

OpenAI首席科学家透露GPT4技术原理
本周可以说是人工通用智能(AGI)周,GPT4横空出世,文心的内测,还有微软刚刚发布的GPT4 Office全家桶, 可以说开启了AGI新纪元。这一代人是幸运的,亲自见证了徐徐拉开大幕的新的信息工业革命。
GPT4发布的同时提供了万众期待的技术报告,然而非常遗憾,官方以竞争和安全为由,只让大家知其然,不讲所以然。不过有趣的是,从克雷格·史密斯(《纽约时报》的前记者)与OpenAI联合创始人和首席科学家Ilya SutskeverIlya最近的一场公开访谈讨论中,我们可以窥见GPT3/4的技术端倪。
另一方面,基于笔者对GPT3/4其智能原理的推演 (详见:“ChatGPT是第一个真正意义的人工通用智能”),与Ilya SutskeverIlya的只言片语做一一对照分析,可以看到笔者的技术原理推演与Ilya SutskeverIlya的表述完全吻合。这也坚定了笔者继续整理系列介绍(“系列文章深度解析ChatGPT获得智能的数学物理机理”)的信心。以下是对照:
Ilya :我们只需要使用一个更小但与之类似的神经网络,并使用数据对其进行训练。然后,计算机内部最好的神经网将与我们的大脑中执行这个任务的神经网络非常类似。
Ilya :从OpenAI的最早时期开始,我们就一直在探索一个想法:(机器学习)只需要能够预测下一个事物。
Ilya :如果有一个神经网络能够预测下一个单词,它就能解决无监督学习问题。因此,在GPT诞生之前,无监督学习被认为是机器学习的圣杯。
Ilya :当Transformer的概念问世后,那篇论文一出来,真的是就在它出来的第二天,我们立即意识到Transformer解决了递归神经网络的局限性,解决了学习长期依赖性的问题。
QF:ChatGPT的训练方法是基于Transformer模型,通过学习文本数据的模式来生成文本。Transformer模型的核心是注意力机制,可以在生成文本时,选择性地关注输入的一些部分,从而生成更加符合上下文的文本。
Ilya :我认为学习统计规律比我们想象的更重要。
Ilya :预测也是一种统计现象。然而,为了进行预测,你需要了解产生数据的基本过程。你需要对产生数据的世界有越来越多的了解。
Ilya :我认为随着我们的生成式模型变得异常优秀,它们将具有我所说的对世界和其许多微妙之处的惊人程度的理解。它是通过文本的角度来看待世界的。它试图通过人类在互联网上所表达的文本空间上的世界投影来更多地了解世界。
QF:GPT在自己构造的高维语言空间中,通过预训练,记录了人类海量的语言实例,从中提取了无数的结构与关联信息。这个高维的语言空间,加上训练提取的结构与关联信息,可以理解构成了GPT的脑。
QF: 本质上看,GPT 其实是构建了一个高维的语言体系,可以将自然语言,程序语言,视觉听觉语言,映射(或者叫编码)到这个高维的语言空间中。高维语言空间是概率分布张成的空间。
Ilya :这些神经网络有产生幻觉的倾向。这是因为语言模型非常适合学习有关世界的知识,但不太适合产生好的输出。
Ilya :可以说,在预训练过程中,我们想(让它)学习的是关于这个世界的一切。但通过人类反馈的强化学习,我们关心的是它的输出。
Ilya :多模态理解确实是可取的" ,“我认为有些东西从图像和图表等方面更容易学习,但我也认为,你仍然可以只从文字中学习,只是速度更慢。
QF: 人们发现,增加多任务的任务数量,增加模型大小,提供思维链提示, 以及增加任务的多样性,都可以提高GPT泛化能力,包括理解能力,以及推理能力。这些措施都是丰富GPT在某一问题域的信息量,降低其信息熵, 尽力让他见多识广。
QF: 代码使用计算机语言,是设计完善的特殊语种,结构性强,长程关联,关系明确。可以用微语言结构的概率分布为基底,张成语言空间,程序就是该语言结构空间的点线面体。GPT可以用自己构建的高维语言空间简单方便的学习代码。
Ilya :每个神经网络通过“Embedding”表示法,即高维向量,来代表单词、句子和概念。
Ilya :我们可以看一下这些高维向量,看看什么与什么相似,以及网络是如何看待这个概念或那个概念的?因此,只需要查看颜色的Embedding向量,机器就会知道紫色比红色更接近蓝色,以及红色比紫色更接近橙色。它只是通过文本就能知道所有这些东西。
Ilya :其中一个主要挑战是预测具有不确定性的高维向量。那就是目前的自回归Transformer已经具备了这种特性。
Ilya :一个是对于给定一本书中任意的一页,预测其下一页的内容。下一页有非常多的可能性。这是一个非常复杂的高维空间,而它们可以很好地处理它。同样的情况也适用于图像。这些自回归Tranformer在图像上也运作得非常完美。
QF:借助Embedding ,GPT 将人类的语言 “编码”成自己的语言,然后通过注意力Attention从中提取各种丰富的知识和结构,加权积累与关联生成自己的语言,然后“编码”回人类的语言。QF:本质上看,GPT 其实是构建了一个高维的语言体系,可以将自然语言,程序语言,视觉听觉语言,映射(或者叫编码)到这个高维的语言空间中。高维语言空间是概率分布张成的空间。
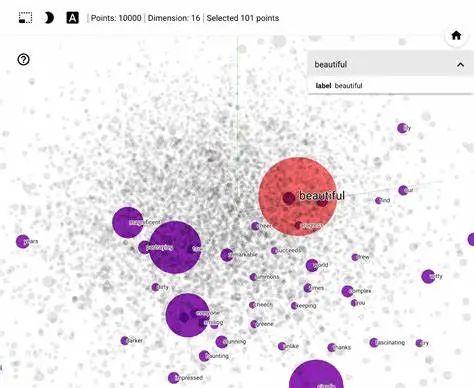
Ilya :我认为那篇论文(Yann LeCun)中对当前方法无法处理高维分布的评论过于绝对了——我认为它们绝对可以。
Ilya :我认为我们的预训练模型已经知道了它们需要了解的关于基础现实的一切。它们已经具备了有关语言的知识以及有关产生这种语言的世界进程的大量知识。
Ilya :大型生成模型对其数据——在这种情况下是大型语言模型——所学习的东西是对产生这些数据的现实世界过程的压缩表示。
QF:从GPT目前的表现看,他应该也已经从这些人类语言蕴含的知识中,学习到了归纳、演绎、对比、类比等基础能力,而这些都是本质的原子思维能力,组合成为推理能力。诸如贝叶斯推理,最优输运,估计都可能已经被提取出来,成为GPT的思维结构的一部分。
Ilya:有这些人类教师在向模型教授它们的理想行为。而他们使用人工智能系统的方式不断增加,因此他们自己的效率也在不断提高。这和教育过程没什么两样,那就是让教育对象知道如何在这个世界上表现得好。
QF:研究表明,增加训练数据量,模型参数量,训练时间都会降低测试集上的信息熵. OpenAI 采用的策略是同时增加训练数据量和模型参数, 读得多,记得多。优先增加模型参数,然后才是训练数据量,记忆要好,再多学,再勤学, 与人类学习形式相通。
Ilya:展现出超越行业权威的认知高度,这应该是GPT智能突破的关键因素之一。可惜这个访谈时间不长,谈论的问题不够深入。Ilya没有涉及到Emergent Ability涌现能力的机理。这个却是ChatGPT/GPT4的魅力所在。也正是这一点,让GPT跨过了智障到智能的门槛,完成量变到质变的重大突破。这是笔者的推演:
QF:GPT 构建了海量自然语言和代码的概率分布空间,被注入足够的信息量(等于注入大量负的信息熵),形成各种复杂关联的模式,涵盖自然语言和代码中各种知识与结构。这些知识和结构,体现为概率分布的距离与关系,从而为对比、类比、归纳、演绎等推理步骤提供支撑,也就是“涌现出”这些推理能力。
这个推演尚未获得OpenAI 内部的反馈,但从OpenAI GPT4 技术报告引用的文献中,可以看到相当大的关联和指向。炼丹有成功的偶然性,也有必然性,对原理的认知至关重要。认识到原理就理解其中的必然性,可以明确指导炼丹努力的方向。GPT4代表着这个时代最先进的生产力,OpenAI已经掌握。其他公司必须急起直追,生产力落后意味着什么,大家都懂。
大语言模型构建的压缩版世界的高维的概率空间,像极了量子比特的“那个测不准的、叠加的由本征态与概率支撑起来的世界”。大胆预言一下,未来20年,GPT与量子计算的融合,会催生更强大、更快速、更智慧的物种。笔者将继续整理系列介绍(“系列文章深度解析ChatGPT获得智能的数学物理机理”),同时也呼吁OpenAI 更开放,至少公开相应的技术论文,超越民族与国界,助推这一划时代的人类科技进步来的更猛烈些。



 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国