户请求.输出处理结果,制定执行方案,而其余结点只具有执行操作和彼此之间的通信能力,但不具备与用户的交互能力。换句话说,PDB在逻辑上往往是有一个前台处理机和多个后台处理机结点模型的系统(图)。我们把前台结点称主结点,后台结点称从结点,物理上主结点和从结点可以在一个物理结点上。而系统中的个结点从逻辑上讲完全是平等的,他们没有主次之分,即没有控制整个系统的主机,也没有受控于它机的从机。因此,主从控制计算机系统或分级控制计算机系统不是分布式系统`月’。由此可见,基于SN结构的PDB与DDB在系统的逻辑结构上是完全不同的
熟悉分布式数据库(DDB)的人们也许会觉得SN结构的PDB与DDB的硬件结构非常相似,因为DDB的硬件结构也是由网络连接若干台计算机而组成(见图)。的确,物理上它们是十分相似的。但逻辑上PDB系统中的N个结点并不平等。其中只有一个结点与用户接口,接受用户请求.输出处理结果,制定执行方案,而其余结点只具有执行操作和彼此之间的通信能力,但不具备与用户的交互能力。换句话说,PDB在逻辑上往往是有一个前台处理机和多个后台处理机结点模型的系统(图)。我们把前台结点称主结点,后台结点称从结点,物理上主结点和从结点可以在一个物理结点上。而系统中的个结点从逻辑上讲完全是平等的,他们没有主次之分,即没有控制整个系统的主机,也没有受控于它机的从机。因此,主从控制计算机系统或分级控制计算机系统不是分布式系统`月’。由此可见,基于SN结构的PDB与DDB在系统的逻辑结构上是完全不同的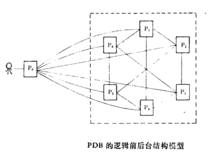 。
。
并行数据库系统的目标是高性能(High Performance)和高可用性(High Availability),通过多个处理节点并行执行数据库任务,提高整个数据库系统的性能和可用性。
性能指标关注的是并行数据库系统的处理能力,具体的表现可以统一总结为数据库系统处理事务的响应时间。并行数据库系统的高性能可以从两个方面理解,一个是速度提升(SpeedUp),一个是范围提升(ScaleUp)。速度提升是指,通过并行处理,可以使用更少的时间完成两样多的数据库事务。范围提升是指,通过并行处理,在相同的处理时间内,可以完成更多的数据库事务。并行数据库系统基于多处理节点的物理结构,将数据库管理技术与并行处理技术有机结合,来实现系统的高性能。
可用性指标关注的是并行数据库系统的健壮性,也就是当并行处理节点中的一个节点或多个节点部分失效或完全失效时,整个系统对外持续响应的能力。高可用性可以同时在硬件和软件两个方面提供保障。在硬件方面,通过冗余的处理节点、存储设备、网络链路等硬件措施,可以保证当系统中某节点部分或完全失效时,其它的硬件设备可以接手其处理,对外提供持续服务。在软件方面,通过状态监控与跟踪、互相备份、日志等技术手段,可以保证当前系统中某节点部分或完全失效时,由它所进行的处理或由它所掌控的资源可以无损失或基本无损失地转移到其它节点,并由其它节点继续对外提供服务。
为了实现和保证高性能和高可用性,可扩充性也成为并行数据库系统的一个重要指标。可扩充性是指,并行数据库系统通过增加处理节点或者硬件资源(处理器、内存等),使其可以平滑地或线性地扩展其整体处理能力的特性。
随着对并行计算技术研究的深入和SMP、MPP等处理机技术的发展,并行数据库的研究也进入了一个新的领域,集群已经成为了并行数据库系统中最受关注的热点。目前,并行数据库领域主要还有下列问题需要进一步地研究和解决。
(1)并行体系结构及其应用,这是并行数据库系统的基础问题。为了达到并行处理的目的,参与并行处理的各个处理节点之间是否要共享资源、共享哪些资源、需要多大程度的共享,这些就需要研究并行处理的体系结构及有关实现技术。
(2)并行数据库的物理设计,主要是在并行处理的环境下,数据分布的算法的研究、数据库设计工具与管理工具的研究。
(3)处理节点间通讯机制的研究。为了实现并行数据库的高性能,并行处理节点要最大程度地协同处理数据库事务,因此,节点间必不可少地存在通讯问题,如何支持大量节点之间消息和数据的高效通讯,也成为了并行数据库系统中一个重要的研究课题。
(4)并行操作算法,为提高并行处理的效率,需要在数据分布算法研究的基础上,深入研究联接、聚集、统计、排序等具体的数据操作在多节点上的并行操作算法。
(5)并行操作的优化和同步,为获得高性能,如何将一个数据库处理事务合理地分解成相对独立的并行操作步骤、如何将这些步骤以最优的方式在多个处理节点间进行分配、如何在多个处理节点的同一个步骤和不同步骤之间进行消息和数据的同步,这些问题都值得深入研究。
(6)并行数据库中数据的加载和再组织技术,为了保证高性能和高可用性,并行数据库系统中的处理节点可能需要进行扩充(或者调整),这就需要考虑如何对原有数据进行卸载、加载,以及如何合理地在各个节点是重新组织数据。


 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国